
Repaso
Gramática.
Conjunto de reglas que determinan un un lenguaje.
Sintáxis.
Verifica que la secuencia de tokens sea válida para un lenguaje.
Tipos de gramática.
1. Irrestricta.
x ? y en donde x tiene por lo menos un elemento no terminal.
2. Contexto sensitivo o sensitiva al contexto.
x ? y
x 0 (no permite producciones con el elemento vacio)
3. Libre de contexto.
x ? y
x = 1 y es un elemento no terminal.
y >= 0
Tipos de gramática libre de contexto.
Lineal izquierdo.
Lineal derecho
Recursiva izquierdo
Recursiva derecho
Recursiva central

Lineal izquierdo.
Es la derivación en donde tan solo el no terminal de más a la izquierda de cualquier forma de frase se sustituye a cada paso.
< S > ? < Y > x
< Y > ? < Z > y
< Z > ? < W > z
< Z > ? ?
< W > ? w
wzyx
Lineal derecha.
Es la derivación en donde tan solo el no terminal de más a la derecha de cualquier forma de frase se sustituye a cada paso.
< S > ? x < Y >
< Y > ? y < Z >
< Z > ? z < W >
< Z > ? ?
< W > ? w
xyzw
Recursiva izquierda.
Es la derivación en donde tan solo el no terminal de más a la izquierda se sustituye a cada paso recursivamente es decir a si misma.
< S > ? < S > a | < S > d
< S > ? < S > b
< S > ? c
< S > ? < S >
cbaa
(Gp:) x
(Gp:) < W >
(Gp:) < S >
(Gp:) < Y >
(Gp:) < Z >
(Gp:) y
(Gp:) z
(Gp:) w
(Gp:) x
(Gp:) < W >
(Gp:) < S >
(Gp:) < Y >
(Gp:) < Z >
(Gp:) y
(Gp:) z
(Gp:) w
(Gp:) < S >
(Gp:) < S >
(Gp:) a
(Gp:) < S >
(Gp:) a
(Gp:) < S >
(Gp:) b
(Gp:) c

Recursivo derecho.
Es la derivación en donde tan solo el no terminal de más a la derecha se sustituye a cada paso recursivamente es decir a si misma.
< X > ? < S >
< S > ? a < S > | d < S >
< S > ? b < S >
< X > ? c
aabc
Recursiva central.
Es la derivación en donde tan solo el no terminal del centro se sustituye a cada paso recursivamente es decir a si misma.
< X > ? < S >
< S > ? a < S > b
< S > ? c < S > d
< S > ? e
acedb
Ejemplos:
Libre de contexto.
< S > ? if < X > then < Y > x ? y
< X > ? a < OP > b | x | = 1
< OP > ? > | < | Y | >= 0
< Y > ? x < OPA > y Puede tener vacio
< OPA > ? =
(Gp:) < S >
(Gp:) < S >
(Gp:) a
(Gp:) < S >
(Gp:) a
(Gp:) < S >
(Gp:) b
(Gp:) c
(Gp:) < X >
(Gp:) < S >
(Gp:) < S >
(Gp:) a
(Gp:) < S >
(Gp:) b
(Gp:) c
(Gp:) < X >
(Gp:) d
(Gp:) e

Contexto sensitivo.
< S > ? < X > < Y > x = y
< X > ? a < Z > y ? e no permite vacio
a< Z > ? b < W >
< Y > ? d
< W > ? c
Irrestricta.
< X > ? < A > < B > Sin restricciones.
< A > ? a
< B > ? b
Derivación.
Consiste en sustituir los elementos no terminales por sus producciones.
Ejemplo:
< S > ? IF < X > then < Y > Se sustituye de izquierda a derecha
< S > ? IF a < OP > b then < Y >
< S > ? IF a < b then < Y >
< S > ? IF a < b then x < OPA > y
< S > ? IF a < b then x=y El resultado es solo con terminales
Componentes de la gramática.
G={P, S, V, V’} o bien G={P, S, T, N}
En donde: P=producciones.
S=producción inicial
V=los elementos terminales
V’=los elementos no terminales

