 Página anterior Página anterior | Voltar ao início do trabalho | Página seguinte  |
Fonte: (PITANGA, 2003)
A execução de um programa que faz uso da biblioteca MPI inicia-se com um procedimento que dispara, através de um processo "pai", os processos "filhos" entre os nós constituintes do cluster. Um exemplo é demonstrado conforme a figura 5.
Cada um desses processos executantes nos nós comunica-se com as demais instâncias, possibilitando assim, a execução em vários processadores dos vários nós do cluster, aumentando assim a performance de processamento. Essa comunicação entre os processos "filhos" e o "pai" consiste basicamente em enviar e receber dados de um processador para outro. Esta comunicação ocorre através de uma rede de comunicação de dados de alta velocidade, onde o sistema distribuído foi construído.
Os dados enviados por essa biblioteca, entre os processos, são compostos de várias informações, tais como: identificação do processo emissor e receptor, o endereço inicial de memória que contém os dados que deverão ser transmitidos e a identificação dos grupos de processos que poderão receber a mensagem. Todos esses dados deverão ser definidos no desenvolvimento do aplicativo que faz uso dessa biblioteca, ficando todo encargo de identificar o paralelismo e usar as funções do MPI nas mãos do programador.
Os clusters computacionais possuem diversas áreas de aplicação, como foi explanado no capítulo 3.3. Algumas dessas áreas usam os clusters para prover alta disponibilidade, outras, para balanceamento de carga e em diversos outros casos, para usufruir de um alto poder computacional (HPC).
Pitanga (2003) observa que, dentre as diversas áreas de aplicação, os diversos ramos da computação gráfica tem usufruído muito dos clusters de alta performance, principalmente pelo seu vantajoso equilíbrio entre custo e benefício. O uso de agrupamentos de computadores tem se destacado principalmente no uso de atividades relacionadas com a renderização de imagens e cenas artificiais realísticas.
Nesse projeto, para fazer a avaliação de performance de processamento em um cluster de computadores, serão renderizadas cenas artificiais, aplicando-se a técnica de renderização de imagens denominada Ray-tracing, que será explicada logo mais, no capítulo 4.1.2.
RENDERIZAÇAO DE IMAGENS
Com a geração de imagens e cenas cinematográficas artificiais cada vez mais próximas da realidade, o processo de renderização tem exigido, de um modo crescente, maior poder computacional. Como as cenas artificiais realísticas são muito complexas, com inúmeros parâmetros e detalhes, o processo de renderização exige um conjunto de cálculos extremamente massivos.
Antes de abordar sobre a técnica de renderização de imagens que será utilizada nesse trabalho, serão pincelados alguns conceitos básicos de computação gráfica, visando assim, facilitar o entendimento da técnica de Ray-tracing.
Alguns conceitos de computação gráfica
Segundo Azevedo (2003), a computação gráfica é definida como uma arte aliada a matemática. Ela é um meio para se criar artes, assim como um lápis ou um instrumento musical, fornecendo uma grande abstração para a criação de imagens complexas.
A relação entre luz, tempo e movimento constitui a base desta que poderia ser classificada como uma arte tecnológica. A computação gráfica pode ser encarada como uma ferramenta não convencional que permite ao artista transcender das técnicas tradicionais de desenho ou modelagem. Imagens que exigiriam do artista o uso de uma técnica apurada de desenho podem ser geradas mais facilmente com o auxilio de softwares. (AZEVEDO, 2003, p. 03)
Como é observada, a computação gráfica abre novos rumos no ramo das artes, possibilitando a criação de imagens que seriam muito mais complexas (ou até impossíveis) de serem criadas manualmente.
Para a renderização de imagens (principalmente as cenas realísticas), são consideradas diversos aspectos do ambiente, principalmente no tocante aos sombreamentos e iluminação global das cenas.
Sombreamento (Shading)
De acordo com Azevedo (2003), para a criação de uma cena realística através da computação gráfica, o tratamento da luz sob a cena tem um papel fundamental. Os efeitos gerados pela incidência e reflexão da luz, criando assim, superfícies de tonalidades e orientações diferentes, são as peças-chave para o sucesso na geração de uma imagem próxima da realidade.
Uma observação importante que deve ser considerada é que um modelo de sombreamento não é sinônimo de um modelo de iluminação, mas sim o processo de se aplicar um modelo de iluminação nos pontos de uma superfície que é chamado de sombreamento.
Diversos modelos de iluminação diferentes foram criados para manipularem e expressarem, de acordo com o conjunto de reflexão de luz, a cor e intensidade de luz das superfícies. Alguns desses modelos calculam o efeito de luz para cada pixel (elemento mínimo de uma tela gráfica) da imagem. Já outros modelos calculam o efeito da luz incidente para um conjunto de pixels, através de interpolação.
Como a criação de um modelo completo e abrangente é muito complexo (por envolver muitas regras da física óptica e da física das radiações), os programadores acabaram criando modelos de iluminação simplificados, com bons resultados práticos, porém sem nenhuma fundamentação.
No modelo de sombreamento constante, o cálculo da luz refletida é calculada uma vez para cada superfície plana da imagem, usando-se um único valor de cor e intensidade de luz refletida para preencher toda a superfície da imagem. Esse modelo é mais usado para geração de figuras primitivas, pois não apresenta um nível de realismo satisfatório.
Já em 1971, Henri Gouraud criou um modelo de sombreamento alternativo a esse modelo constante. Esse método calcula a iluminação em um subconjunto de pontos de cada superfície da cena, e a intensidade dos demais pontos de cada uma dessas superfícies é calculada por meio da interpolação. Os vértices que compõem cada uma das faces da superfície plana do objeto são usados para realizar o calculo da reflexão da luz, que por sua vez, através de interpoladores lineares, são calculadas as intensidades de reflexão nos demais pontos da mesma superfície. Quando as normais de vértice não estão presentes, calcula-se a normal através da média das normais das faces que são adjacentes a essa superfície.
