 Página anterior Página anterior | Voltar ao início do trabalho | Página seguinte  |
SMP – Symmetric Multiprocessor
SSH – Secure Shell
SSI – Single System Image
TCP/IP – Transmission Controle Protocol/Internet Protocol
VLSI – Very Large Scale Integration
OBJETIVOS
Geral
Implementar um cluster de computadores para a realização de testes de renderização de imagens, comparando os resultados com os obtidos em testes idênticos realizados em um único computador uniprocessado, visando assim, avaliar a performance dessa técnica de processamento em clusters computacionais.
Específicos
Conceituar arquiteturas computacionais, aplicações com grande demanda de processamento, computação paralela e distribuída;
Estudar conceitos sobre cluster de computadores;
Implementar um cluster de computadores, para a realização dos testes;
Realizar testes comparativos;
Apresentar resultados.
JUSTIFICATIVA
Com a crescente necessidade de alto poder de processamento para a realização de grandes quantidades de cálculos, renderização de imagens e animações no menor tempo possível, o uso de cluster de computadores, para a realização de processamento distribuído, tem se tornado a melhor opção para os casos em que se busca um bom equilíbrio entre custo e benefício.
Para a montagem de um cluster Beowulf, não há necessidade de grandes investimentos, pois basta utilizar-se de computadores comuns de qualquer ambiente, conectados em rede, para que o processamento paralelo/distribuído possa ser realizado.
O fato de usar o Linux como sistema operacional e diversas ferramentas e bibliotecas, todas de livre uso, torna ainda menores os custos de investimento.
A utilização de cluster como solução para computação de alto desempenho é uma realidade. Utilizando os equipamentos já existentes na atualidade e produtos gratuitos, esta tecnologia pode ser utilizada em cursos universitários na formação de profissionais de Tecnologia da informação e ainda como ferramenta de apoio às pesquisas em outras áreas como biologia, química, física e diversas outras, integrando cada vez mais os diversos segmentos da sociedade. (PITANGA, 2003)
METODOLOGIA
As principais etapas a serem seguidas para a conclusão do estudo serão:
Pesquisas bibliográficas sobre conceitos de redes de dados, aplicações com grande demanda de processamento, computação paralela e distribuída;
Pesquisas bibliográficas sobre cluster de computadores;
Implementação de um cluster Beowulf para a realização dos testes e análises;
Realização dos testes e análises;
Elaboração das conclusões.
Primeiramente serão pesquisados os conceitos básicos em que o projeto será embasado. Depois será feito um estudo sobre clusters de computadores, focando mais no cluster Beowulf, bem como sua implementação, usando-se de componentes e ferramentas básicas necessárias para isso.
Com o cluster em funcionamento, serão realizados diversos testes de renderização de uma imagem em Pov-Ray nesse agregado de computadores, verificando o desempenho com uma quantidade inicial de dois nós e depois aumentando esse número gradativamente (de acordo com a disponibilidade de computadores para o teste) para verificar como se comportará a mudança de performance. Os resultados obtidos também serão comparados aos resultados provindos dos mesmos testes realizados em um único computador uniprocessado, separado do cluster.
Por final, serão apresentadas algumas análises dos resultados obtidos nos testes e as devidas conclusões, verificando assim, as vantagens e desvantagens bem como a viabilidade da aplicação de cluster de computadores na renderização de imagens.
ESTRUTURA DO TRABALHO
No capítulo 2, serão abordados conceitos básicos sobre arquiteturas computacionais;
No capítulo 3, serão abordados conceitos sobre clusters de computadores;
No capítulo 4, serão abordados conceitos sobre aplicações com grande demanda de processando, focando-se na renderização de imagens;
No capítulo 5, serão realizados os experimentos, com a explanação sobre o ambiente de testes, metodologia utilizada e os resultados;
No capítulo 6, serão apresentados as considerações finais, bem como sugestões de trabalhos futuros.
Com a evolução tecnológica e o uso cada vez mais comum de computadores para resolução de problemas dos mais variados tipos e complexidades, o poder computacional das máquinas tem crescido rapidamente, para tentar atender a essas demandas constantemente crescentes. No início da era computacional, as arquiteturas eram muito simples, mas atendiam de forma relativamente satisfatória as exigências da época. Porém, com o passar dos anos, e o aumento da complexidade dos problemas, foram surgindo necessidades de melhorias, como por exemplo, o aumento da velocidade dos dispositivos e a execução de tarefas em paralelo.
Segundo Pitanga (2003), os dispositivos foram evoluindo de forma gradual até a década de 80, quando surgiram os chips VLSI (Very Large Scale Integration) - circuitos integrados de larga escala de integração. O aumento da velocidade de hardware (componentes físicos do computador), por mais rápido que seja, sempre estará limitado aos recursos que as tecnologias de cada época pode oferecer. Devido a isso, desde que os computadores começaram a serem desenvolvidos, ficava clara a necessidade de se utilizar o paralelismo (execução de diversas tarefas de forma paralela) para se obter um melhor desempenho. Com o surgimento do conceito de processamento paralelo, ocorreram diversas mudanças nas arquiteturas computacionais, que foram evoluindo ao longo dos anos.
Com o barateamento dos custos de produção, devido ao surgimento dos chips VLSI, a produção de microcomputadores com processadores cada vez mais velozes e complexos tornou-se comum. Nesse período da história dos computadores, surgiram as arquiteturas paralelas e sistemas distribuídos.
Devido a redução dos custos, tornou-se viável usar dois ou mais processadores num mesmo computador, surgindo assim arquiteturas com capacidade de realizar processamentos paralelizados. Os Sistemas Distribuídos (que consistem em vários computadores interligados por uma conexão de rede de comunicação de dados, agregados com intuído de oferecer a imagem de um único sistema) surgem nessa mesma época. Devido a isso, no final da década de 80, as redes evoluíram cada vez mais, focando cada vez mais atingir uma maior velocidade de tráfego de dados. As arquiteturas paralelas também passaram a melhorar cada vez mais, com a grande evolução dos processadores.
Os sistemas distribuídos têm sido utilizados para a execução de programas paralelos, em substituição às arquiteturas paralelas, em virtude de seu menor custo e maior flexibilidade. Basicamente, sistemas distribuídos e arquiteturas paralelas compartilham as mesmas idéias, mesmo tendo surgido por motivações diferentes. (PITANGA, 2003, p. 03)
PROCESSAMENTO
Com o surgimento de diversas arquiteturas computacionais, diversas taxonomias foram criadas com o objetivo de padronizar, de uma maneira lógica, as características dos diferentes tipos de arquiteturas. (DANTAS, 2005)
Segundo Pitanga (2003), em 1927 Michael Flynn criou uma classificação de diversos modelos de arquiteturas de computadores, usando como critério o número de fluxos de dados e de instruções disponíveis no momento. Essa classificação criou quatro classes de computadores:
Arquitetura SISD – (Single instruction Single Data) é a categoria mais simples, onde o processamento feito pelo equipamento é seqüencial, ou seja, é executada somente uma instrução a cada ciclo de dado enviado. Tanenbaum (1992) salienta que:
A máquina tradicional de von Neumann é SISD. Ela tem apenas um fluxo de instruções, executado por uma única CPU, e uma memória contendo seus dados. A primeira instrução é buscada na memória e então executada. A seguir, a segundo é buscada e executada.
A maioria dos computadores pessoais, que fazem uso de processadores convencionais, também se encaixam nessa categoria;
Arquitetura MISD – (Multiple Instruction Single Data) são os computadores que conseguem executar mais de uma instrução ao mesmo tempo sobre um único conjunto de dados. Até hoje, não se tem conhecimento de uma arquitetura de computadores desse tipo;
Arquitetura SIMD – (Single Instruction Multiple Data) são os computadores capazes de executar uma mesma instrução paralelamente, fazendo uso de vários itens de dados. Nessa categoria se encaixam os computadores vetoriais, como o Cray T90 e o ILLIAC IV, da Universidade de Illinois.
[...] Uma aplicação típica para uma máquina SIMD é a previsão do tempo. Imagine o cálculo da temperatura média diária a partir de 24 médias horárias para muitos locais. Para cada local, exatamente o mesmo cálculo precisa ser feito, porém com dados diferentes. Uma arquitetura apropriada para esta tarefa é a máquina vetorial. (TANENBAUM, 1992)
Arquitetura MIMD – (Multiple Instruction, Multilpe Data) são as arquiteturas constituídas de vários processadores, independentes, onde cada um poderá executar instruções de forma relativamente autônoma dos demais processadores. Nessa classificação ocorre o processamento paralelo, havendo múltiplos fluxos de instruções e também múltiplos fluxos de dados. Nessa categoria também se encaixam os sistemas distribuídos.