De el ejemplo anterior……..
P={S, X, Y, op, opA}
S={S}
V={a, if, b, then, x, y, =, >, >}
V’={S, X, Y, op, opA}
¿Cómo se representa una gramática gráficamente?
Diagrama de sintáxis.
Dirección
Terminales
No terminales
Patrones más comunes.
a) Secuencia de símbolos.
< S > ? a < X > b
(Gp:) < S >
(Gp:) a
(Gp:) X
(Gp:) b

b) Alternativa de símbolos.
? real | char | int
c) Repetición de símbolos.
< X > ? a < X >
< X > ? a
Ejemplos:
real
char
int
(Gp:) < X >
(Gp:) a
(Gp:) < PROGRAM >
(Gp:) fun
(Gp:) proc
(Gp:) id
(Gp:) ;
(Gp:) PARAM
(Gp:) TIPO
(Gp:) id
(Gp:) PARAM

< PROGRAM > ? fun id < X > ; < TIPO >
< X > ? | ?
< PROGRAM > ? prac id < X >
(
id
;
)
:
TIPO
X
Y
? ( < X > < Y > : < TIPO > )
< X > ? var | ?
< Y > ? id < Z >
< Z > ? ; id < Z >
< Z > ? ?
< TIPO > ? char | int | real
Validar la siguientes cadenas:
(var id;id:real)
? (< X > < Y > : < TIPO >)
? (var < Y > : < TIPO >)
? (var id < Z > : < TIPO >)
? (var id ; id < Z > : < TIPO >)
? (var id ; id : < TIPO >)
? (var id ; id : real)
var

fun id (id : char); real
< PROGRAM > ? fun id < X > ; < TIPO >
< PROGRAM > ? fun id ; < TIPO >
< PROGRAM > ? fun id (< X > < Y > : < TIPO >) ; < TIPO >
< PROGRAM > ? fun id (< Y > : < TIPO >) ; < TIPO >
< PROGRAM > ? fun id ( id < Z > : < TIPO >) ; < TIPO >
< PROGRAM > ? fun id ( id : < TIPO >) ; < TIPO >
< PROGRAM > ? fun id ( id : char ) ; real

Análisis Sintáctico
Análisis Sintáctico Descendente.
Análisis Sintáctico por descenso recursivo.
Análisis Sintáctico recursivo. (predictivo).
Análisis Sintáctico Ascendente.
Análisis sintáctico LR-Simple.
Análisis sintáctico LR-Canónico.
Análisis sintáctico LALR (lookahead-LR)
Análisis sintáctico
Programa Sintáctico
Tabla de análisis sintáctico predictivo
(Matriz predictiva)
PILA
Buffer de entrada
Salida de producciones
< X > –> < Y >+< Z >
< Z > –> b
< Y > –> a

Un analizador sintáctico esta guiado por tablas, tiene un buffer de entrada, una pila, y una tabla de análisis sintáctico y también una salida.
El buffer de entrada contiene la cadena que se va a analizar seguida de un símbolo de pesos ($), un símbolo utilizado como delimitador derecho para indicar el fin de la cadena.
La pila contiene una secuencia de símbolos gramaticales con un símbolo de pesos en la parte inferior que indica la base de la pila, al principio la pila contiene el símbolo inicial de la gramática encima del signo de pesos. La tabla de análisis sintáctico es una matriz bidimensional de la forma M [A,a] en donde A es un no terminal y donde “a” es el símbolo terminal o bien el signo de $, se controla el analizador sintáctico mediante un programa que se comporta como sigue:
Sea X el símbolo superior de la pila y “a” el símbolo en curso de la entrada: estos dos símbolos determinan la acción del analizador y tienen las siguientes acciones:
1)Si x = a = $ El string es válido.
2)Si x = a ? $
Se saca x de la pila
Se mueve el apuntador al siguiente símbolo o analizador en curso.
3)Si x es un no terminal el programa consulta la entrada de M [X,a] de la tabla de la matriz de análisis sintáctico.
Esta entrada será o una producción de x de la gramática o una entrada de error. Si, por ejemplo, M [X,a] es igual a x que produce uvw osea M [X,a] = {X?< Y >+< Z >} el analizador sintáctico sustituye la x de la cima de la pila por < Z >+< Y > quedando en la parte de encima de la “< Y >” como salida, se sabe que el analizador sintáctico solo imprime la producción utilizada; ahí se podría utilizar cualquier otro código. Si M [X,a] = error ; el analizador sintáctico llama a una rutina de recuperación de error e indica el tipo de error que a ocurrido.