No sombreamento de Gouraud, que também é conhecido como intensity interpolation shading ou color interpolation shading, ele interpola linearmente a intensidade de luz refletida, de forma a eliminar a quebra brusca de intensidade de cor ao longo das superfícies, que normalmente são complexas.
Um ponto negativo desse modelo é que ele não pode ser aplicado, com resultados satisfatórios, em superfícies onde no modelo real não é uma figura plana.
Um outro modelo de sombreamento muito utilizado é o modelo de Phong, criado por Bui-Tuong Phong. Ao contrario do modelo de Gouraud, esse modelo interpola a variação do ângulo de incidência dos feixes de luz sobre a superfície do objeto, determinando assim, diversos pontos de reflexão para uma mesma superfície plana. Ele calcula a normal para cada ponto da superfície plana, através da interpolação das normais dos vértices dessa superfície respectiva. Tendo a normal para cada ponto, é feito o cálculo do sombreamento para cada um desses pontos, representando assim com maior realismo, os pontos da superfície, gerando conseqüentemente um melhor resultado que no modelo de Gouraud.
Modelos de Iluminação Global
Segundo Azevedo (2003), a iluminação global é a melhor técnica para se obter resultados mais próximos da realidade. Todas as técnicas que levam em conta todos os feixes de luz emitidos numa cena, incluindo as oriundas de fontes indiretas, se encaixam nessa categoria. Por exemplo, numa cena que é iluminada pelos raios solares, o ambiente também sofrerá influência da luz azulada refletida pelas nuvens. E essa influência é levada em conta na renderização de imagens usando-se de modelos de iluminação global.
Essas técnicas exigem um maior poder computacional, por elevar consideravelmente a quantidade de cálculos a serem feitas. Porém, com a evolução e popularização dos clusters de computadores e os supercomputadores, o tempo de cálculo dessas técnicas de iluminação global tem diminuído consideravelmente, tornando-se muito usado nos dias de hoje no mundo da computação gráfica. Dentre as técnicas que aplicam o modelo de iluminação global, podemos citar o Ray-tracing, que será explicado no capítulo 4.1.2.
Existem diversos softwares que trabalham com o modelo de iluminação global para a geração de imagens artificiais, dentre eles o PovRay (emprega a técnica de Ray-tracing) que é muito utilizado principalmente no meio acadêmico.
Técnica de Ray-tracing
Segundo Lopes (2004), existem vários algoritmos de Ray-tracing, que foram desenvolvidos a partir de um modelo-base, criado em 1968. Esses algoritmos são muito usados para a geração de imagens artificiais e aplicam o modelo de iluminação global.
O Ray-tracing é um método de geração de imagens a partir de descrições geométricas de um conjunto de objetos que compõem a cena, levando-se em conta a modelagem dos raios de luz. Com essa técnica, ficou bem mais fácil a criação de cenas complexas, já que não é necessário ter a habilidade de pintura ou desenho. (PITANGA, 2003).
De acordo com Azevedo (2003), inicialmente essa técnica foi implementada para simular trajetórias de projéteis balísticos e partículas nucleares e mais adiante foi apresentada pela empresa Apple como uma ferramenta para calcular sombras na área de computação gráfica. Como o poder de processamento dos computadores da época era insuficiente, tornou-se inviável o uso do Ray-tracing.
Porém, com a grande evolução de processamento, barateamento dos computadores e o surgimento e popularização dos clusters computacionais, a implementação de algoritmos que fazem uso de modelos de iluminação global passaram a ser uma opção muito viável. Nesse momento, o algoritmo de Ray-tracing voltou a ser estudado e acabou sendo expandido e implementado. Em 1980 ele teve sua primeira implementação já com diversos efeitos, como sombra, reflexões e transparência. E depois, em 1984, ele foi incrementado ainda mais, possibilitando a geração de imagens com mais efeitos, como o de penumbra. Nos dias atuais, o Ray-tracing é uma das técnicas de sintetização de imagens mais usadas e poderosas existentes, tendo também como destaque, sua fácil implementação. Qualquer tipo de cena, seja simples ou complexa, com muitos efeitos e objetos, poderá ser gerada através dessa técnica.
Funcionamento do algoritmo clássico
De acordo com Pitanga (2003), o Ray-tracing gera um modelo matemático da imagem artificial, tendo o observador da cena como o centro de projeção. Ao contrário do que ocorre na física óptica, os raios de luz não partem dos objetos em direção aos olhos, mas sim dos olhos do observador e vão até os objetos que se deseja renderizar, como demonstrado na figura 6. Essa inversão foi feita para se economizar tempo computacional, já que somente os raios que realmente atingem o campo de visão do observador serão considerados, desprezando os demais raios refletidos no ambiente que não são captados. Dessa perspectiva, Azevedo (2003) afirma que, de acordo com as leis da óptica, essa inversão não provoca nenhuma alteração na geometria da cena.
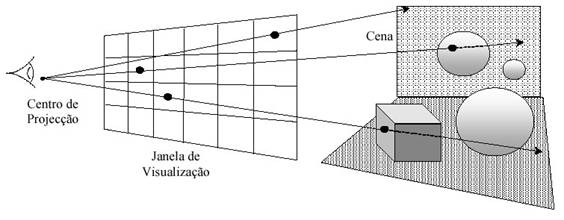
Figura 6. Geometria do Ray-tracing
Fonte: (LOPES, 2004)
De acordo com Azevedo (2003), os raios traçados que interessam para a renderização da cena, podem ser mapeados de volta para o objeto e a partir deste, para cada uma das fontes de luz. Desse modo, observamos na figura acima, que é inserido uma tela entre o observador (centro de projeção) e a cena. A partir disso, são traçados os raios da visão do observador até cada ponto da tela (ou janela), e dessa tela, para os objetos da cena que são atingidos pelas fontes de luz. Nessa tela onde os raios "atravessam" em direção aos objetos, serão associados as cores e as respectivas intensidades desses objetos da cena que o raio atinge, gerando assim, uma imagem artificial da cena nessa janela de visualização.