Segundo Dantas (2005), a arquitetura MIMD se divide, de uma forma geral, em duas grandes categorias, de acordo com a interligação dos processadores e das memórias através de interconexões específicas. São essas categorias: os multiprocessadores e os multicomputadores.
Os multiprocessadores são as arquiteturas constituídas de vários processadores compartilhando uma única memória ou um conjunto delas (a memória do computador pode ser fisicamente composta por mais de um módulo). Este sistema é também conhecido como fortemente acoplada, pois os processadores e memória estão interligados por um sistema local de interconexão. Essa interligação pode ser feita por um barramento ou através de um equipamento de comutação. Seja qual for o tipo de interconexão, um sistema multiprocessador tem como maior característica, o compartilhamento global da memória entre os diversos processadores que constituem o sistema.
Diferentemente dos multiprocessadores, os multicomputadores são os ambientes fracamente acoplados, ou seja, os processadores têm suas próprias memórias locais, não existindo uma memória sendo globalmente compartilhada. Além disso, a comunicação entre os processos executantes em cada um dos processadores é feita por troca de mensagens.
Um exemplo simples e claro de uma configuração multicomputador seriam os ambientes em que há vários computadores pessoais interligados por uma rede local comum. Nesse caso, o barramento ou comutador usado para comunicação entre os processadores, seriam os equipamentos que compõem a rede local. Alguns princípios comuns dessas redes de computadores serão vistas no subtópico 2.2, por se tratar de um ponto fundamental no funcionamento dos sistemas distribuídos, que se encaixam nessa categoria de multicomputadores.
Tipos de arquiteturas
Até o momento, foram abordadas as configurações e classificações clássicas de arquitetura de computadores, de um modo mais abrangente e geral. Nesta seção, que será mais específica, serão abordados alguns dos ambientes ou arquiteturas computacionais mais utilizados.
Symetric Multiprocessor (SMP)
Segundo Dantas (2005), as arquiteturas de multiprocessadores simétricos (Symetric Multiprocessor - SMP) são caracterizadas por configurações de até dezenas de processadores que compartilham igualmente todos os recursos computacionais disponíveis no sistema e executando um único sistema operacional. É atribuída a denominação "simétrica" aos processadores, pois todos eles têm igual acesso a memória e aos dispositivos ligados ao sistema. O SMP se encaixa na categoria de multiprocessadores fortemente acoplados. Devido a isso, esses ambientes não são muito escaláveis, ficando limitado o acréscimo de muitos processadores. Isso se deve porque todos os processadores fazem acesso a uma única memória, crescendo assim, a taxa de colisão de acesso nesse repositório de dados. Uma solução para isso, desenvolvida por alguns fabricantes, é o uso de certos tipos de memórias locais, para cada processador, além do uso da memória global.
A expansão dessa arquitetura ocorre de forma vertical, ou seja, quando se deseja aumentar o poder de computação, são acrescentados novos processadores, mantendo concentrado todo o processamento no mesmo computador.
A arquitetura SMP é muito comum nos dias de hoje. Os servidores comerciais de fabricantes como IBM e Compaq por exemplo, possuem vários processadores.
Massively Parallel Processors (MPP)
As máquinas que fazem uso de processadores massivamente paralelos (Massively Parallel Processors - MPP) se encaixam na categoria das arquiteturas fracamente acopladas e geralmente são classificados como multicomputadores. (DANTAS, 2005)
Segundo Pitanga (2005), o MPP pode ser descrito como um conjunto de centenas ou até milhares de nós (computadores) conectados por uma rede de dados de alta velocidade. Cada um desses nós pode possuir uma memória principal e um ou mais processadores. Além disso, cada nó possui uma cópia do sistema operacional.
De acordo com Dantas (2005), em cada nó, as aplicações são executadas localmente e se comunicam através do envio de mensagens, usando-se da rede de comunicação de dados. O sistema de interconexão usado na configuração MPP é um elemento muito importante, já que ele é o barramento de comunicação entre os nós.
Como cada nó tem sua própria estrutura de memória e uma certa independência, isso permite ao MPP ser muito mais escalável do que os sistemas de arquitetura SMP. Existem diversos sistemas MPP comerciais, que são conhecidos como ASCI (Accelerated Strategic Computing Initiative). Dentre eles, podemos citar:
SGI ASCI Blue Mountain com 6166 processasdores;
HP ASCI Q. Alpha Server SC 45 1.25 Ghz com 8192 processadores;
Intel ASCI Red com 9632 processadores.
Sistemas Distribuídos
As arquiteturas de sistemas distribuídos não possuem uma memória global. Cada processador possui sua memória local e a comunicação entre os processadores é feita por troca de mensagens através de uma rede de comunicação de dados. (PITANGA, 2005).
Segundo Ribeiro (2005), os sistemas distribuídos foram projetados para fazer a distribuição das tarefas e aumentar o poder computacional. Esses sistemas têm como foco melhorar a comunicação entre os computadores, de forma fazer uma integração dessas máquinas, no sentido de prover uma maior rapidez e confiabilidade na troca de informações e na execução de processos distribuídos entre eles.
Nesses sistemas, é possível que uma aplicação seja fragmentada em partes menores, que são distribuídas e processadas em diversos computadores independentes que se comunicam através de uma linha de comunicação. Nos sistemas distribuídos, é criada uma ilusão que faz com que a rede de computadores seja enxergada pelo usuário como um único sistema de tempo compartilhado, ao invés de um mero conjunto de computadores independentes, distintos.
Os sistemas distribuídos foram criados com o intuito de resolver grandes problemas computacionais, dentre eles:
a) Necessidade crescente de um aumento facilitado do poder computacional: fazer acréscimo de um nó em um sistema distribuído é muito simples do que se acrescentar mais um processador em uma máquina de arquitetura SMP. Na arquitetura distribuída, o crescimento se dá de forma horizontal, diferentemente da SMP, que ocorre de forma vertical, ou seja, a expansão da arquitetura cresce fazendo-se a distribuição da carga entre diversos computadores, expandindo-se de forma horizontal, sem concentrar os recursos em um único computador, como ocorre na arquitetura SMP.
b) Adaptação de estrutura: os sistemas distribuídos podem se adaptar facilmente a qualquer tipo de estrutura organizacional, seja ela geograficamente distribuída ou não.
c) Maior confiabilidade do sistema: como esses sistemas são compostos por diversos computadores independentes e interconectados, isso acaba aumentando a confiabilidade e alta disponibilidade do sistema, já que a falha de algum nó poderá ser suprida pelos demais.
Esse tipo de arquitetura, em maior parte dos casos, oferece uma grande economia financeira, se comparados aos supercomputadores de capacidade equivalente. Apesar disso, esses sistemas apresentam uma certa dificuldade em relação a diversidade de softwares existentes no mercado, além de possíveis problemas com a rede de comunicação de dados, provocados por falha ou congestionamento durante as trocas de mensagens entre os nós. No caso dos sistemas distribuídos que possuem seus nós geograficamente espalhados (denominados Grids computacionais), a segurança pode ser considerada um fator crítico, já que os computadores são acessados de diferentes pontos.
Os clusters ou agregados de computadores, são também um tipo específico de sistemas distribuídos, cujos nós são geralmente dedicados, visando a execução de aplicações específicas de uma organização. Esses nós são agrupados em uma área fisicamente relativamente restrita, diferentemente dos Grids computacionais, que são constituídos de nós geograficamente dispersos. Os clusters computacionais serão abordados mais detalhadamente no capitulo 3.
Escalonamento de tarefas
O escalonamento de tarefas visa, principalmente, fazer a distribuição de tarefas entre os elementos de processamento, da forma mais eficiente possível. Isso objetiva minimizar o tempo de execução das aplicações, ou seja, aproveitar ao máximo os recursos computacionais existentes no ambiente (como por exemplo, os processadores e memórias) e reduzir o uso dos recursos de comunicação. (DANTAS, 2005).
De acordo com Pitanga (2005), o escalonamento pode ser aplicado em diversos cenários, sendo um dos principais, o balanceamento de carga entre os nós de um sistema distribuído, mais especificamente num cluster. O balanceamento de carga é um caso especial de escalonamento de tarefas, baseando-se na idéia de se fazer uma justa distribuição de tarefas de acordo com os recursos de hardware disponíveis do sistema. Essa idéia tem como base os métodos de escalonamento efetuados em sistemas monoprocessados de ambientes multitarefa (varias tarefas podem ser executadas, porém de forma alternada).
