Introducción
El análisis multivariable trata con tres o más variables simultáneamente. Los fenómenos de salud y enfermedad tienen habitualmente múltiples causas, en vez de una sola. Nos movemos, por tanto, en un mundo multivariable. Lo más común en cualquier análisis estadístico es que intentemos explicar un fenómeno teniendo en consideración varias variables simultáneamente. Por esto es tan importante el análisis multivariable[1]En la tabla 12.1 se presentan 3 ejemplos donde se tienen en cuenta varias variables explicativas de un resultado.
Tabla 12.1. Ejemplos típicos de análisis multivariable en ciencias de la salud.
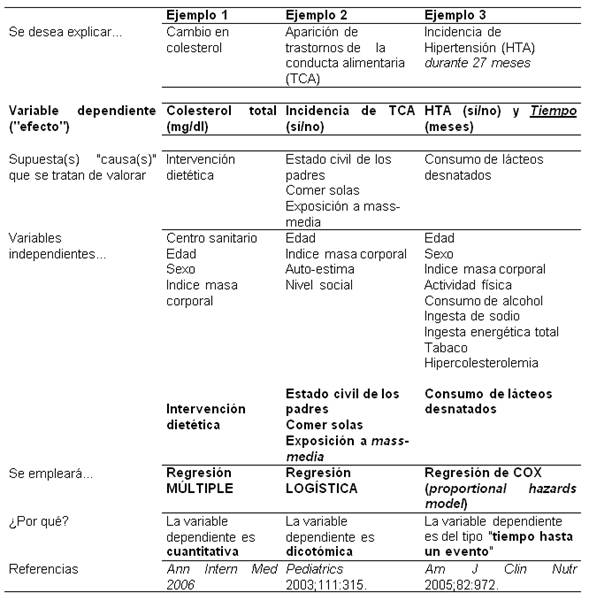
En el primer ejemplo de la tabla 12.1 se trata de valorar los cambios en el colesterol total que pueden explicarse por una intervención dietética, pero hay que tener en cuenta también otros factores. En este ejemplo, se deberán controlar pocos factores, ya que se trataba de un ensayo aleatorizado multicéntrico de gran tamaño y este diseño corrige por sí mismo muchos sesgos, puesla aleatorización consigue un equilibrio de las otras variables entre los grupos comparados (de Irala, 2004).
El colesterol total es una variable cuantitativa o numérica, por lo tanto lo indicado es una regresión que tiene una sola variable dependiente cuantitativa, pero más de una variable independiente y se llama regresión lineal múltiple o más escuetamente regresión múltiple. La regresión múltiple es una extensión de la regresión lineal simple:
Regresión lineal simple: y = a + bx
Regresión múltiple: y = a + b1x1 + b2x2 +… + bpx`p
En el segundo ejemplo interesa saber qué variables se relacionan con la aparición de trastornos de la conducta alimentaria o TCA (anorexia nerviosa o bulimia) en chicas jóvenes. La variable dependiente es ahora de tipo dicotómico (TCA=1 si la chica desarrolló uno de estos trastornos y TCA=0 cuando no lo desarrolló). Los predictores o variables independientes son la edad, el índice de masa corporal (IMC)[2], el nivel de autoestima, el estatus socioeconómico, el estado civil de los padres (si están casados o no), si las chicas comen habitualmente en solitario y su exposición a medios de comunicación (revistas para chicas adolescentes, programas de radio). Los investigadores tenían la hipótesis de que las 3 últimas variables podrían ejercer un papel causal en la génesis de los TCA. Como la variable dependiente (supuesto "efecto") es cualitativa dicotómica, se usará la regresión logística, que viene a ser una extensión multivariable de la ji cuadrado.
El tercer ejemplo valoró si el consumo de productos lácteos desnatados podría proteger frente a la ocurrencia de hipertensión arterial (HTA) en un seguimiento prospectivo durante 27 meses de 5.880 personas (estudio "SUN", Seguimiento Universidad de Navarra, Martínez-González, 2006). Si sólo se hubiese tenido en cuenta la ocurrencia de HTA (1=sí/ 0=no) la situación sería idéntica a la del ejemplo 2. En cambio, ahora interesa también el tiempo que tarda en producirse el diagnóstico de HTA. Se dispone ahora de dos variables por participante:
1-Si ha desarrollado o no hipertensión: 1 = el participante desarrolló HTA
0 = no desarrolló
2-Cuánto tiempo ha sido seguido (hasta desarrollar HTA o hasta acabar el estudio)
La primera variable es cualitativa dicotómica, la segunda es el tiempo de observación que es cuantitativa. Se deben combinar ambas, siguiendo técnicas análogas a las del análisis de supervivencia. Cuando se desea aplicar un análisis multivariante en esta situación, se aplicará la regresión de Cox o proportional hazards model. La regresión de Cox es una extensión multivariable de los métodos de Kaplan-Meier.
Las bases de datos presentarían el siguiente aspecto parcial:

El aspecto parcial de los datos en SPSS para el ejemplo 1 (regresión múltiple) sería:

En el ejemplo 2 (regresión logística) se suele codificar con un valor de 1 a quienes son casos (diagnosticados de TCA en el ejemplo) y con un valor de 0 a los no diagnosticados. El aspecto en SPSS se presenta a continuación por duplicado, a la derecha se muestran los valores de las etiquetas:


En el ejemplo 3 (regresión de Cox) hacen falta dos variables para
construir la respuesta ("efecto" o variable dependiente), ya que hay
que combinar el dato de si se ha producido o no el evento (HTA) con otro dato
que es el tiempo que ha tardado en producirse dicho evento. Para aquellos en
quienes no se produjo el evento, se les asignará el tiempo total que
han sido observados. El aspecto de la base de datos en SPSS sería:
Entre las variadas técnicas multivariables disponibles, se tratarán con cierto detalle, aunque sólo de manera general e introductoria, estas tres técnicas de regresión: la regresión múltiple, la regresión logística y la regresión de riesgos proporcionales o regresión de Cox.
Al final del capítulo se tratará también muy brevemente de otras técnicas de análisis multivariable comparándolas con las anteriores.
12. 2. Regresión lineal múltiple
El modelo de regresión múltiple no es más que una generalización a varias variables de un modelo de regresión simple. La ecuación de la regresión lineal simple es:

Donde "y" es la variable dependiente y "x" es la variable independiente. Pero esta ecuación se puede generalizar para el caso en que haya más de una variable independiente. Supongamos que haya 3 variables independientes: x1, x2, x3. Podemos construir la ecuación:

Cada variable independiente xi tiene un coeficiente de regresión o pendiente propia bi. Este coeficiente se interpretará como el cambio en la variable dependiente ("y"), por unidad de cambio en cada variable independiente (x1, x2 ó x3) a igualdad de nivel de las otras variables independientes. Es imposible interpretar una regresión si no se conocen las unidades de medida de cada variable. Esto se aplica tanto a la regresión simple como a la múltiple.
Supongamos que la Tensión Arterial Sistólica (TAS, mmHg) de una muestra de adultos con alto riesgo cardiovascular se utiliza como variable dependiente "y" intentando predecirla a partir de tres variables independientes, x1, x2 y x3 que corresponden respectivamente a la edad en años (EDAD: x1), el índice de masa corporal en kg/m2 (IMC: x2) y el sexo (SEXO: x2, codificado como sexo=0 para hombres y sexo=1 para mujeres). Resulta la siguiente ecuación:

Y sustituyendo xi por sus nombres, tendremos:

La interpretación será que por cada año más de edad, la TAS aumentará en 0,7 mmHg por término medio, independientemente de cuál sea el sexo y el IMC. Por cada kg/m2 más de IMC subirá la TAS en 0,6 mmHg por término medio (en ambos sexos y sea cual sea la edad). La diferencia entre hombres y mujeres será de 4,9 mmHg menos en las mujeres, a igualdad de edad y de IMC. Quizás esto último es más difícil de entender, se aclarará si construimos dos ecuaciones, una para hombres y otra para mujeres, sustituyendo la variable "SEXO" por sus respectivos valores. La variable sexo se codificó así:
Hombres: SEXO= 0
Mujeres: SEXO= 1
En los hombres, la ecuación será: 
En las mujeres, la ecuación será: 
Por lo tanto, las mujeres, a igualdad de edad e IMC, tendrán una TAS 4,9 mmHg inferior. Es posible introducir variables categóricas (sexo en el ejemplo) en el modelo.
En la figura 12.1 se ha asumido un IMC constante (IMC=25 kg/m2) para poder representar la TAS sólo en función de la edad y el sexo. Se puede observar que, según el modelo de regresión múltiple, las dos ecuaciones (una para hombres y otra para mujeres) son paralelas, ya que como se ha visto anteriormente únicamente difieren en una constante.
Figura 12.1. La ecuación y=a+b1x1+b2x2 da lugar a dos rectas paralelas,
si x2 es una variable dicotómica. En el ejemplo "y" es la TAS, x1 es la edad y x2 el sexo.