No algoritmo de Ray-tracing, diversos pontos são levados em conta:
a) Cada um dos raios disparados correspondem a um ponto na tela;
b) Ao ser lançado um raio, este poderá atingir um objeto ou, caso contrário, ser desconsiderado da cena;
c) Caso atingir um objeto, será calculo o ponto de intersecção entre ele e o respectivo objeto. Além disso, será calculada a influência das fontes de luz para cada um dos pontos, como a sombra gerada por outros objetos, por exemplo;
d) Caso o objeto seja opaco, será levada em conta somente a intensidade luminosa total em cada um dos pontos correspondentes. Caso contrário, as influências de reflexão e refração da superfície serão consideradas;
e) Até aqui, o ponto na tela já poderá ser exibido. Caso o raio de algum ponto não tenha intersecção com nenhum objeto da cena, ele terá a cor de fundo.
Azevedo (2003) salienta ainda que o algoritmo clássico de Ray-tracing é muito simples, porém exige um poder computacional considerável, já que são efetuados diversos cálculos para cada um pontos da tela. E como uma cena é constituída por uma grande quantidade de pontos, conseqüentemente a quantidade de cálculos também é grande. As seguintes etapas são executadas, para cada um desses pontos:
a) Traçar um "raio" do observador até a cena, passando por um dos pontos da tela;
b) Determinar qual é o primeiro objeto (mais próximo da tela) que é atingido por esse raio;
c) Calcular a cor da superfície do objeto, no ponto onde ocorreu a intersecção com o raio traçado, levando-se em conta a luz ambiente e as propriedades do material do objeto;
d) Se essa superfície for reflexiva, calcular um novo raio do ponto de intersecção que vai em direção ao ângulo de reflexão;
e) Se a superfície for transparente, calcular um novo raio partindo do ponto de intersecção, até atingir outro objeto logo atrás;
f) Determinar a cor do ponto e se há sombras através de valores obtidos com consideração da cor de todos os objetos que foram interceptados pelo raio até sair da cena ou até atingir alguma fonte de luz;
Baseando-se nessas etapas, o algoritmo é descrito por Azevedo (2003, p. 299) da seguinte forma:
Considerando um centro de projeção, no plano de visão
Para (cada linha horizontal de varredura da imagem)
{ Para (cada ponto da linha de varredura)
{ determinar raio que vai do centro de projeção ao ponto
Para (cada objeto da cena)
{ Se (objeto for interceptado pelo raio &&
é a intersecção mais próxima até agora)
registrar intersecção e o objeto interceptado
}
atribuir ao ponto a cor do objeto da intersecção mais próxima
}
}
Como visto no algoritmo, não é levada em conta apenas a cor inerente de cada um dos objetos da cena, mas também os efeitos de refração e reflexão da luz que são provocados por suas superfícies. A criação de imagens refletidas é gerada através da soma dos valores de cores obtidas por cada intersecção do raio com o objeto ou fonte de luz. Toda vez que o coeficiente de reflexão de uma superfície de um objeto for diferente de zero, o Ray-tracing leva em consideração na geração da cena. Esse coeficiente pode variar entre 0 e 1, representando a quantidade de luz que é absorvida pela superfície, fazendo parte também no cálculo da cor de cada ponto da tela. Uma superfície que possuir esse coeficiente próximo de 1, é porque reflete praticamente toda luz incidente (não absorve praticamente nada), atuando como um espelho. Além desse coeficiente, é considerado também o de refração, que representa o grau de transparência do objeto, ou seja, a maneira como a luz passa através dela, atingindo um outro meio ou objeto.
Em suma, o que o algoritmo de Ray-tracing faz, é calcular a intersecção de uma semi-reta, denominada de raio, para cada um dos objetos que constituem a cena. Somente os raios que atingirão o observador serão levados em conta nos cálculos. Como afirmado anteriormente, como esse algoritmo realiza diversos cálculos massivos para cada um dos pontos da cena, a exigência de um poder computacional elevado se torna necessário, principalmente para a geração de cenas artificiais com um nível elevado de complexidade.
Para a realização da avaliação de performance de processamento do cluster, foram realizados diversos testes de renderização de imagens em Pov-Ray através de um ambiente específico de agregado de computadores, comparando assim os resultados obtidos do cluster com os provenientes dos mesmos testes de renderização realizados em um único computador.
Os resultados esperados eram de que o desempenho do cluster na renderização de imagens fosse superior ao desempenho de um único computador realizando a mesma atividade. Além disso, foi esperado que, a cada nó acrescentado no cluster, ocorresse um ganho de desempenho do processamento do agregado de computadores como um todo.
Neste capítulo, primeiramente será exposto o ambiente onde os testes foram realizados. Mais adiante, será explanada a metodologia utilizada para a realização dos experimentos e por final, serão apresentados os resultados obtidos.
AMBIENTE
Os experimentos realizados foram executados utilizando-se o cluster Beowulf, juntamente com um computador individual, para realização da avaliação de performance de renderização entre ambos. O Beowulf foi a opção escolhida por diversas vantagens e facilidades que ele oferece, principalmente em relação a fácil acessibilidade de hardware e o uso de softwares livres, assim como outras vantagens mais citadas anteriormente na seção 3.5.3.5.