O escalonamento pode ser do tipo local ou global. O local refere-se em atribuir fatias de tempo (time-slices) de um processador a vários processos. Esse método é usado pelos sistemas operacionais multitarefa. Já o escalonamento global é realizado por sistemas distribuídos e consiste em redirecionar os processos para os computadores (ou processadores) constituintes do agregado.
O escalonamento global pode ser classificado como estático e dinâmico. No estático, como o próprio nome sugere, as atribuições dos processos aos processadores são realizadas antes da execução, ou seja, todas as informações relacionadas ao conjunto de tarefas que compõem a aplicação são já previamente conhecidas e definidas em tempo de compilação. Nesse caso, quando uma tarefa é escalonada para um determinado processador, ela permanecerá ali até o fim de sua execução, não podendo ser alterado de localização. Para sistemas onde a carga de processamento é totalmente dinâmica, esse método não é recomendável, por não ser capaz de tomar decisões de escalonamento de carga em tempo de execução.
Quanto ao escalonamento global dinâmico, a tomada de decisão para distribuição dos processos entre os processadores ou nós, é realizada durante a execução e não em tempo de compilação, como no estático. Praticamente não é necessário que nenhuma característica dos processos seja conhecida antes da execução, sendo o sistema capaz de analisar e escalonar dinamicamente, durante a execução. Esse método é muito usado em sistemas distribuídos.
INFRA-ESTRUTURA DE REDES DE COMUNICAÇAO DE DADOS
Uma rede de computadores pode ser definida como um conjunto de dois ou mais computadores ou equipamentos interligados, bem como compartilhando dados e recursos entre si. (TANENBAUM, 2003).
De acordo com Pitanga (2003), a rede de comunicação de dados é um componente fundamental para as arquiteturas MPP e sistemas distribuídos, já que esta atua como o barramento de comunicação entre os nós. O modo como essa linha de comunicação será implementada, pode ser diferente de um sistema para outro.
O desempenho de uma rede é medida de acordo com sua largura banda e latência. A largura de banda seria a quantidade de bits por segundo que podem ser transmitidos pela rede. A latência pode ser definida como o tempo levado para se enviar um dado de um computador para outro, incluindo todos os procedimentos tanto em nível de software (para a construção da mensagem) quanto em nível de hardware.
As aplicações executadas em um sistema distribuído, quanto menos fizerem acesso a rede, melhores serão os resultados. Se uma aplicação envia uma grande quantidade de pequenas mensagens, esta poderá ser afetada pela latência da banda; e se enviar poucas mensagens de tamanho grande, poderá ser afetada pela largura de banda. Para se obter um bom desempenho, é necessário o uso de uma rede com baixa latência e grande largura de banda. Para isso ser possível, é necessário o uso de protocolos de comunicação que minimizem a sobrecarga na comunicação.
Diversos protocolos de comunicação estão disponíveis, dentre eles o TCP/IP (Transmission Controle Protocol/Internet Protocol), que é o protoloco padrão da Internet. Segundo Kurose (2006), esse protocolo foi elaborado antes dos computadores pessoais e das estações de trabalho e antes mesmo da popularização das tecnologias de redes locais. O TCP/IP foi criado pelos pesquisadores Vinton Cerf e Robert Kahn. Eles perceberam a grande necessidade da existência de um protocolo de rede que desse um amplo suporte à comunicação de diversos tipos de aplicações e também que permitisse a intercomunicação entre arquiteturas diferentes. Mais adiante, esse protocolo foi dividido em duas partes, o TCP e o IP, operando de modo separados.
Como muitos outros protocolos, o TCP/IP é constituído por um conjunto de camadas (Aplicação, Transporte, Rede, Enlace e Física) onde cada um é responsável por atender um grupo de problemas, de níveis de abstração diferentes, relacionados a transmissão de dados. As camadas superiores, por estarem mais próximos do usuário, manipulam dados mais abstratos e confiam toda a parte de transmissão para as camadas inferiores. Nessas camadas inferiores, os dados mais abstratos são recebidos das camadas superiores, que por sua vez são convertidos para formatos de mais baixo nível, possibilitando assim, realizar a transmissão física das informações. Segundo Pitanga (2003), em muitas implementações de sistemas distribuídos, o protocolo TCP/IP é utilizado.
Nesse trabalho, para a implementação do cluster de computadores, além do TCP/IP serão utilizados outros protocolos, como o NFS (Network File System) e o SSH (Secure Shell). Esses protocolos visam implementar determinados serviços específicos que são muito utilizados na implementação de alguns tipos de sistemas distribuídos.
O NFS, projetado pela Sun em 1989, possibilita o compartilhamento de sistemas de arquivos e diretórios centralizados entre os computadores de rede, de forma transparente. No caso dos sistemas distribuídos, isso facilita a manutenção e atualização de arquivos que são comumente usados pelos nós, já que apenas uma cópia dos arquivos precisa ser mantida. (WIKIPEDIA, 2006a)
O SSH, permite que um computador se conecte a outro da rede, de forma a executar comandos remotos. Todos os dados que trafegam via SSH são criptografados, garantindo assim, uma maior segurança contra interceptação de dados. Esse protocolo é muito utilizado em algumas implementações de sistemas distribuídos, que o usam o protocolo SSH (em conjunto com o serviço de mesmo nome) para realizar a troca de mensagens entre si, para a comunicação entre os processos distribuídos. (WIKIPEDIA, 2006b)
Para que esses protocolos possam ser aplicados, possibilitando assim a comunicação de dados e execução de diversos serviços entre os diversos computadores de uma rede, há necessidade de que esses nós estejam interligados fisicamente. Essa conexão poderá ser feita através de diversos tipos de cabeamentos e interfaces. A junção ou concentração dessas conexões, permitindo assim a intercomunicação entre as máquinas, poderá ser feita por diversos tipos de dispositivos, dentre eles o comutador. Segundo Pitanga (2005), o comutador (ou switch) é um dispositivo fundamental para a construção de um cluster de computadores. O comutador é constituído de várias portas, onde em cada uma é conectado um computador.
De acordo com Dantas (2005), os comutadores possibilitam que conexões paralelas sejam feitas entre os nós, desde que esses computadores façam a interconexão em pares entre si. Tanenbaum (2003) afirma que, quando o comutador recebe um quadro de dados de um computador "A" para ser encaminhado para um computador "B", ele encaminha esses dados ativamente para o destino. Como apenas um nó é ligado por porta do comutador e a comunicação é feita em pares, não ocorre a colisão de dados, garantindo assim, um melhor desempenho na transmissão de dados.
DEFINIÇAO
A palavra "cluster" vem do inglês, e significa agrupamento ou agregado. O termo "cluster de computadores" ou então clustering significa basicamente a utilização dois ou mais computadores (chamados de nodos, nós ou node) de forma conjunta, através de uma interconexão de rede, para a resolução de algum tipo de problema ou aplicação. Essa arquitetura se encaixa como um tipo específico de sistemas distribuídos. O cluster deverá atuar de tal forma a criar a imagem de um único sistema (SSI – Single System Image) ou máquina virtual, do ponto de vista do usuário. Desse modo, toda a parte de distribuição, comunicação e sincronização de tarefas, comunicação entre nós, uso de computação paralela/distribuída e tudo que for relacionado com a implementação do cluster de computadores, deverá ser totalmente transparente ao usuário. (PITANGA, 2005).
Segundo Dantas (2005, p. 147-148), "As configurações, conhecidas como clusters computacionais, têm como seu maior objetivo a agregação de recursos computacionais para disponibilizá-los para a melhoria de aplicações".
As características fundamentais para a implementação de uma plataforma de um cluster de computadores são: a distribuição de carga, ou seja, a partição de uma grande tarefa em tarefas menores que por sua vez serão distribuídas entre os nós do agrupamento; a elevação da confiança, que consiste na redundância de dados entre o cluster, sendo tolerável a determinados tipos de falhas (como por exemplo, a queda de um nó); e a performance. Os principais componentes para se formar um cluster de computadores são: Computadores de alta performance (Estações de trabalho ou SMP"s), sistemas operacionais, redes de alta performance, placas de redes (para cada nó), serviços e protocolos de comunicação de alto desempenho, criação de imagem única e aplicações e subsistemas de gerenciamento e manutenção. (PITANGA, 2005).
Pitanga (2005) ainda afirma que atualmente, diversas implementações de clusters de computadores são amplamente utilizadas em muitas instituições de pesquisa, empresas e corporações em que haja a necessidade de um alto poder de processamento, alta disponibilidade e/ou balanceamento de carga.