Ventajas:
Programación medianamente corta.
Medianamente fácil de programar.
Desventajas.
Un mantenimiento no sencillo.
Restricciones.
Solo para gramáticas libres de contexto.
Se tiene que eliminar la recursividad izquierda y factorizar si es necesario. (No debe haber 2 elementos en una sola de las casillas de la matriz predictiva)
Ejemplo:
1) < E > ? < T > < E’ >
2) < E’ > ? + < T > < E’ >
3) < E’ > ? ?
4) < T > ? < F > < T’ >
5) < T’ > ? * < F > < T’ >
6) < T’ > ? ?
7) < F > ? id
8) < F > ? (< E >)
Validar la siguiente cadena:
Id + id
A continuación se dará una corrida a la gramática para saber si la cadena es válida


Primeros y siguientes.
Se facilita la construcción de una analizador sintáctico predictivo con 2 funciones asociadas a una gramática (G).
Estas funciones P y S permiten rellenar siempre que sea posible las entradas de una tabla de análisis sintáctico predictivo para una gramática.
También se puede utilizar los conjuntos de componentes léxicos devueltos por la función S como componentes léxicos de sincronización durante la recuperación de errores.
Si a es una cadena de símbolos gramaticales se considera primeros de a como el conjunto de terminales que inician las cadenas derivadas de a.
Si a ? e entonces el vacío también está en primeros de a.
Se define siguientes de A para el no terminal de A, como el conjunto de terminales de A que pueden aparecer inmediatamente a la derecha de A en alguna forma de frase, es decir, el conjunto de terminales de A tal que halla una derivación de la forma S ? aAaß para algún a y ß.
Primeros.
Primero (a) es el conjunto de símbolos terminales que inician cualquier derivación de a.
Cálculo:
a) Si X es un símbolo terminal, entonces primeros (a) = X
b) Si X es un símbolo no terminal, entonces para cada producción del tipo
x ? ß1, ß2…….. ßn
1) Incluir primeros de (ßi) el primeros de (X)
2) De i=1 hasta n-1
Si e está incluido en primeros de (ßi) incluir en primeros de (ßi+1).
3) Tomando como base el punto anterior, si vacío está incluido en
primeros de (ßi) hasta primeros de (ßn) incluir vacio en primeros de (X).

Ejemplo:
< S > ? < E > a
< E > ? op
< E > ? ?
P< S > = {P< E >} = {op, ?}
P< E > = {op, ?}
Siguientes.
X ? YZ
1) Si X es la primera producción de la gramática se incluye $ en siguientes de X.
2) Los siguientes de Y son:
a) Si Z es un terminal se incluyen los primeros (Z) en siguientes (Y) a excepción del vacío.
b) Si Z es un no terminal se incluyen los primeros (Z) en siguientes de Y a excepción del vacío.
3) Los siguientes de Z son, si Z es el último término de la producción, se incluyen los siguientes de esa producción en siguientes de Z.
No se incluye el vacío en vez de esto se incluyen los siguientes de la producción que genera el vacío.
Ejemplo:
1) < E > ? < T > < E’ >
2) < E’ > ? + < T > < E’ >
3) < E’ > ? ?
4) < T > ? < F > < T’ >
5) < T’ > ? * < F > < T’ >
6) < T’ > ? ?
7) < F > ? id
8) < F > ? (< E >)