(se ha prescindido del IMC, considerándolo fijo en 25 kg/m2)
12.2.1. Estimaciones ajustadas por factores de confusión en regresión múltiple
Un examen atento de la figura 12.1 conduce a concluir que, sea cual sea la edad, la diferencia entre la TAS de hombres y mujeres es constante y vale 4,9 mmHg. Se dice que esta esta diferencia (4,9 mmHg) está ajustada por edad. "Ajustar por" significa equiparar a los grupos que se comparan en cuanto a la variable por la que se ajusta, en este caso es crear una comparación entre hombres y mujeres, igualándolos en cuanto a su edad. Para el ajuste se ha usado un método multivariable, que es la regresión múltiple.
En cambio si comparásemos la TAS entre hombres y mujeres usando un método bivariante (t de Student) encontrariamos que la diferencia es sólo de 2,4 mmHg. El método bivariante no tiene en cuenta la edad, pues sólo considera las dos variables comparadas (sexo y TAS)
¿Cómo es posible que siendo la TAS media de los hombres 2,4 mmHg mayor que la de las mujeres, sin embargo en la figura 12.1 la diferencia a cualquier edad entre la TAS media de hombres y mujeres sea casi el doble (4,9 mmHg). Esto se puede explicar con los datos aportados por la tabla 12.2.
Tabla 12.2. Comparación entre hombres y mujeres de tensión arterial (TAS), edad e IMC.
Hombres (n=326) | Mujeres (n=413) | ||
Tensión arterial sistólica media (DE) | 151,8 (18,2) | 149,4 (20,2) | |
Diferencia de medias en TAS | 151,8 – 149,4 = 2,4 mmHg | ||
t de Student (compara medias TAS) |
| ||
Edad media | 67,6 | 69,9 | |
IMC medio | 28,8 | 30,2 | |
 ( p=0,09 (2 colas)
( p=0,09 (2 colas)Observando la tabla 12.2 puede apreciarse que los hombres de la muestra son más jóvenes que las mujeres (diferencia de edad = 2,2 años) y por eso su TAS es sólo 2,4 mmHg superior cuando se comparan de manera bruta con las mujeres, ya que la TAS aumenta a medida que aumenta la edad. Si, en la muestra, los hombres son más jóvenes que las mujeres, comparar sus medias en la muestra (t de Student) infraestimará la verdadera diferencia existente entre hombres y mujeres. Por eso no basta la comparación bruta, sino que es necesario igualar por edad a hombres y mujeres usando un método multivariable para poder realizar una verdadera comparación válida. Esto libera del efecto distorsionador de la edad. Sólo mediante el método multivariable que ajusta por edad se puede realizar una generalización científicamente rigurosa de las diferencias en TAS entre hombres y mujeres. La verdad es que los hombres tienen la TAS 4,9 mmHg por encima de las mujeres, sea cual sea su edad. Si esto es verdad a todas las edades, debe ser verdad también para el conjunto.
En este ejemplo, al comparar la TAS según sexo, se dice que la variable edad actúa como factor de confusión (Greenland y Morgesten, 2001; de Irala, 2001). Un factor de confusión es una variable que se asocia tanto con la variable independiente (supuesta "causa") como con el supuesto "efecto" y que hace que la comparación bruta o "cruda" (t de Student) sea inválida. Cuando hay factores de confusión se debe usar el análisis multivariable. La figura 12.2 representa gráficamente el papel de la edad como factor de confusión:
Figura 12.2. La edad actúa como factor de confusión
al valorar la relación entre edad y tensión arterial sistólica (TAS)