NECESSIDADES E VANTAGENS
De acordo com Pitanga (2005), com o surgimento de tarefas que exigem grande poder computacional, como por exemplo, a renderização de imagens e animações em alta velocidade, análise de abalos sísmicos e a previsão do tempo, a necessidade de computadores com alto poder de processamento tornou-se indispensável. Porém o uso de supercomputadores apresenta diversas desvantagens, principalmente pelo seu alto custo, se comparado a um cluster de capacidade equivalente. Grandes corporações e instituições de pesquisa vêm empregando os clusters não só por ser a melhor opção entre custo e poder computacional, mas também por apresentar diversas outras vantagens em relação aos sistemas que empregam, principalmente, a arquitetura SMP.
Dentre essas vantagens, a tolerância a falhas (ou alta disponibilidade de dados e serviços) é um fator fundamental em aplicações de missão crítica, ou seja, aplicações que não podem sofrer interrupções ou falhas. Por exemplo, numa UTI (unidade de tratamento intensivo) de um hospital, se o paciente está usando algum tipo de equipamento que o mantém vivo, este não poderá falhar por nenhum momento, pois caso contrário, poderá levar a óbito o paciente.
A manutenção de apenas um único computador realizando atividades desse nível de relevância acaba por não garantir que os serviços estarão sempre operantes, já que falhas de hardware e/ou software podem ocorrer (e geralmente ocorrem, cedo ou tarde) e assim derrubar os serviços. Já no caso de um cluster, caso ocorra falha em algum nó, rapidamente o sistema deve desviar as tarefas que correspondiam a esse nó para algum outro, de forma a não prejudicar o funcionamento do sistema como um todo.
Outra grande vantagem é a grande escalabilidade que o agrupamento de computadores oferece. Para a expansão da capacidade e/ou disponibilidade, basta apenas que novos nós sejam adicionados, proporcionalmente a demanda de trabalho.
Devido ao fato do cluster ser independente de fornecedores, ou seja, dele poder ser constituído de computadores com hardware aberto/heterogêneo e com uso de softwares livres, acaba contribuindo, ainda mais, para seu baixo custo e acessibilidade de implementação.
Empresas de menor porte e universidades, com poucos recursos financeiros, podem recorrer a uma alternativa cada vez mais freqüente para obtenção de processamento de alto desempenho, a custos razoáveis, aproveitando o hardware existente [...] através do uso de clusters de computadores[...]. (PITANGA, 2003, p. 17).
ÁREAS DE APLICAÇAO
Segundo Pitanga (2003), as áreas de aplicação de um cluster são muito vastas, tais como em diversas áreas da medicina, física e computação gráfica. Em qualquer situação onde um problema computacional necessita de um alto poder de processamento e/ou disponibilidade, tendo como vantagem o uso de processamento paralelo/distribuído, os clusters de computadores poderão ser empregados. Esses problemas são, em maior parte dos casos, aplicações muito grandes, onde em alguns casos necessitam de muito poder de processamento, em outros, de muita memória ou então de um alto uso de comunicação. Essas aplicações geralmente são ligadas a atividades de missão critica, de cunho científico ou econômico.
Até a alguns anos atrás, os computadores existentes satisfaziam as necessidades das aplicações. Assim como o hardware evoluiu, o software acabou tendo uma evolução ainda maior, principalmente em termos de exigência de processamento e alta disponibilidade. Com isso, tornou-se muito mais viável o uso de clusters, principalmente no tocante aos custos financeiros.
Aplicações desse porte são empregadas em diversas áreas, como por exemplo, em diagnósticos em medicina, suporte a decisão apoiada em base de dados paralelos, realidade virtual e na criação de cenas artificiais em filmes.
Pitanga (2003) cita alguns exemplos de diversas áreas onde se faz uso de clusters de computadores:
a) Servidores da Internet – Com a grande demanda de acessos em algum serviço, como por exemplo, em algum site, o cluster poderá ser implementado para realizar a distribuição de carga entre os nós e conseqüentemente aumentar da capacidade de aceitar requisições de acesso simultaneamente, mantendo um bom tempo de resposta e aumentando a disponibilidade do serviço. Um exemplo dessa aplicação é o The High-Availability Linux Project (LINUX-HA, 1999).
b) Segurança – Em sistemas de detecção de intrusão (IDS – Intrusion Detection System), o uso de processamento paralelo beneficiará grandemente na velocidade de atuação de qualquer tipo de processo de detecção e bloqueio de ataques;
c) Banco de dados – Com o uso de cluster, será possível otimizar, consideravelmente, o tempo de busca e consulta em grandes bases de dados, além de manter a alta disponibilidade. O banco de dados MySQL possui uma implementação para clusters. (MYSQL-CLUSTER, 2006).
d) Computação gráfica – Esse é um ramo que certamente exige, cada vez mais, muito poder de processamento das máquinas, para que imagens com qualidades cada vez mais próximas da realidade possam ser geradas em tempo hábil. O uso de clusters é amplamente usado nessa área, onde se deseja sempre gastar o menor tempo possível para a renderização de cenas e animações. Muitas cenas artificiais de filmes famosos são geradas com o auxílio de clusters de computadores. Uma técnica de renderização muito utilizada em sistemas distribuídos é a Ray-tracing, que será abordada no capítulo 4.
e) Aerodinâmica – Simulações de testes de novas aerodinâmicas aplicadas em aviões, carros de alta velocidade, naves espaciais, dentre outras situações mais onde a aerodinâmica é fundamental. Graças aos clusters de computadores que esse tipo de simulação, que por sinal consome um nível altíssimo de processamento, é possível de ser feita;
f) Inteligência artificial e automação – Reconhecimento de padrões, biometria, máquinas de inferência, dentre outras;
g) Engenharia genética – No famoso projeto Genoma, também foram usados clusters de computadores para realizar a computação do sequenciamento genético. (DOE-GENOMES, 2003).
Além desses exemplos, diversos outros também aplicam os clusters, como na análise de elementos finitos, em aplicações de sensoriamento remoto, na exploração sísmica, na oceanografia e astrofísica, na previsão do tempo, em pesquisas militares e nucleares e em qualquer problema de pesquisa básica.
COMPUTAÇAO PARALELA E DISTRIBUÍDA
O uso de computação paralela tem se tornado muito comum em diversas áreas com exigência massiva de processamento, como as que foram citadas anteriormente. Um típico exemplo de cluster de computadores, montado pela NASA, é o cluster Beowulf. Basicamente esse tipo de cluster consiste no uso de computadores montados com hardware comuns (heterogêneo ou não) e executando algum sistema operacional de código-fonte livre. O Beowulf será detalhado no capítulo 3. (PITANGA, 2005).
Computação paralela refere-se à submissão de trabalhos ou processos em mais de um processador. Clusters paralelos são, tipicamente, grupos de máquinas que são dedicadas a compartilhar recursos. [...] Com o preço atual de hardware comum, não é difícil encontrar clusters com um mínimo de 16 nós [...] Google têm relatado ter mais de 8.000 nós em seu cluster Linux. (BOOKMAN, 2003, p. 12).
Segundo Bookman (2003), os clusters ou computadores paralelos fragmentam as tarefas entre os seus nós/processadores. Geralmente, a execução de uma tarefa dividida entre os vários nós de um cluster, é mais eficiente do que se fosse executada num único computador uniprocessado. Porém, não quer dizer que o ganho de desempenho será proporcional ao número de nós do cluster, ou seja, se temos um cluster com 16 nós, não quer dizer que uma aplicação rodará 16 vezes mais rápido se comparado à execução em apenas um único computador. Os clusters paralelos necessitam de ajustes constantes, de forma a otimizar cada vez mais, o desempenho do sistema para a execução das tarefas tenham um resultado satisfatório.
Para que algum programa realmente se beneficie da computação paralela, vários fatores precisam ser levados em conta. O principal deles é se o código foi escrito e otimizado para trabalhar com vários processadores ou nós de um cluster, senão pouco ou de nada adiantará executar um programa projetado para execução seqüencial, num cluster paralelo. A computação paralela é voltada para a execução de projetos que envolvem cálculos matemáticos intensos como por exemplo, na área de computação gráfica.