Primeros.
P(< E >) = {P(< T >)} = {id, ( }
P(< E’ >) = {+, ?}
P(< T >) = {P(< F >)} = {id, ( }
P(< T’ >) = { *, ?}
P(< F >) = {id, ( }
Siguientes.
S(< E>) = { $, )}
S(< E’ >) = {S(< E >), S(< E’ >) } = { $, ) }
S(< T >) = {P(< E’ >)} = { +, S(< E’ >)} = { +, $, ) }
S(< T’ >) = {S(< T >), S(< T’ >)} = { +, $, ) }
S(< F >) = {P(< T’ >)} = { *, S(< T’ >) } = { *, +, $, ) }
Construcción de la matriz predictiva.
Para cada producción A ? ? realizar lo siguiente:
a) Para cada símbolo terminal en primero de (?) agregar A ? ? en M [ A, ?]
b) Si ? esta contenido en primero (?), entonces para cada símbolo terminal
en sig (A), agregar M ? ? en [ A,$ ]
2. Cada espacio de la matriz indefinido hace error.
A continuación se muestra un ejemplo de cómo construir la matriz predictiva, se utilizó
la gramática anterior para obtener los first y los follows.


Ejercicio:
Realizar primeros, siguientes, matriz predictiva y validar las siguientes cadenas:
bmdm, fd, fdm
1) < A > ? < B > d < A >
2) < A > ? m
3) < B > ? < C > < D >
4) < C > ? b < A >
5) < C > ? ?
6) < D > ? f checar gramatica
7) < D > ? g
Primeros.
P(< A >) = {P(< B >), m, } = {b, m, ?}
P(< B >) = {P(< C >)} = {b, ?}
P(< C >) = {b, ?}
P(< D >) = {f, g}
Siguientes.
S(< A >) = {S(< A >), S(< C >)} = {f, g, $}
S(< B >) = {d}
S(< C >) = {P(< D >)} = {f, g}
S(< D >) = {S(< B >)} = {d}

bmdm
fd

fdm
1) < S > ? if < COND > then < OPERACION > else < ASIG > end
2) < COND > ? id < OR > id
3) < OR > ? >
4) < OR > ? <
5) < OPERACION > ? id < OA > id
6) < OA > ? +
7) < OA > ? –
8) < OA > ? *
9) < ASIG > ? id < A > id
10) < A > ? :=
Para la gramática anterior validar la siguiente cadena: if id < id

Primeros.
P(< S >) = { if }
P(< COND >) = { id }
P(< OR >) = { >, < }
P(< OPERACION >) = { id }
P(< OA > ) = { +, -, * }
P(< ASIG >) = { id }
P(< A >) = { := }
Siguientes.
S ( < S >) = { $ }
S ( < COND >) = { then }
S ( < OR >) = { id }
S ( < OPERACION >) = { else }
S ( < OA > ) = { id }
S ( < ASIG >) = { end }
S ( < A > ) = { id }

Técnicas de análisis ascendentes para analizadores sintácticos.
LR- Simple
LR- Canónico
LALR
Constituyen un árbol de derivación para un string de entrada, iniciando por las
y avanzando a la raíz.
Ventajas.
Se detectan errores tan pronto como se van obteniendo las entradas.
No importan la recursividad de las gramáticas ni deben estar factorizadas.
Desventajas.
Cuesta más trabajo implementar la técnica.

Método LR-Simple.
Programa
Analizador
LR
TABLA
DE
ACCIONES
TABLA
DE SALTOS
SALIDA
PILA
En este método la pila almacena símbolos terminales y no terminales en el tope de
la pila siempre se debe encontrar un estado (que va a ser el estado actual del
analizador). Cada espacio resume la información contenida en la pila.
La combinación del símbolo de estado en el tope se la pila y el símbolo de estado
En el tope de la pila y el símbolo de entrada actual se utiliza para indexar la tabla
de acciones a la tabla de saltos, inicialmente la pila contiene el estado cero.