Usando terminología de gráficos causales (Greenland, 1999; Joffe y Mindell, 2006) se diría que la edad abre una puerta trasera que comunica sexo y TAS (Hernán, 2002; de Irala, 2002). Se cierra dicha puerta trasera al "ajustar" por edad. La comparación bruta (diferencia = 2,4 mmHg entre hombres y mujeres) no es válida. La comparación ajustada (diferencia = 4,9 mmHg) está libre de confusión por edad. La figura 12.3 presenta esto mismo[3]según SPSS.
Tabla 12.3. Modelos de regresión múltiple con la tensión arterial (TAS), edad, sexo e IMC.
Modelo | B | Error típ. | Beta | t | Sig. | ||
1 | (Constante) | 151,827 | 1,070 | 141,952 | 0,000 | ||
Sexo1 | -2,407 | 1,431 | -0,062 | -1,683 | 0,093 | ||
2 | (Constante) | 85,000 | 9,212 | 9,227 | 0,000 | ||
Sexo1 | -4,909 | 1,427 | -0,126 | -3,439 | 0,001 | ||
Edad | 0,741 | 0,109 | 0,246 | 6,801 | 0,000 | ||
IMC | 0,582 | 0,168 | 0,125 | 3,455 | 0,001 | ||
1 Sexo=0 para hombres y Sexo=1 para mujeres.
IMC = índice de masa corporal (kg/m2)
Variable dependiente: tensión arterial sistólica (TAS, mmHg).
Interpretación:
Se han ajustado dos modelos, ambos con TAS como variable dependiente. El primero sólo incluye una variable independiente, que es el sexo. Este primer modelo representa la comparación cruda o bruta (bivariante). Su coeficiente de regresión o pendiente (b = -2,407) corresponde exactamente a la diferencia de medias que se hubiese obtenido usando la t de Student. En este sentido, puede afirmarse que la t de Student es un caso particular de regresión.
El segundo modelo usa 3 variables independientes. Además del sexo, incluye la edad y el índice de masa corporal (IMC). Este modelo ha controlado la posible confusión por edad y por IMC en la comparación de la tensión arterial sistólica (TAS) entre sexos. La verdadera diferencia, una vez ajustada por edad e IMC es de –4,9 mmHg (TAS inferior en las mujeres).
Los valores p de significación estadística indican que cada una de las tres variables del segundo modelo se asocia independientemente a la TAS de manera significativa. El valor p del primer modelo (p = 0,093) no es significativo, pero no sería válido, ya que está confundido por edad e IMC. El verdadero valor p para la comparación entre sexos es el ajustado (p=0,001) que está en el segundo modelo.
12.2.2. Interacción o modificación del efecto en regresión múltiple
En el ejemplo anterior se asume implicitamente que hay una diferencia en la TAS constante (4,9 mmHg) entre hombres y mujeres, sea cual sea su edad. Pero hay veces que la diferencia entre hombres y mujeres no es constante para todas las edades. Por ejemplo pudiera pasar que, a medida que sea mayor la edad, sean menores las diferencias entre hombres y mujeres. A esto se le llama "modificación del efecto" o "interacción", pues significa que la edad modifica las diferencias entre sexos (o viceversa: que el efecto de la edad sobre la TAS es diferente en uno y otro sexo). La interacción puede valorarse introduciendo una nueva variable que es el producto de las dos que podrían interactuar entre sí.
Término de interacción = sexo * edad
En el ejemplo, el término de producto sexo*edad valdrá 0 en varones, ya que la variable sexo vale 0 para ellos. Pero esta nueva variable equivale a la edad en mujeres (edad*1 = edad). Se debe ajustar un tercer modelo (tabla 12.4, modelo 3) incluyendo el término de producto.
Tabla 12.4. Regresión múltiple con TAS (dependiente), edad, sexo e IMC,
añadiendo un término de interacción (modelo 3) entre sexo y edad.
Modelo | B | Error típ. | Beta | t | Sig. | ||
1 | (Constante) | 151,827 | 1,070 | 141,952 | 0,000 | ||
Sexo | -2,407 | 1,431 | -0,062 | -1,683 | 0,093 | ||
2 | (Constante) | 85,000 | 9,212 | 9,227 | 0,000 | ||
Sexo | -4,909 | 1,427 | -0,126 | -3,439 | 0,001 | ||
edad | 0,741 | 0,109 | 0,246 | 6,801 | 0,000 | ||
IMC | 0,582 | 0,168 | 0,125 | 3,455 | 0,001 | ||
3 | (Constante) | 96,051 | 12,060 | 7,965 | 0,000 | ||
sexo | -26,089 | 15,000 | -0,670 | -1,739 | 0,082 | ||
edad | 0,576 | 0,159 | 0,192 | 3,625 | 0,000 | ||
IMC | 0,584 | 0,168 | 0,125 | 3,470 | 0,001 | ||
sexo*edad | 0,308 | 0,217 | 0,559 | 1,418 | 0,156 | ||
1 Sexo=0 para hombres y Sexo=1 para mujeres.
IMC = índice de masa corporal (kg/m2)
sexo*edad = término de producto (equivale a la edad en mujeres y a 0 en varones)
Variable dependiente: tensión arterial sistólica (TAS, mmHg).
Interpretación:
El modelo 3 proporciona dos ecuaciones, una para hombres y otra para mujeres.
Varones: 
Mujeres: 
Sumando las constantes y los coeficientes de la edad, la ecuación en mujeres será:
Mujeres (simplificada): 
Sin embargo, al valorar una interacción debe comprobarse si su coeficiente tiene un valor p significativo o no. Si no es significativo debe suprimirse. Aquí el valor p no es significativo (p=0,156) y preferiremos el modelo sin interacción, ya que no hay evidencia para rechazar la hipótesis nula de que su coeficiente (0,308) sea 0 en la población. No obstante, a efectos demostrativos, representaremos gráficamente el modelo con interacción (figura 12.3) para interpretar su significado.
Figura 12.3. Interacción. La ecuación y=a+b1x1+b2x2+ b2(x1*x2) da lugar a dos rectas
que ya no son paralelas. En el ejemplo "y" es la TAS, x1 es la edad y x2 el sexo.