Computação distribuída é a habilidade de executar vários trabalhos através da potência de processamento de ambiente, principalmente heterogêneos. Embora a computação distribuída possa ser facilmente coberta sob sistemas homogêneos, o que diferencia a computação paralela da computação distribuída é que ela não é necessariamente ligada a um tipo de máquina, ou cluster dedicado. (BOOKMAN, 2003, p. 127)
Bookman (2003) ainda firma que, em muitas situações, a computação paralela e distribuída pode ser confundida, porém o grande diferencial é que na distribuída, não há necessidade de um cluster com nós dedicados para aquele trabalho ou então algum tipo específico de computador ou sistema. Ao invés de um computador extremamente potente ou cluster dedicado fazer todo o processamento, os dados e tarefas são distribuídos, geograficamente ou não, por diversos sistemas para que seja realizado o processamento. Em suma, uma grande tarefa é dividida entre vários grupos de computadores distintos, que não são dedicados para realizar essas tarefas, aproveitando-se os recursos ociosos disponíveis. Inclusive a localização dessas máquinas podem estar geograficamente distantes (grids computacionais). Após cada unidade concluir seu processamento, o resultado é devolvido para o nó controlador, que por sua vez, irá efetuar a junção dos dados e enviar um novo conjunto de tarefas. Segundo Bookman, "Diferentemente da computação paralela, alguns modelos distribuídos são destinados a gerenciar os ciclos de CPU não utilizados de várias máquinas". (BOOKMAN, 2003, p. 127). Há também os modelos distribuídos que se assemelham aos paralelos, por empregar ambientes homogêneos e dedicados.
Pitanga (2005) observa que a computação paralela visa resolver os problemas de um modo bem mais rápido, sendo que a computação distribuída não é necessariamente usada para o aumento de poder de processamento, mas também para outras finalidades, como a alta disponibilidade. Verifica-se então que a computação paralela é um tipo específico de computação distribuída.
Um exemplo de aplicação prática de sistemas distribuídos é o projeto cientifico SETI@home (SETI@HOME, 2006). Trata-se de um aplicativo que funciona de forma distribuída em todo o mundo, onde cada máquina que possuir o programa instalado, passará a atuar como um nó desse grande sistema distribuído, denominado Grid computacional. A comunicação entre os computadores é feita pela própria internet. O objetivo desse projeto era fazer busca de vida extraterrestre através da análise de materiais coletados por um radiotelescópio. Cada computador só começa a fazer o processamento quando o protetor de tela é ativado, supondo que a máquina esteja ociosa. Com esse projeto, foram obtidos mais de 600.000 anos de tempo de computação.
TIPOS DE CLUSTERS
Basicamente, existem quatro tipos de clusters: os de Alta Disponibilidade (HA – High Availability), de Alta Performance Computacional (HPC – High Performance Cluster), de Balanceamento de Carga (LB – Load Balancing) e os clusters que combinam tanto Alta Disponibilidade quanto Balanceamento de Carga.
Alta disponibilidade
É comum que os computadores parem de funcionar em momentos menos esperados. É normal que discos rígidos, fontes de alimentação de energia e os próprios programas apresentem falhas após muito tempo de uso/execução. O problema é que essas falhas são imprevisíveis e a melhor maneira de se prevenir, é usando algum tipo de sistema que seja tolerável a falhas, empregando-se técnicas de redundância de dados e de hardware.
Um cluster de Alta Disponibilidade visa manter a disponibilidade dos serviços prestados por um sistema computacional replicando serviços e servidores, através da redundância de hardware e reconfiguração de software. Vários computadores juntos agindo como um só, cada um monitorando os outros e assumindo seus serviços caso algum deles venha a falhar. (PITANGA, 2005, p. 18)
Dependendo da aplicação, não pode haver falha ou queda do sistema. Por exemplo, em um banco ou numa empresa que vende produtos pela internet, qualquer momento que o sistema vendas (site por exemplo) se tornar indisponível, poderá acarretar em sérios prejuízos, além de prejudicar a imagem da empresa ao cliente. É nesse tipo de contexto que os clusters de alta disponibilidade são muito empregados.
Segundo Pitanga (2003), a alta disponibilidade dos sistemas tornou-se um item vital para a sobrevivência empresarial, pois muitas empresas são tão dependentes da tecnologia que, se o sistema parar, a empresa também pára. Um servidor de alto nível de qualidade fornece uma disponibilidade de 99,5%, enquanto uma implementação com o uso de clusters apresenta uma disponibilidade ainda superior, no valor de 99,99%.
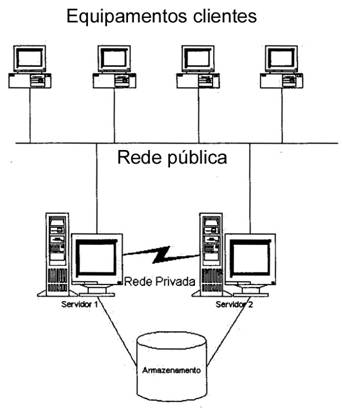
Figura 1. Exemplo de cluster de Alta Disponibilidade
Fonte: (PITANGA, 2003)
Basicamente o funcionamento de um cluster alta disponibilidade é ilustrado através do exemplo da figura 1. Esse cluster é composto por dois nós. Um desses nós atua como primário, ou seja, atende todas as requisições provindas dos computadores clientes situados na rede pública (que poderia ser a internet, por exemplo). O outro nó fica em espera, monitorando ininterruptamente os serviços e hardware do outro nó através de uma rede privada. Caso haja alguma falha nos serviços que estão rodando nesse nó, ou até mesmo falha de hardware, o segundo nó, automaticamente, irá assumir todas as tarefas, mantendo todos os serviços no ar, como se nada tivesse ocorrido do ponto de vista dos computadores clientes e usuários. Como esse cluster mantém um disco de armazenamento comum entre os dois nós, todas as informações relacionadas as aplicações estarão sempre atualizadas quando o outro computador assumir o controle.
Balanceamento de carga
Com o crescimento das grandes corporações e a crescente dependência da informática na gestão de negócio, o fornecimento de diversos serviços via internet tem se tornado comum. Com a popularização massiva dessa rede mundial de computadores, o acesso a esses serviços on-line tem gerado uma grande quantidade de tráfego. Um ótimo exemplo de sites que geram uma grande quantidade de acessos são os de compras online. Outro exemplo de site, bastante famoso e que possui uma quantidade de acessos extremamente alta, é portal de busca da empresa Google - http://www.google.com.
Esses tipos de serviços, para que consigam suportar a grande demanda de acessos, empregam diversas tecnologias que envolvem o uso de clusters de computadores para fazer o balanceamento de carga.
Equilíbrio de carga refere-se ao método onde os dados são distribuídos através de mais do que um servidor. Quase qualquer aplicativo paralelo ou distribuído pode se beneficiar do equilíbrio de carga. Tipicamente, os servidores Web são mais proveitosos e, portanto, o aplicativo mais utilizado de equilíbrio de carga. (Bookman, 2003, p. 10)
Segundo Pitanga (2003), o portal de busca do Google, por exemplo, possui centenas de servidores atuando em conjunto, fazendo o balanceamento das requisições provindas dos internautas. O interessante é que tudo isso é transparente ao usuário. Ao acessarmos o portal, não se percebe que a cada acesso que fazemos, um servidor diferente atende as requisições. Outro detalhe é que esses servidores não são necessariamente homogêneos do ponto de vista de hardware e de software; eles possuem funções e capacidades diferentes, sendo totalmente heterogêneos. O uso de servidores homogêneos se aplica mais em clusters de alta disponibilidade.
O balanceamento de carga entre servidores faz parte de uma solução abrangente em uma explosiva e crescente utilização da rede e da internet, provendo um aumento na capacidade da rede, melhorando a performance. Um consistente balanceamento de carga mostra-se hoje como parte integrante de todo o projeto de hospedagem de sites e comércio eletrônico. (Pitanga, 2005, p. 19).
De acordo com Pitanga (2003), nos clusters de balanceamento de carga, é necessário ter um elemento que seja responsável para fazer o balanceamento das requisições provindas dos usuários entre os servidores constituintes do cluster. Isso evita que um ou mais servidores responda a uma mesma requisição, atrapalhando assim, a comunicação com o cliente. Além disso, esse elemento precisará fazer a verificação permanente da comunicação e a checagem da situação dos servidores. Isso evitará que alguma requisição seja distribuída para um servidor que tenha acabado de apresentar algum tipo de falha.
O balanceador poderá ser um dos nós do cluster (denominado nó mestre ou controlador), onde todas as requisições dos clientes incidirão sobre ele, que por sua vez, repassará para algum dos servidores (nós) do agrupamento. O importante é que, na visão do cliente, exista apenas um único servidor e endereço no qual ele fará as requisições. Existem vários softwares que desempenham esse papel, como por exemplo o Virtual Server, Balance e o Turbo Cluster.
Segundo Bookman (2003), a principal desvantagem de um cluster de balanceamento de carga é que os dados precisam estar sempre consistentes, disponíveis e sincronizados entre todos os servidores, pois caso contrário, a distribuição de carga não seria eficaz.
Alta performance computacional
Os clusters de alto poder computacional vem sendo usados em diversos ramos comerciais e científicos, criando novas perspectivas de desenvolvimento e evolução nessas áreas.