Agregar apuntes pag 90 libro de fundamentos de compiladores

Tabla de acciones.
Es un arreglo bidimensional con un arreglo para cada posible estado y una
columna para cada símbolo terminal de la gramática y para el signo de pesos.
Cada casilla de la tabla contienen las siguientes acciones.
ACC. Aceptación.
ERR. Error.
SN. Desplazamiento en introducción del estado no terminal de la pila.
RN. LA reducción utilizando la producción no terminal.
Tabla de saltos.
Es un arreglo bidimensional con un renglón para cada posible estado y una
columna para cada símbolo no terminal de la gramática, cada casilla contiene
un estado.
TABLA DE ACCIONES TERMINALES
TABLA DE SALTOS NO TERMINALES

Ejemplo Método LR.
0) < E’ > ?. < E >
1) < E > ?.< E >+< T >
2) < E > ?.< T >
3) < T > ?.< T >* < F >
4) < T > ?. < F >
5) < F > ?.id
6) < F > ?.(< E >)
Primeros.
P(< E’ >) = {P(< E >) } = { id, ( }
P(< E >) = {P(< E >), P(< T >)} = { id, ( }
P(< T >) = {P(< T >), P(< F >)} = { id, ( }
P(< F >) = { id, ( }
Siguientes.
S(< E’ >) = { $ }
S(< E >) = {S(< E’ >), +, ) } = { $,+, ) }
S(< T >) = {S(< E >), *} = { $,+, ), * }
S(< F >) = { $,+, ), * }
(Gp:) 0
(Gp:) < E’ > ? .< E >
< E > ? .< E > + < T >
< E > ? .< T >
< T > ? .< T > * < F >
< T > ? .< F >
< F > ? .id
< F > ? .(< E >)
(Gp:) < E >
(Gp:) < E >
(Gp:) < T >
(Gp:) < T >
(Gp:) < F >
(Gp:) id
(Gp:) (
(Gp:) 1
(Gp:) 1
(Gp:) 2
(Gp:) 2
(Gp:) 3
(Gp:) S4
(Gp:) S5

(Gp:) 2
(Gp:) 3
(Gp:) 4
Sig E
S7
+, $, )
R2
< E > ? < T >.
< T > ? < T >. * < F >
*
$, +, ), *
R4
< F > ? id.
$, +, ), *
Sig F
R5
(Gp:) 5
< F > ? (.< E >)
< E > ? .< E > + < T >
< E > ? .< T >
< T > ? .< T > * < F >
< T > ? .< F >
< F > ? .id
< F > ? .(< E >)
(Gp:) < E >
(Gp:) < E >
(Gp:) < T >
(Gp:) < T >
(Gp:) < F >
(Gp:) id
(Gp:) (
(Gp:) 8
(Gp:) 8
(Gp:) 2
(Gp:) 2
(Gp:) 3
(Gp:) S4
(Gp:) S5
(Gp:) 1
(Gp:) < E’ > ? < E >.
< E > ? < E >. + < T >
(Gp:) ACC
(Gp:) $
(Gp:) Sig E’
(Gp:) +
(Gp:) S6
< T > ? < F >.

6
< E > ? < E > + .< T >
< T > ? .< T > * < F >
< T > ? .< F >
< F > ? .id
< F > ? .(< E >)
9
9
3
S4
S5
T
T
F
id
(
7
< T > ? < T > * .< F >
< F > ? .id
< F > ? .(< E >)
F
S4
id
(
S5
10
(Gp:) 8
< F > ? (< E >.)
< E >? < E > .+ < T >
)
S11
(Gp:) 9
$, +, )
R1
< E >? < E > + < T >.
< T >? < T > .* < F >
Sig. E
$, +, ), *
R3
< T > ? < T > * < F >.
Sig. T
(Gp:) 11
$, +, ), *
R6
Sig. F
< F > ? (< E >).
+
S6
*
S7
10

TABLA DE ACCIONES TERMINALES
TABLA DE SALTOS NO TERMINALES

Verificar si la siguiente cadena es válida: id + id$
Eliminación de la recursividad por la izquierda.
A ? Aa | B
Ejemplo:
Aquellas que no contengan al elemento recursivo se agrega una producción nueva (A’) al lado derecho.
A ? BA’
Aquellas producciones que si contengan al elemento recursivo se pasa el elemento recursivo como la producción nueva al lado derecho y se agrega una producción de la misma que produce e.
A’ ? a A’ 1) A ? BA’
A’ ? e 2) A’ ? aA’
3) A’ ? e