Ainda de acordo com o que foi explanado na seção 3.5.3.5, para a implementação do cluster Beowulf, foram utilizados computadores comuns (PCs), interligados por uma conexão e dispositivos de rede comuns, e todos os nós usando o Linux como sistema operacional. Foi utilizado o Pov-Ray para a renderização de imagens, em conjunto com a biblioteca de programação paralela MPICH, citada na seção 3.6.2. Para que a renderização de imagens via Pov-Ray fosse possível de ser executada no cluster, utilizou-se o MPIPOV (MPIPOV, 2006), que se trata de uma atualização (Patch) que é aplicada ao Pov-Ray, possibilitando assim, a renderização de imagens em Pov-Ray de forma paralela/distribuída, via MPICH, através do cluster Beowulf.
A comunicação entre o nó controlador e os escravos foi implementada através do SSH, utilizando-se autenticação com chave assimétrica, para remover assim, a necessidade de autenticação por senha manualmente digitada. Com isso, o nó controlador passou a enviar mensagens e comandos aos nós escravos, sem que uma senha fosse exigida. Foi mantido o uso do SSH (que é o padrão do ambiente disponibilizado) pelo fato do cluster não estar situado em uma rede isolada, exclusivamente para este fim.
Além disso, para facilitar a manutenção das bibliotecas de programação e demais aplicações e arquivos dentre os nós do cluster, três diretórios foram compartilhados no nó controlador, via NFS, para os demais computadores: /home /usr /root. Ambos foram compartilhados no modo assíncrono, com permissão de leitura/escrita. A configuração de compartilhamento do servidor e o mapeamento nos nós clientes se encontram no apêndice A.
Para o monitoramento e gerenciamento do cluster, foi utilizado o Smile Cluster Management System (SCMS, 2006), produzida pela Universidade de Kaserstart, em Bangkok na Tailândia. Com esta ferramenta, foi possível acompanhar o uso de CPU e memória de todos os nós do cluster, bem como o alerta em caso de falha de algum nó. Esse programa ficou instalado no nó controlador.
Segue na quadro 1, os softwares e bibliotecas que foram utilizados na implementação de todos os nós do cluster Beowulf em questão:
|
Nome |
Versão |
|
|
Pov-Ray |
3.1g |
|
|
MPI Chameleon |
1.2.5.2 |
|
|
Network File System (NFS) Protocol |
4.0 |
|
|
Secure Shell (OpenSSH) / Protocolo |
4.2p1 / 1.0 |
|
|
Smilie Cluster Management System |
1.2.2 |
|
|
POVMPI |
1.0 |
|
|
GCC/G++ |
3.3.6 |
|
Quadro 1. Softwares e bibliotecas utilizadas no cluster
Quanto ao uso sistema operacional Linux, foram utilizadas as seguintes configurações:
a) Nó controlador: Slackware Linux 10.2, com Kernel 2.4.31
b) Nós escravos: Slax Linux 5.1.8, com Kernel 2.6, com boot direto por CD, e carregamento do sistema todo em memória RAM de cada um dos nós, sem o uso de memória virtual (swap) e sem o uso do disco rígido.
A topologia virtual da rede de comunicação de dados do cluster ficou com a disposição em estrela, conforme a figura 7.
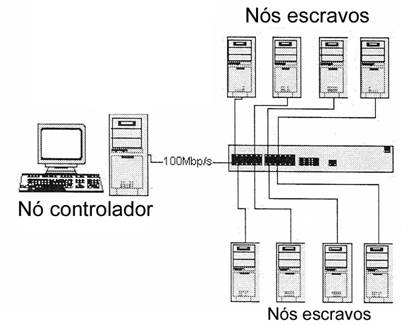
Figura 7. Topologia do cluster em questão
Fonte: (PITANGA, 2005) Adaptado
O agregado foi composto de um total de 9 nós, sendo um nó o controlador e os demais, escravos. O nó controlador atuou no monitorando dos demais nós, bem como no gerenciamento, distribuição e sincronização das mensagens. O encargo do processamento de renderização ficou somente para os nós escravos.
|
Placa mãe |
Intel 810 |
|
|
Processador |
Intel Celeron 1.1 Ghz / 128Kb Cachê L2 |
|
|
Memória |
256 Mb 133Mz CL 3 |
|
|
Disco rígido |
IDE 40Gb de 7.200 Rpm |
|
|
Placa de vídeo |
Intel 810 / 16Mb compartilhado |
|
|
Placa de rede |
Intel 810 / Fast Ethernet |
|
Quadro 3. Hardware do nó controlador
O dispositivo concentrador da rede utilizado foi um Hub da marca 3Com, modelo 3C16411 SuperStack 3, de 10/100 Mbits/s. A rede, padrão Fast Ethernet, atuou a 100 Mbits/s de largura máxima de banda, utilizando-se de cabeamento padrão 5E. Uma observação importante a ser feita, é que foi utilizado um hub ao invés de um switch pois era o único tipo de concentrador presente no ambiente disponível para a realização dos testes.
Quanto ao hardware dos nós, este cluster foi caracterizado como heterogêneo, pois foram usadas duas configurações diferentes. O quadro 2 demonstra a configuração do computador utilizado como nó controlador e no quadro 3, a configuração utilizada para os demais nós.
|
Placa mãe |
Intel 830 |
|
|
Processador |
Intel Celeron 2.4Ghz / 128Kb Cachê L2 |
|
|
Memória |
256 Mb 166Mhz CL 2.5 |
|
|
Disco rígido |
IDE 40Gb de 7.200 Rpm |
|
|
Placa de vídeo |
Intel 830 / 32Mb compartilhado |
|
|
Placa de rede |
Intel 830 / Fast Ethernet |
|
Quadro 4. Hardware dos nós escravos
Dentre os computadores utilizados no cluster, o de menor configuração de hardware foi utilizada para o nó controlador, pois as atribuições exigidas do controlador não exigiram muita carga de processamento e memória.