Os clusters de alto desempenho tradicionais tem provado seu valor em um variedade de usos - de fazer previsão do tempo à desenho industrial, de dinâmica molecular para a modelagem astronômica. A computação de alta performance criou uma nova abordagem para a ciência – esse modelo é agora uma alternativa viável e respeitosa para as experiências tradicionais e abordagens teóricas. (SLOAN, 2004, p. 03)
De acordo com Pitanga (2003), os clusters de alta performance computacional (HPC – High Performance Cluster) têm se destacado nas universidades, instituições de pesquisa e empresas onde o alto poder processamento é fundamental para a resolução de diversos problemas através de aplicações paralelizáveis. O seu custo razoavelmente baixo, se comparado com o alto valor de um supercomputador de porte de processamento equivalente, é a maior das justificativas para esse destaque.
O processamento de alto desempenho, que engloba tanto o processamento paralelo quanto distribuído, muitas vezes nos leva a imaginar supercomputadores, de grande dimensão, de custos milionários e de difícil manutenção e operação. Porém, nos dias de hoje, com o uso dos clusters, os custos foram drasticamente reduzidos, principalmente com o surgimento de computadores pequenos muito rápidos e de baixo custo. Com isso, é possível construir clusters de alta performance, para diversos fins, com nós muito poderosos a preços atrativos, resultando assim, num investimento total muito compensador. Outra vantagem é a facilidade de montagem desses clusters, já que o processo consiste basicamente no uso de dois ou mais computadores conectados por uma rede padrão, e com softwares apropriados.
Observamos em Pitanga (2005, p. 22) que, "[...] uma grande tarefa computacional pode ser dividida em pequenas tarefas que são distribuídas ao redor das estações (nós ou nodos), como se parecesse um supercomputador massivamente paralelo [...]"
O cluster de alto desempenho é composto de um agrupamento de computadores interconectados através de uma rede de dados, onde trabalham juntos de forma a gerar um recurso em conjunto e integrado. Os nós do cluster podem ser constituídos de computadores de arquiteturas comuns (PCs, estações de trabalho ou SMP"s), com sistema operacional e discos próprios. Apesar de ser composto por nós de arquiteturas simples, esse sistema pode fornecer vantagens somente encontradas em supercomputadores (SMP).
De acordo com Pitanga (2005), os nós de uma rede geralmente são de complexidade inferior aos nós de um cluster, já que em grande parte consistem em computadores ou estações de um único processador. Os nós de um cluster podem conter dois ou mais processadores, tornando-se mais complexas que uma arquitetura MPP. Isso ocorre pelo fato dos nós de um cluster possuírem, na maior parte dos casos, de discos rígidos, memória e sistemas operacionais completos, itens esses não presentes em máquinas MPP.
Quanto a transparência do cluster, ao nível de usuário, ela pode ser comparada a um nível semelhante ao das máquinas MPP. O sistema operacional fica responsável pelo gerenciamento dos processadores, trabalhando em conjunto com recentes ferramentas de gerenciamento dos nós do agregado, criando assim, a imagem de um sistema único, de visão centralizada.
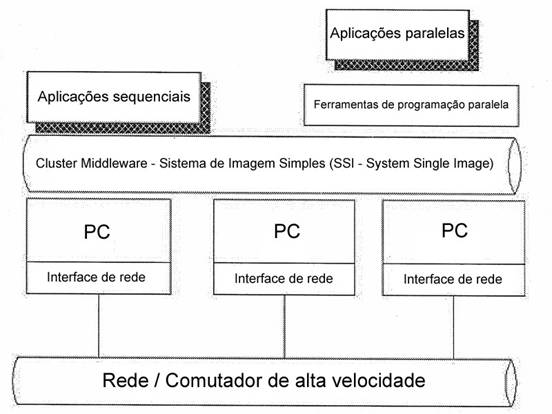
Figura 2. Estrutura de um cluster de alto desempenho
Fonte: (PITANGA, 2005)
Na figura 2, é demonstrado o exemplo de uma estrutura genérica de um cluster de alto desempenho. Na camada de middleware, são implementados todos os serviços relacionados a implantação do conceito de sistema de imagem única, permitindo assim, que todos os nós do agregado trabalhem como um único recurso, para atender a requisições das aplicações que serão executadas no cluster. Essa camada pode ser implementada em um dos nós do cluster, que será responsável por distribuir das tarefas para os demais nós de forma transparente ao usuário. Segundo Dantas (2005 p. 129), o "[..] middleware é um pacote de software que [...] auxiliam desenvolvedores de aplicação a não se preocuparem com características específicas do sistema operacional".
Acima da camada de middleware, temos as aplicações seqüências, paralelas e as ferramentas de programação paralela. Essas aplicações podem ser executadas no cluster, porém no caso de aplicações seqüenciais, os recursos do agregado serão pouco aproveitáveis. As ferramentas de programação paralela fornecem um ambiente de programação para essa arquitetura, de forma a otimizar o tempo de processamento. Esses ambientes de programação consistem de bibliotecas paralelas, depuradores e linguagens de programação capazes de interagir com o middleware e com o software de comunicação utilizado pela rede do cluster, fornecendo assim um alto poder de processamento. Esses ambientes de programação paralela foram uma das áreas que mais se desenvolveram com o surgimento e popularização dessa arquitetura de cluster. Surgiram diversas bibliotecas e linguagens de programação, cada uma com funcionalidades específicas e desempenhos diferentes. Dentre as bibliotecas de programação paralela, as mais comuns são a PVM (Paralell Virtual Machine) e a MPI (Message passing interface), que serão abordadas mais adiante.
Existem diversos projetos de clusters de alto desempenho, sendo os mais usados descritos logo a seguir.
Network of Workstation
Esse projeto foi criado pela Universidade de Berkley. Ele consiste em se construir um sistema de computação paralela de grande porte, utilizando-se de estações de trabalho comuns (workstations) e componentes de redes populares, de baixo custo, como por exemplo os switches. (Pitanga, 2005)
De acordo com Dantas (2005, p. 156), "Quando uma configuração de cluster é caracterizada por uma interligação virtual, ou seja, não-dedicada, o ambiente em termos de topologia usualmente é denominado como Now (Network of Workstation)".
Um exemplo desse tipo de cluster são aqueles construídos usando-se as estações de trabalho de um laboratório de informática de uma universidade. Esse é um tipo muito comum visto em instituições de ensino, já que o custo de implementação é praticamente zero, por usar de uma infra-estrutura já existente. Geralmente são também usados sistemas operacionais de código-fonte livre, como o Linux.
High Performance Virtual Machine (HPVM)
De acordo com Pitanga (2005), o HPVM, desenvolvido pela Universidade de Illinois, visa o desenvolvimento de um supercomputador com o uso de equipamentos genéricos/comuns e usando o Windows NT como sistema operacional. Nessa implementação, há também a preocupação em se esconder a complexidade dos sistemas distribuídos, através de uma interface simplificada e transparente ao usuário. Este projeto é composto de por uma combinação de ferramentas e bibliotecas de programação com a finalidade de criar um ambiente de alta performance computacional no sistema distribuído.
Na visão de um programador, o HPVM é constituído de um sistema de camadas. São no total quatro camadas, sendo cada uma delas responsável por uma finalidade diferente. São elas (da ordem da camada de mais baixo nível para a mais alta): a camada de rede, a de Transporte, API (bibliotecas paralelas) e Aplicações, sendo esta ultima podendo ser um programa de alto ou baixo nível, dependendo da API (Interface de Programação de Aplicação) usada.
Um diferencial importante desse cluster é o chamado Dynamic Coscheduler (DCS), que consiste num mecanismo que coordena o processo de escalonamento de operações independentes, ou seja, ele consegue distribuir uma tarefa paralela de forma a rodar concorrentemente em processadores separados. Quando alguma operação distribuída requer acesso a outros nós do agregado, o DCS é capaz de reconhecer isso, em tempo real, e realizar toda a parte de sincronização entre os processos, visando assim, garantir uma maior performance do cluster.
Uma grande desvantagem desse cluster, em termos de custo, é o fato dele usar um sistema operacional proprietário e pago, elevando consideravelmente o custo de implementação do sistema.
Solaris MC
Segundo Dantas (2005), o Solaris MC pode ser descrito como um sistema operacional voltado para computadores utilizados em um cluster. Esse sistema oferece a imagem de um sistema único (SSI), fazendo com que o cluster se pareça ao usuário e aos programas como um único supercomputador. Essa implementação provê escalabilidade, facilidade de manutenção e administração e redundância (alta disponibilidade).
Esse sistema foi construído usando-se como base o sistema operacional Solaris. Na realidade, o Solaris MC não se trata de um sistema operacional em si, mas sim de módulos criados para serem carregados no Solaris original, reduzindo drasticamente as modificações necessárias a serem feitas no núcleo do sistema operacional. Assim, ele facilita sua expansão em diversos tipos de clusters.