Ejemplos:
Gramatica original.
S ? Aa | b
A ? Ac | Sd | e
Eliminación de la recursividad.
S ? Aa | b
A ? bd A’
A ? e
A’ ? cA’
A’ ? adA’
A’ ? e
Gramatica original.
1) E ? E + T
2) E ? T
3) T ? T * F
4) T ? F
5) F ? id
6) F ? (E)
Eliminación de la recursividad.
1) E ? T E’
2) E’ ? + T E’
3) E’ ? e
4) T ? F T’
5) T’ ? * F T’
6) T’ ? e
7) F ? id

Generación de código intermedio
El código intermedio forma un lenguaje de bajo nivel, sin llegar al nivel más
primitivo.
Tipos de código intermedio.
CONVERTIDA
Notación polaca. A:=B+C*D ABCD*+:=
Triplos. A:=B+C*D
Cuádruplos. A:=B+C*D
Código P. A:=B+C*D Cargar B
Cargar C
Cargar D
Multiplicar , Suma
almacena A
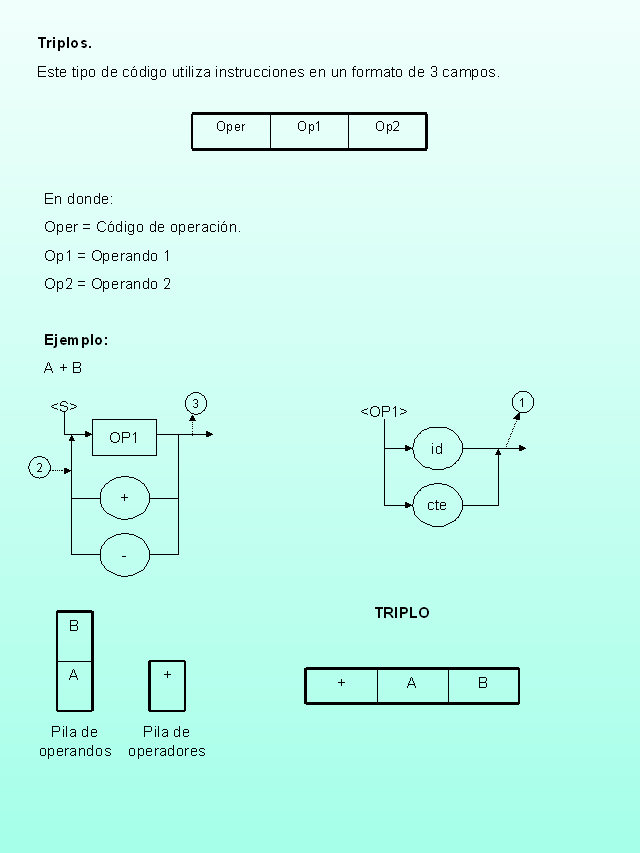
Triplos.
Este tipo de código utiliza instrucciones en un formato de 3 campos.
En donde:
Oper = Código de operación.
Op1 = Operando 1
Op2 = Operando 2
Ejemplo:
A + B
(Gp:) < OP1 >
(Gp:) id
(Gp:) cte
1
< S >
OP1
+
–
2
3
Pila de operandos
Pila de operadores
TRIPLO

Acciones.
1 Insertar en la pila de operandos.
PUSH_pilaop(pos_act) = id ó cte
pos_act+1
2 Insertar en la pila de operadores.
PUSH_pilaoper(pos_act) = + ó –
pos_act+1
3 Genera triplo de la siguiente forma.
Op2 = tope pila_op ? sacar
Op1 = tope pila_op ? sacar
Oper = tope pila_oper ? sacar
Comparación de los diversos modos expuestos.
En cuanto a la cantidad de memoria que requiere para su almacenamiento
podríamos ordenarlos de mayor a menor.
Notación polaca.
Código P.
Triplos.
Cuádruplos.
En cuanto a la velocidad de su ejecución de menor a mayor.
Cuádruplos.
Triplos y código P.
Notación polaca.