O computador individual que realizou o teste de renderização separado do cluster, possui a mesma configuração de hardware representada no quadro 3, bem como a mesma versão do Linux utilizada no nó controlador e conjunto de softwares constantes no quadro 1.
METODOLOGIA
Para que fosse possível avaliar a performance do cluster na renderização de imagens, e por conseguinte, comparar seu desempenho ao desempenho de um único computador, foi utilizado um guia de avaliação de performance (Benchmark) mencionado por Pitanga (2003). Segundo esse benchmark, foi utilizada uma imagem feita em Pov-Ray para realizar os testes e avaliação dos resultados. A imagem utilizada foi a skyvase.pov, cujo código-fonte encontra-se no anexo A.
A medida de desempenho consistiu, basicamente, na inferência do tempo que o sistema demorou para renderizar a imagem em questão na dimensão de 640x480 pixels e resolução de 16 milhões de cores. A avaliação de desempenho do cluster foi feita de forma gradativa, com a realização do benchmark a cada acréscimo de nós no cluster, verificando assim, o ganho de desempenho a cada passo do crescimento horizontal do sistema.
Além disso, segundo Povbench (2006), a imagem skyvase.pov também é mundialmente utilizada como benchmark de clusters computacionais e máquinas individuais na renderização de imagens em Pov-Ray, onde é mantido um ranking mundial, com os tempos de renderização obtidos por sistemas do mundo todo.
Os experimentos realizados neste trabalho, foram divididos em 9 etapas e consistiram na renderização da imagem skyvase.pov na dimensão de 640x480 pixels em 16 milhões de cores e anti-alising em 0.3, de acordo com os parâmetros de renderização usados pelo benchmark citado por Pitanga (2003) e Povbench (2006). Cada uma das etapas ficaram com as seguintes atribuições:
Etapa 1: Avaliação de performance na renderização da imagem em um único computador;
Etapa 2 à 9: Avaliação de performance na renderização da imagem já no cluster Beowulf, primeiramente com dois nós, e assim acrescentou-se mais nós gradativamente, sendo um novo nó adicionado a cada nova etapa, até ser atingido o quantitativo de 9 computadores agregados.
Em todas essas etapas, além da verificação do tempo de renderização consumido, foram monitorados o uso de processador e memória de cada um dos nós.
Por final, após serem avaliados os tempos de renderização consumidos pelo computador individual e pelo cluster Beowulf, foi feito um comparativo de desempenho entre ambos os casos. Além disso, também foi verificado e analisado o ganho de performance do cluster a cada nó acrescentado, além de ter sido verificada a proporção de divisão da carga de processamento da imagem feita pelo nó controlador para os nós escravos. O tempo de renderização e a divisão de carga entre os nós foi calculada pelo próprio patch MPIPOV, aplicado ao Pov-Ray.
RESULTADOS
Todos os experimentos foram realizados com sucesso. Na figura 8, é demonstrado o resultado da renderização da imagem skyvase.pov.

Figura 8. Resultado da renderização da imagem Skyvase.pov
Os seguintes resultados de performance de renderização foram obtidos, conforme seguem na tabela 1 e na figura 9.
Tabela 1. Resultado das performances obtidas nos testes
|
Etapa |
Tempo de processamento |
|
1 |
18 segundos |
|
2 |
19 segundos |
|
3 |
10 segundos |
|
4 |
7 segundos |
|
5 |
5 segundos |
|
6 |
4 segundos |
|
7 |
3 segundos |
|
8 |
3 segundos |
|
9 |
4 segundos |
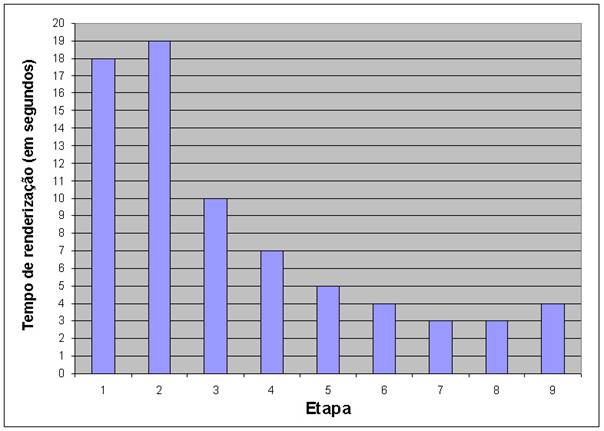
Figura 9. Resultado das performances obtidas nos testes
Tabela 2. Particionamento do problema entre os nós escravos
|
Etapa |
Porcentagem de balanceamento |
|||||
|
2 |
100% |
|||||
|
3 |
50,67% / 49,33% |
|||||
|
4 |
35% / 32,33% / 32,67% |
|||||
|
5 |
25,33% / 24,67% / 24,33% / 25,67% |
|||||
|
6 |
21% / 19,33% / 19,67% / 19,67% / 20,33% |
|||||
|
7 |
17,67% / 16,33% / 16% / 14,67% / 17,67% / 17,67% |
|||||
|
8 |
15% / 15,33% / 14,67% / 13,33% / 14,33% / 13,33% / 14% |
|||||
|
9 |
13,67% / 12,33% / 12,33% / 12% / 11,67% / 13,33% / 12% / 12,67% |
|||||
O uso do processador, na etapa 1, ficou em 100% constante, bem como nas demais etapas, em relação aos nós escravos. Já no nó controlador, em todas as etapas envolvendo o uso do cluster, o consumo do processador oscilou entre 62% e 81%. Em relação ao uso de memória RAM, na primeira etapa foram consumidos 2668 Kb. Já nas demais etapas, o consumo de memória em cada nó oscilou entre 890Kb e 960Kb.