Esse sistema é muito usado em aplicações de gerenciamento de banco de dados online e suporte a decisão, onde a escalabilidade e alta disponibilidade são fundamentais num sistema de imagem única.
De acordo com Sun (2006), o Solaris MC oferece uma imagem global única (SSI) de todos os processadores e usuários constituintes do agregado, podendo estes ser gerenciados de um único ponto, facilitando assim o processo de manutenção e gerenciamento dos clusters.
OpenMosix
Conforme Bookman (2003), o OpenMosix introduz o processamento e distribuição das tarefas diretamente no núcleo do sistema operacional, criando um ambiente efetivamente distribuído, porém mantendo-se a transparência de um sistema único. Ele é uma extensão que é aplicada ao núcleo do sistema operacional Linux, implementando todas os procedimentos de distribuição de processos entre os nós diretamente em seu cerne. Assim, o Linux passa a atuar como um sistema operacional nativamente habilitado para funcionar como um sistema paralelo/distribuído. Esse projeto é baseado no projeto Mosix da Hebew University, porém esta é uma versão de código-fonte aberto, por isso o nome "Open Mosix"
O OpenMosix foi feito para ser executado em qualquer computador da plataforma Intel, como um ambiente real de um cluster distribuído. Isso permite uma grande flexibilidade de configurações dos nós constituintes do agregado.
Esse sistema gerencia, de forma transparente ao usuário, toda a parte de equilíbrio de carga. Ele automaticamente distribui as tarefas entre os nós, de forma proporcional a capacidade e disponibilidade de cada computador, sem intervenção do usuário.
As tarefas que sejam originadas em um nó que esteja bastante ocupado são migrados para outro nó da configuração. O OpenMosix tem um contínuo serviço de adequação e otimização de recursos. Estas características do ambiente são decorrentes da criação de extensão que gera uma abordagem SSI. (DANTAS, 2005, p. 133)
De acordo com Dantas (2005), o maior atrativo desse tipo de cluster, é que as aplicações a serem executadas não precisam ser desenvolvidas especialmente ao OpenMosix, já que todo o processo de distribuição de tarefas é feita pelo núcleo do sistema operacional. Com isso, quando o usuário executa qualquer tipo de aplicativo genérico ou até mesmo algum comando interno do Linux, o núcleo estará realizando a tarefa de forma distribuída, como se fosse uma máquina SMP ampliada, de forma totalmente transparente ao usuário. Maiores informações sobre esse projeto podem ser encontradas em OpenMosix (2006).
Beowulf Project
De acordo com Sloan (2004), quando se fala em multicomputadores e clusters, o Beowulf é o mais comum. Os cientistas Thomas Sterling e Don Becker, do Centro aeroespacial Goddard da NASA, criaram um computador paralelo com hardware heterogêneo e softwares livres disponíveis na época, em 1994. Esse supercomputador foi chamado de Beowulf, nome esse inspirado de um cavaleiro inglês, personagem de um poema épico da literatura inglesa. Além desse projeto, surgiram outras variantes mais adiante.
O Beowulf é um projeto bem sucedido. A opção feita por seus criadores de usar hardware e software aberto, tornou-o fácil de se replicar e modificar. A prova disso é a grande quantidade de sistemas construídos à moda Beowulf em diversas universidades, empresas americanas e européias e até residências. Mais do que um experimento, foi obtido um sistema de uso prático que continua sendo aperfeiçoado constantemente. (PITANGA, 2005, p. 44)
Observamos também que, dentre os softwares livres que são utilizados no cluster, destacam-se os que permitem a realização de processamento paralelo, como por exemplo as bibliotecas de programação MPI e PVM. Ambas serão abordadas no capítulo 3.6.
Segundo Pitanga (2003), essa técnica de se usar computadores comuns para a construção de um supercomputador com grande poder de computação paralela foi apontada como uma saída muito importante para a NASA, para usar em suas aplicações de missão crítica[1]bem como aplicações que exigem uma grande demanda de processamento.
Na época, a NASA precisava de um supercomputador com um alto poder de processamento, na casa dos gigaflops (um bilhão de operações em ponto flutuante por segundo). Um equipamento desse porte, em meados de 1994, custava em torno de um milhão de dólares, investimento esse muito alto para suprir a necessidade de apenas um grupo de cientistas.
Nessa situação, Thomas e Don decidiram interligar, através de uma rede Ethernet, 16 computadores comuns (cada um com um único processador 486), usando o Linux como sistema operacional e diversos softwares livres. Com esse cluster, eles conseguiram atingir um poder de processamento que para época já era considerada muito alta, em comparação aos supercomputadores de menor porte. No tocante aos gastos, eles gastaram um valor 10 vezes menor do que teriam gastado com a compra de um supercomputador de capacidade de processamento semelhante.
Conforme observado, o Beowulf foi projetado com o propósito de atender a elevada e crescente exigência de alto nível de processamento provindo de diversas áreas científicas, visando a construção de sistemas computacionais poderosos e economicamente acessíveis. Isso se aliou também com a grande evolução e barateamento dos processadores ao longo desses anos.
Para um cluster ser considerado um Beowulf, basicamente ele deverá obedecer as características citadas anteriormente, como o uso do Linux em todos os nós, bibliotecas de troca de mensagens (MPI e PVM) e aplicativos de livre distribuição, bem como a independência de hardware.
Pitanga (2005) observa que as universidades são os locais onde mais implementaram esse tipo de cluster, inclusive no Brasil. Dentre as universidades brasileiras que usam o Beowulf em suas pesquisas avançadas, destacam-se a Universidade Federal do Rio Grande do Sul, a Universidade de São Paulo e a Universidade Federal do Rio de Janeiro. A Petrobrás também, em 1999, implementou esta solução.
Dentre as vantagens do uso dos clusters Beowulf, Pitanga (2005) destaca algumas:
a) Como o agregado pode ser constituído de computadores com hardware heterogêneo, ou seja, independente de marca ou modelo, isso acaba reduzindo drasticamente o custo e facilitando muito a manutenção e expansão do cluster. Além disso, permite que o agrupamento evolua constantemente em termos de equipamento, acompanhando a evolução tecnológica, já que os componentes são comuns de serem encontrados no mercado;
b) Como não há um tipo de hardware específico ou uma quantidade de nós estipulada, o projeto fica totalmente flexível para ser adaptado de acordo com as necessidades e orçamento a ser empregado;
c) A facilidade de expansão desse tipo de cluster é outra grande vantagem;
d) Como cada nó é um computador independente, a vantagem oferecida pela alta disponibilidade também se encontra presente, já que se algum nó falhar, não afetará a disponibilidade do cluster.
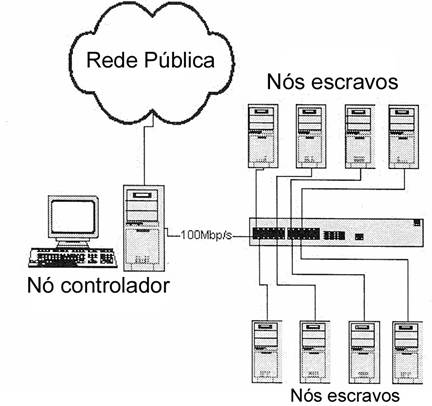
Figura 3. Exemplo de um Cluster Beowulf
Fonte: (PITANGA, 2005) Adaptado
Em termos de arquitetura, esse tipo de cluster se encaixa na taxonomia de Michael Flynn como MIMD (Multiple Instruction Multiple Data). Ele pode ser dito como um multicomputador ou hardware fracamente acoplado, onde se baseia no núcleo monolítico do Linux, e faz a comunicação entre nós através da troca de mensagens. A rede de comunicação desse cluster tem que ser exclusivamente usada para a passagem de mensagens relacionadas a execução de processamentos paralelos e seus nós também devem ser exclusivos para esse fim.