Si lo que se requiere es convertir el código intermedio a código objeto,
ordenado de menor a mayor grado de dificultad .
Cuádruplos.
Triplos.
Código P.
Notación polaca.
Las ventajas de los modelos que vamos a estudiar para generar el código
intermedio es que su implementación podrá ser modular.
Ejercicio.
A:=B-C+D
< S >
id
:=
OP2
1
2
4
< OP2 >
OP1
+
–
3
< OP1 >
id
cte
1

Pila de operandos
Pila de operandores
TEMP=
TEMP2 =
TRIPLO =
Acciones.
1 Insertar en pila_operandos.
PUSH pila_op(pos_act) = id
pos_act + 1
2 Insertar en pila de operadores.
PUSH pila_oper(pos_act) = := ó + ó –
pos_act+1
3 Mientras el tope de la pila_operadores sea igual a un + ó un – entonces
generar triplo temporal.
Op2 = tope pila_op ? sacar
Op1 = tope pila_op ? sacar
Oper = tope pila_oper ? sacar
TEMP = OP, OP1, OP2 ? TEMP= OP1, OPER, OP2
Insertar en pila de operandos
p_operandos(pos_act) = TEMP
pos_act + 1

4 Generar triplo
Op2 = tope pila_op ? sacar de la pila
Op1 = tope pila_op ? sacar de la pila
Oper = tope pila_oper ? sacar de la pila
Realizar el siguiente ejercicio tomando en cuenta los diagramas de sintaxis y las
acciones del ejercicio anterior.
X:=A+B+C*D
Pila de operandos
Pila de operadores
TEMP
TEMP1
TEMP2
TRIPLO

Generación de cuádruplos para operaciones aritméticas.
Cuádruplos.
Estructura de tipo registro que tiene 4 campos que son : llamados: operador, operando1, operando2, resultado.
En donde:
Operador: código interno para la operación.
Operando1 y operando 2: valor o variables que intervienen en la operación.
Resultado: registro donde se guarda el resultado.
Nota: Op1 y Op2 normalmente son apuntadores a una tabla de símbolos y su valor puede ser nulo.
Ejemplo:
C:=1
Ejemplo:
(A*B) + (C*D)
< S >
OPER1
(Gp:) EST
(Gp:) < OPER2 >
(Gp:) /
(Gp:) *
(Gp:) 2
(Gp:) 4
(Gp:) OPER2
(Gp:) < OPER1 >
(Gp:) –
(Gp:) +
(Gp:) 2
(Gp:) 4
(Gp:) OPER1
(Gp:) id
(Gp:) < EST >
(Gp:) (
(Gp:) )
(Gp:) 1
(Gp:) 5
(Gp:) 3
nulo

Pila_op
Pila_oper
Acciones.
1 Insertar en la pila de operandos.
PUSH Pila_operandos (pos_act) = id
pos_act+1
2 Insertar en la pila de operadores.
PUSH Pila_operadores (pos_act) = + ó – ó * ó /
pos_act+1
3 Insertar en pila de operadores.
PUSH Pila_operadores(pos_act) = marca fondo falso
pos_act+1
4 Mientras que el tope de la pila sea = + ó – ó * ó /
entonces :
Generar cuádruplo
Op2 = tope Pila_operandos ? sacar de la pila
Op1 = tope Pila_operandos ? sacar de la pila
Operador = tope Pila_operadores ? sacar de la pila
Resultado = Resultado de operaciones Rn + 1
Resul = Op1 Oper Op2

e Insertar en la pila de operandos
PUSH Pila_operandos (pos_act) = Rn + 1
Pos_act + 1
5 Sacar Pila_operadores la marca de fondo falso.
POP -Pila_operadores(pos_act) = M.F.F
Ejemplo:
W:=A + B
(Gp:) OP2
(Gp:) < OP1 >
(Gp:) –
(Gp:) +
(Gp:) 2
(Gp:) 3
(Gp:) < S >
(Gp:) id
(Gp:) :=
(Gp:) OP1
(Gp:) 1
(Gp:) 2
(Gp:) 4
(Gp:) < OP2 >
(Gp:) Cte_num
(Gp:) id
(Gp:) 1
Pila operandos
Pila operadores
Cuádruplos

ESTA PRESENTACIÓN CONTIENE MAS DIAPOSITIVAS DISPONIBLES EN LA VERSIÓN DE DESCARGA