A agregação de novos nós no cluster não alterou o consumo de processador e de memória RAM entre os escravos. Já no nó controlador, o consumo do processador cresceu sutilmente, a cada nó que foi sendo agregado ao cluster.
Na tabela 2, são demonstrados os resultados do particionamento da carga de renderização da imagem entre os nós escravos, efetuado pelo nó controlador.
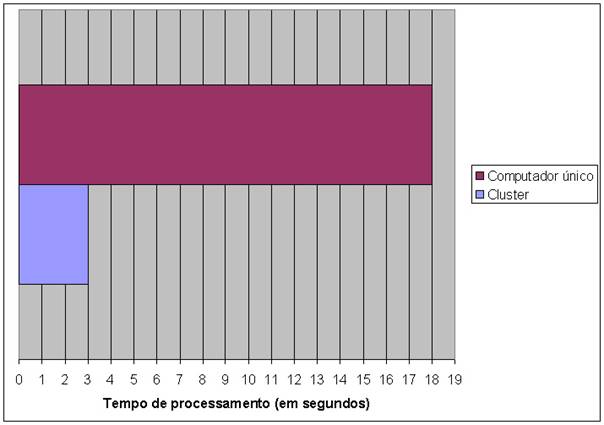
Figura 11. Desempenho do computador único X cluster (no melhor caso)
O desempenho na renderização da imagem, entre o computador único e o cluster (considerando o melhor caso de desempenho, que foi na etapa 7), é demonstrado na figura 10.
Na segunda etapa do teste, com a ativação do cluster, ocorreu uma queda do desempenho, em relação ao tempo de processamento gasto na primeira etapa, por apenas um único computador. Esse retrocesso ocorreu possivelmente pelo custo de comunicação entre o nó controlador e o escravo, já que o barramento de comunicação passou a ser a rede. Além disso, apesar de serem dois computadores, um apenas atuou no controle do cluster, ficando todo o encargo da carga de processamento para o nó escravo, conforme observado na tabela 2.
Já na terceira etapa, o desempenho do cluster começou a ser superior ao desempenho do computador individual, da etapa 1. Isso ocorreu porque a carga de processamento passou a ser dividida entre os dois nós escravos do cluster, realizando assim, o processamento de renderização da imagem de forma paralela, com uma distribuição de carga praticamente igual entre ambos. Esse ganho de desempenho ocorreu até a sétima etapa. Na oitava etapa, não houve ganho de desempenho em relação a etapa anterior, e na última etapa ocorreu um movimento retrógrado do ganho de desempenho do cluster. Uma das possíveis causas desses resultados das duas últimas etapas foi alta latência da rede de comunicação de dados do cluster, causada pelo aumento do fluxo de mensagens trafegando ao mesmo tempo e possivelmente agravado pelo fato da rede ser interconectada por um hub.
É extremamente importante observar que, como o tempo de renderização foi medido em segundos, por se tratar da precisão padrão oferecida pelo patch MPIPOV, pode ser que o tempo de renderização tenha sido diferente nas etapas 7 e 8, podendo ter ocorrido um ganho ou perda de performance na passagem de uma etapa para a outra.
Observou-se também que o ganho de desempenho do cluster, a cada acréscimo de um novo nó, não ocorreu de forma linear, proporcional a quantidade de computadores agregados. Isso ocorreu possivelmente pelo custo gerado para a quebra do problema em problemas menores, pelo custo da transmissão das mensagens entre os nós, bem como pelo custo do recebimento das mensagens e sua respectiva sincronia e junção para a obtenção do resultado global do problema.
Vale salientar também que o desempenho da renderização, nesse caso, independe do tipo de placa de vídeo utilizado, já que a execução da renderização foi realizada em terminal alfanumérico a partir do nó controlador, sem o uso de nenhum tipo de interface gráfica. Como resultado da renderização, é gerado um arquivo no formato TGA (Truevision Targa Format), com a imagem final renderizada.
Os clusters de computadores vêm sendo uma ótima opção de arquitetura computacional utilizada por diversas empresas, indústrias, faculdades, universidades e instituições de pesquisa, onde o alto poder de processamento e/ou alta disponibilidade são fatores fundamentais para a obtenção do êxito na execução de aplicações de grande porte computacional, principalmente onde o menor tempo de processamento possível é almejado. Como visto, existem diversos tipos de clusters computacionais, sendo cada um constituído por características específicas, abrindo assim, um leque de opções de implementação de clusters para diferentes tipos de ambientes.
Com este trabalho, concluiu-se que os clusters de computadores são uma maneira eficaz na obtenção de alto poder de processamento para a renderização de imagens, em relação a um único computador uniprocessado. O cluster Beowulf, utilizado nos testes, apresentou um desempenho de processamento satisfatório, demonstrando ser uma maneira eficaz e acessível de implementação de clusters, em relação ao hardware e softwares exigidos.
Verificou-se também que, o aumento no desempenho de processamento do cluster não cresceu de forma linear, a cada novo computador acrescentado ao agregado. Além disso, constatou-se que esse ganho de performance possui um certo limite, a uma determinada quantidade de nós para um determinado tipo de ambiente de implementação. Sendo ultrapassado esse limite de nós, verificou-se que o desempenho começa a degradar-se, como ocorreu nos testes realizados neste trabalho.
Devido a isso, é importante ressaltar que, não adianta montar um cluster e colocar muitos nós, de forma arbitrária. Para obter-se o máximo desempenho de um cluster, deve-se avaliar a performance do sistema a cada nó acrescentado, para determinar assim, a quantidade de nós máxima ideal para a resolução de um determinado problema em um determinado ambiente de implementação, evitando-se assim, a degradação de desempenho.