A arquitetura genérica de um cluster Beowulf é exemplificada na figura 3. Como observamos, o sistema é constituído de diversos nós, sendo um deles denominado nó controlador (ou front-end), que tem a função de gerenciar os demais nós do agrupamento, chamados de nós escravos (ou back-ends). O nó controlador se encarrega de distribuir as tarefas para os demais nós, além de realizar tarefas de cunho administrativo, como o monitoramento da disponibilidade dos nós do cluster. Além disso, ele também atua como a interface entre o usuário e o cluster. Em algumas implementações, o nó controlador atua como um servidor de arquivos, ou seja, ele compartilha diversos arquivos com os demais nós, evitando assim, a redundância de informação e facilitando também o processo de atualização de bibliotecas de programação e demais arquivos envolvidos no sistema, já que a mudança no servidor afetaria automaticamente todos os nós que se utilizam desse mesmo compartilhamento de dados. O Network File System (NFS) é muito usado nesse tipo de cluster para a implementação do compartilhamento de arquivos. Vale ainda ressaltar que os nós escravos são exclusivamente dedicados para realizar o processamento de tarefas enviadas pelo nó controlador. Além disso, o próprio nó controlador pode ser usado para realizar parte do processamento. A comunicação entre o nó controlador e os nós escravos poderá ser feita através de protocolos e serviços de acesso remoto, como o SSH.
Um grande fator, que contribui ainda mais para a redução de custos da implementação desse tipo de cluster é que os nós escravos não necessitam de teclados, monitores e em alguns casos nem mesmo de disco rígido.
O cluster Beowulf será o tipo de cluster utilizado nesse trabalho, por ter fácil acessibilidade de hardware, pelo fato de utilizar softwares livres, sem nenhum custo, e por ser muito difundido no meio científico e acadêmico, como citado anteriormente.
Segundo Pitanga (2005), Apesar de todas as vantagens e características favoráveis apresentadas, os clusters Beowulf possuem algumas desvantagens, dentre elas:
a) Não é qualquer tipo de aplicação que pode ser paralelizada;
b) A programação para esse tipo de sistema é complexa;
c) A latência e largura de banda da rede de comunicação do cluster são os fatores que mais afetam o desempenho, tornando-se o gargalo do processamento;
d) A implementação, administração e manutenção do cluster exige uma experiência considerável na área de redes de computadores.
AMBIENTES DE PROGRAMAÇAO PARALELA
Segundo Dantas (2005), a programação de qualquer tipo de aplicativo sempre deve considerar os requisitos do ambiente que será executado, para poder assim, explorar ao máximo as capacidades e configurações computacionais disponíveis. No tocante a programação para ambientes paralelos e distribuídos, a complexidade é maior do que na programação para ambientes centralizados. Nesses ambientes para clusters, como os recursos estão alocados entre diversos nós, torna-se mais complexa a programação. Além disso, diversos fatores devem ser considerados quanto a implantação do sistema, dentre eles: o acoplamento fraco entre os computadores; o retardo da rede de comunicação entre os computadores e a heterogeneidade de hardware, sistemas operacionais e linguagens de programação.
Para o desenvolvimento de aplicações voltadas para clusters paralelos, existem diversos modelos ou ambientes de programação, como o Parallel Virtual Machine (PVM) e o Message Passing Interface (MPI). Ambos serão explicados logo a seguir.
Parallel Virtual Machine (PVM)
O projeto PVM surgiu em 1989 no Laboratório Nacional de Oak Ridge. O protótipo do sistema, o PVM 1.0, foi construído por Vaidy Sunderam e Al Geist; essa versão do sistema foi usada internamente no laboratório e não foi lançado externamente. A versão 2 do PVM foi escrita pela Universidade de Tennessee e foi liberada em março de 1991. Durante o ano seguinte, o PVM passou a ser usado por muitas aplicações científicas. Depois de receber opiniões dos usuários e de muitas mudanças, o PVM foi totalmente reescrito, e a versão 3.0 foi finalizada em fevereiro de 1993. Esse pacote de software é distribuído gratuitamente e é usado em aplicações computacionais em diversas partes do mundo. Ele é compatível com diversas plataformas, como o Unix, Linux e Windows. (GEIST, 1994).
Segundo Dantas (2005), o PVM oferece uma série de facilidades para programação em ambientes paralelos, com a existência de um sistema transparente de adição de novos nós no agregado, sendo máquinas tanto de arquiteturas homogêneas quanto heterogêneas.

Figura 4. Estrutura do PVM
Fonte: (DANTAS, 2005) Adaptado
O PVM é constituído de duas funções, sendo representadas em duas camadas, como na figura 4. A camada superior, biblioteca PVM, é utilizada dentro de uma linguagem de programação, permitindo assim, que os programadores desenvolvam aplicações paralelas fazendo-se uso do ambiente distribuído de uma forma totalmente transparente, ou seja, sem se preocupar com a localização física dos nós.
Já a outra camada, que consiste no ambiente paralelo computacional (PPE – Parallel Programming Environment), é composto de um conjunto de mecanismos que permite, à camada superior, usufruir facilmente dos recursos de interligação e gerenciamento de conexões entre os nós do cluster.
Em suma, deve ficar claro que o PVM é constituído por dois módulos. O primeiro módulo é a biblioteca, que representa o ambiente de programação, ou seja, é a biblioteca de troca de mensagens entre os nós que deverá ser incluída e usada dentro de alguma linguagem de programação. Já o outro módulo do PVM é formado por mecanismos que implementam um ambiente paralelo. É esse módulo que cria, para os usuários das aplicações, uma abstração de uma única máquina virtual paralela. Ele fornece também um console que faz uma interface entre o usuário e a máquina virtual paralela, gerencia as conexões lógicas entre os nós do ambiente, realiza o balanceamento e escalonamento de carga dos processos que são enviados para o ambiente virtual paralelo, dentre outras funções mais necessárias para o funcionamento do sistema.
Message Passing Interface (MPI)
O MPI é um padrão de biblioteca de passagem de mensagem que foi desenvolvida para a comunicação entre processos em ambientes distribuídos. Como existem diversos tipos de bibliotecas para troca de mensagens em programação paralela, o MPI foi criado com intuído de estabelecer um padrão para facilitar assim, uma maior compatibilidade e portabilidade entre diferentes tipos de plataformas de sistemas operacionais e de hardware. (PITANGA, 2003)
Segundo MPI-Forum (2006), esse padrão foi desenvolvido por um grupo constituído de empresas envolvidas na produção e comercialização de aplicações de alto desempenho, de diversos centros de pesquisas e universidades de renome, que necessitavam e utilizam diariamente, aplicações distribuídas paralelas de grande complexidade e exigência computacional.
Segundo Pitanga (2003), o processo de padronização da biblioteca iniciou-se durante um seminário em 29 de Abril de 1992, na cidade de Williamsburg, estado de Virginia. Nesse evento, os recursos e características fundamentais foram explanados e ajustados e, além disso, foi estabelecida uma equipe que iria dar continuidade aos trabalhos.
O MPI estabelece um conjunto de rotinas que visam facilitar a comunicação entre processos dos nós em um sistema distribuído. Ele tem uma excelente portabilidade entre qualquer tipo de arquitetura e é composto por mais de 125 funções para serem utilizadas na programação de aplicações e também ferramentas para se aferir a performance do sistema como um todo. Essa biblioteca é compatível com linguagens de programação C/C++ e Fortran 77/90. Existem diversas implementações do MPI, dentre elas, o MPI Chameleon (MPICH, 2006) , MPI-F, LAM, MPL e o CHIMP.
Vale ressaltar também que o MPI possui um mecanismo muito bem elaborado de portabilidade e independência de plataforma computacional. Um programa feito com MPI, desenvolvido para um ambiente de arquitetura IBM-RS-6000 usando o AIX como sistema operacional, pode ser executado em outro ambiente diferente, como no SPARC com o Solaris de sistema operacional ou então num computador pessoal com Linux, com pequenas ou até mesmo nenhuma modificação no código-fonte da aplicação.
Um detalhe que deve ser notado no padrão MPI, é que ele foi implementado somente no nível de biblioteca de troca de mensagens. Comparando-se com o PVM, é como se o MPI possuísse somente aquela primeira camada, que se refere somente a biblioteca de programação. O MPI não implementa o ambiente virtual paralelo, como ocorre no caso do PVM (segunda camada). Por esse motivo, a biblioteca MPI pode ser executada em qualquer tipo de ambiente computacional paralelo, inclusive no próprio PVM (neste caso, somente a segunda camada, que cria o ambiente paralelo, seria usada, já que a primeira camada seria suprida pelo MPI).
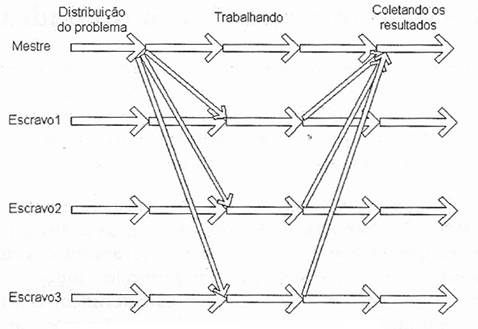
Figura 5. Modelo de execução do MPI
| Página anterior | Voltar ao início do trabalho | Página seguinte |
|
|
|