TRABALHOS FUTUROS
Para trabalhos futuros, poderá ser avaliado o desempenho do cluster em termos da rede de comunicação de dados. Poderão também serem analisados o consumo de banda e latência da rede, bem como realizar testes comparativos de desempenho do cluster com o uso dos diversos tipos de padrões de redes, como o Gigabit Ethernet e também dispositivos de interconexão, como o hub e switch. Além disso, poderão ser realizados testes comparando o desempenho do sistema com o uso do shell remoto criptografado (SSH) e com o uso do não criptografado (RSH), em relação a comunicação entre os nós.
Poderia também ser feito um estudo comparativo entre os diversos tipos de clusters de computadores existentes, fazendo-se uma análise em diversos aspectos, principalmente em relação ao desempenho de processamento para alguma atividade em específico.
Também seria interessante a realização de uma pesquisa e implementação/modificação da biblioteca MPICH, de modo que a carga de processamento distribuída pelo nó controlador para os nós escravos, não seja dividida proporcionalmente a quantidade de nós disponíveis, mas sim de forma proporcional aos recursos de processamento e memória disponíveis no sistema, aproveitando assim, ao máximo, o desempenho dos nós e evitando problemas de equilíbrio de carga de processamento em clusters onde são utilizados computadores de diversas configurações de hardware ou disponibilidades de recursos de processamento e memória diferenciados em determinados instantes.
AZEVEDO, E.; Conci, A. Computação gráfica – Teoria e prática. Rio de Janeiro: Campus, 2003. 353 p.
BOOKMAN, C. Agrupamento de computadores com linux. Rio de Janeiro: Ciência Moderna, 2003. 240 p.
DANTAS, M. Computação distribuída de alto desempenho. Rio de Janeiro: Axcel, 2005. 278 p.
DOE-GENOMES, 2003. Genome programs of the U.S. Department of Energy. Disponível em < http://doegenomes.org/> . Acesso em: 02 jun. 2006.
GEIST, Al et al. PVM: parallel virtual machine. A Users" Guide And Tutorial For Networked Parallel Computing. 1994. Disponível em < http://www.netlib.org/pvm3/book/pvm-book.html>, Acesso em: 13 de maio 2006.
KUROSE J. F.; ROSS W. K. Redes de computadores e a Internet. Uma abordagem top-down. 3. ed. São Paulo: Pearson, 2006. 634 p.
LINUX-HA, 1999. The high-availability linux project. Disponível em < http://linux-ha.org/>, acesso em: 02 de jun. 2006.
LOPES, J. M. B, 2004. Ray tracing. Disponível em < http://mega.ist.utl.pt/~ic-cg/programa/livro/Raytracing.pdf>. Acessado em: 23 de mar. 2006.
MPICH, 2006. MPICH. A Portable Implemention of MPI. Disponível em < http://www-unix.mcs.anl.gov/mpi/mpich1/>, Acesso em: 5 de mar. 2006.
MPI-FORUM, 2006. Message passing interface forum. Disponível em < http://www.mpi-forum.org/>, Acesso em: 20 de mai. 2006.
MPIPOV, 2006. MPI-Povray. Distributed Povray using MPI message passing. Disponível em < http://www.verrall.demon.co.uk/mpipov/>, Acesso em: 04 de jul. 2006.
MYSQL-CLUSTER, 2006. MySQL cluster. Disponível em < http://www.mysql.com/products/database/cluster/>, Acesso em: 02 de jun. 2006.
OPENMOSIX, 2006. OpenMosix project. Disponível em < http://openmosix.sourceforge.net/>, Acesso em: 09 mai. 2006.
PITANGA, M. Construindo supercomputadores com linux. Rio de Janeiro: Brasport, 2003. 183 p.
PITANGA, M. Computação em cluster – O Estado da Arte da Computação. Rio de Janeiro: Brasport, 2005. 322 p.
POVBENCH, 2006. POVBENCH - The Official Home Page. Disponível em < http://www.haveland.com/index.htm?povbench/ >, Acesso em: 03 de jul. 2006.
RIBEIRO, Uirá. Sistemas distribuídos. Desenvolvendo aplicações de alta performance no Linux. Rio de Janeiro: Axcel Books do Brasil, 2005. 384 p.
SCMS, 2006. SAL- Parallel Computing - Misc – SCMS. Disponível em < http://www.ceu.fi.udc.es/SAL/C/0/SCMS.html>. Acesso em: 08 mar. 2006.
SETI@HOME, 2006. Disponível em < http://setiathome.ssl.berkeley.edu/>. Acesso em: 20 mai. 2006.
SLOAN, J. D. High performance linux clusters - with Oscar, Rocks, OpenMosix & MPI. Gravenstein Highway North, Sebastopol: O"Reilly, 2004. 350 p.
SUN, 2006. Solaris MC. Disponível em < http://research.sun.com/techrep/1995/annualreport95/solarisMC.html>, Acesso em: 02 mai. 2006.
TANENBAUM, A. S. Organização estruturada de computadores. Rio de Janeiro: Prentice/Hall do Brasil, 1992.
TANENBAUM, A. S. Redes de computadores. 4. ed. Rio de Janeiro: Campus, 2003. 945 p.
WIKIPEDIA, 2006a. Network file system. Disponível em: < http://en.wikipedia.org/wiki/Network_File_System>. Acesso em: 25 mai. 2006.
WIKIPEDIA, 2006b. Secure shell. Disponível em: < http://en.wikipedia.org/wiki/Ssh>. Acesso em: 25 mai. 200
APÊNDICE A
# Arquivo /etc/exports localizado no nó controlador
#
# See exports(5) for a description.
# This file contains a list of all directories exported to other computers.
# It is used by rpc.nfsd and rpc.mountd.
/home 10.0.0.0/16(no_root_squash,rw)
/usr 10.0.0.0/16(no_root_squash,rw)
/root 10.0.0.0/16(no_root_squash,rw)
# Arquivo /etc/fstab usado nos nós escravos
#
tmpfs / tmpfs defaults 0 0 # AutoUpdate
devpts /dev/pts devpts gid=5,mode=620 0 0 # AutoUpdate
proc /proc proc defaults 0 0 # AutoUpdate
/dev/hda /mnt/hda_cdrom iso9660 noauto,users,exec 0 0 # AutoUpdate
/dev/sda1 /mnt/sda1 vfat auto,users,suid,dev,exec 0 0 # AutoUpdate
/dev/sda2 /mnt/sda2 reiserfs auto,users,suid,dev,exec 0 0 # AutoUpdate
/dev/sda5 /mnt/sda5 vfat auto,users,suid,dev,exec 0 0 # AutoUpdate
/dev/sda6 /mnt/sda6 reiserfs auto,users,suid,dev,exec 0 0 # AutoUpdate
/dev/sda7 swap swap defaults 0 0 # AutoUpdate
/dev/fd0 /mnt/floppy vfat,msdos noauto,users,suid,dev,exec 0 0 # AutoUpdate
# Montagem dos diretórios compartilhados pelo nó controlador
10.0.4.48:/usr /usr nfs exec,dev,suid,rw 1 1
10.0.4.48:/home /home nfs exec,dev,suid,rw 1 1
10.0.4.48:/root /root nfs exec,dev,suid,rw 1 1
ANEXO A
// Persistence Of Vision raytracer version 3.1 sample file.
// File by Dan Farmer
//
// NOTE: This image has traditionally been used as the standard
// benchmark file. At the time of POV-Ray 1.0, this scene rendered
// in about the same time as the average of all of the standard scene
// files. Be cautious of making changes that will unfairly affect
// benchmarks. Please log all changes to this file below.
// ===============
// Change history
// ===============
// POV-Ray 3.0 changes:
// DMF 1995 - Commented out bounding object.
// DMF 1995 - Added max_trace_level 20 for use with ADC
// (reached level 13 of 20 on a 160x100 -a render)
// DCB 1998 - Changed syntax to 3.1 compatable
// ===============
global_settings { assumed_gamma 2.2 max_trace_level 20 }
#include "shapes.inc"
#include "shapes2.inc"
#include "colors.inc"
#include "textures.inc"
#declare DMF_Hyperboloid = quadric { /* Like Hyperboloid_Y, but more curvy */
<1.0, -1.0, 1.0>,
<0.0, 0.0, 0.0>,
<0.0, 0.0, 0.0>,
-0.5
}
camera {
location <0.0, 28.0, -200.0>
direction <0.0, 0.0, 2.0>
up <0.0, 1.0, 0.0>
right <4/3, 0.0, 0.0>
look_at <0.0, -12.0, 0.0>
}
/* Light behind viewer postion (pseudo-ambient light) */
light_source { <100.0, 500.0, -500.0> colour White }
union {
union {
intersection {
plane { y, 0.7 }
object { DMF_Hyperboloid scale <0.75, 1.25, 0.75> }
object { DMF_Hyperboloid scale <0.70, 1.25, 0.70> inverse }
plane { y, -1.0 inverse }
}
sphere { <0, 0, 0>, 1 scale <1.6, 0.75, 1.6 > translate <0, -1.15, 0> }
scale <20, 25, 20>
pigment {
Bright_Blue_Sky
turbulence 0.3
quick_color Blue
scale <8.0, 4.0, 4.0>
rotate 15*z
}
finish {
ambient 0.1
diffuse 0.75
phong 1
phong_size 100
reflection 0.35
}
}
sphere { /* Gold ridge around sphere portion of vase*/
<0, 0, 0>, 1
scale <1.6, 0.75, 1.6>
translate -7*y
scale <20.5, 4.0, 20.5>
finish { Metal }
pigment { OldGold }
}
}
/* Stand for the vase */
object { Hexagon
rotate -90.0*z /* Stand it on end (vertical)*/
rotate -45*y /* Turn it to a pleasing angle */
scale <40, 25, 40>
translate -70*y
pigment {
Sapphire_Agate
quick_color Red
scale 10.0
}
finish {
ambient 0.2
diffuse 0.75
reflection 0.85
}
}
union {
plane { z, 50 rotate -45*y }
plane { z, 50 rotate +45*y }
hollow on
pigment { DimGray }
finish {
ambient 0.2
diffuse 0.75
reflection 0.5
}
}
Aos meus pais e irmã, que sempre me apoiaram e me agüentaram em meu infinito percurso no mundo binário, na estrada da ciência da computação.
AGRADECIMENTOS
Agradeço primeiramente a Deus, aos meus pais, irmã e a toda minha família. Agradeço também a todos os professores que me ajudaram nesse trabalho, bem como o apoio de todos os colegas de classe.
Diz o Grande Ser: Considerai o homem como uma mina rica em jóias de inestimável valor. A educação, tão somente, pode fazê-la revelar seus tesouros e habitar a humanidade a tirar dela algum benefício.
Autor:
Daniel Vahid Lima Tolouei
tolouei[arroba]gmail.com
CENTRO DE ENSINO SUPERIOR DE FOZ DO IGUAÇU
CURSO DE CIÊNCIA DA COMPUTAÇAO
PROJETO DE CONCLUSAO DE CURSO
Trabalho de Conclusão de Curso submetido ao Centro de Ensino Superior de Foz do Iguaçu como parte dos requisitos para a obtenção do grau de bacharel em Ciência da Computação.
Orientador: Prof. Luciano Santos Cardoso
Foz do Iguaçu – PR
2006
[1] Aplicações que não podem, por nenhum instante, parar de funcionar ou apresentar falhas.
| Página anterior | Voltar ao início do trabalho | Página seguinte |
|
|
|