(se ha prescindido del IMC, considerándolo fijo en 25 kg/m2)
Observando la figura 12.3 se aprecia que las diferencias entre hombres y mujeres ya no son constantes, sino que dependen de la edad (la edad es un modificador del efecto del sexo). También puede interepretarse al revés: la pendiente de la recta que relaciona TAS y edad es diferente en hombres y mujeres, es decir el sexo es un modificador del efecto de la edad.
12.2.3. Variables cualitativas con más de dos categorías y variables dummy
Cuando se desea introducir como independiente una variable cualitativa que tenga 3 o más categorías, se debe elegir primero cuál será la categoría de referencia y crear una nueva variable para cada una de las demás categorías.
Por ejemplo, Estruch et al (2006) desean comparar 3 dietas en cuanto a su eficacia para reducir los niveles de colesterol. Usaron 3 dietas, una rica en aceite de oliva virgen (AOV), otra rica en frutos secos (FS) y una dieta control baja en grasas (control). La variable cualitativa "dieta " tendrá, por tanto estos 3 niveles o categorías. Se considerá el grupo control como categoría de referencia y se crearán dos nuevas variables (AOV y FS). Esto sirve para comparar cada una de ellas dos frente al grupo control. La nueva variable AOV valdrá 1 cuando el participante sea asignado al grupo de aceite de oliva virgen y 0 en caso contrario (control o FS). La nueva variable FS valdrá 1 cuando el participante sea asignado al grupo de frutos secos y 0 en caso contrario (control o AOV). Se ha usado este procedimiento para valorar las diferencias en cuanto al cambio de peso al cabo de 3 meses en ese ensayo (Tabla 12.5).
Tabla 12.5. Dos variables "dummy" sustituyen a una variable con 3 categorías
CODIFICACIÓN | Nuevas variables (variables "dummy"") | |
Variable original Categorías: | AOV | FS |
1 = Aceite de oliva | 1 | 0 |
2 = Frutos secos | 0 | 1 |
3 = control | 0 | 0 |
SPSS | B | Error típ. | Beta | t | Sig. | |
(Constante) | -0,280 | 0,191 | -1,461 | 0,144 | ||
AOV | 0,031 | 0,262 | 0,005 | 0,119 | 0,905 | |
FS | 0,161 | 0,267 | 0,027 | 0,605 | 0,546 | |
Variable dependiente: cambio de peso (kg) a 3 meses (DIF_PES.)
Interpretación:
El listado de salida de SPSS sirve para crear tres ecuaciones de cambio de peso, una para cada grupo. Así, se puede comparar el cambio de peso (kg) predicho por el modelo para el grupo de dieta rica en aceite de oliva virgen, lo predicho para dieta rica en frutos secos y lo predicho para el grupo control (baja en grasa).
Modelo para dieta rica en aceite de oliva virgen (AOV=1, FS=0):
DIF_PES = -0,28 + 0,031*1 + 0,161*0
DIF_PES = -0,28 + 0,031 = -0,249
Modelo para dieta rica en frutos secos (AOV=0, FS=1):
DIF_PES = -0,28 + 0,031*0 + 0,161*1
DIF_PES = -0,28 + 0,161 = -0,119
Modelo para dieta baja en grasa (grupo control) (AOV=0, FS=0):
DIF_PES = -0,28 + 0,031*0 + 0,161*0
DIF_PES = -0,28
La interpretación de los dos coeficientes (0,031 y 0,161) es, por tanto, muy sencilla y directa. El primero (+0,031) es la diferencia en el cambio de peso entre el grupo de aceite y el grupo control, el segundo (+0,161) es la diferencia entre el grupo de frutos secos y el grupo control. Ninguna de estas diferencias resultó estadísticamente significativa.
Esto se podría haber hecho también por ANOVA, con dos contrastes a priori (coeficientes: –1, 0 y +1 para el primer contraste y coeficientes: 0, -1 y +1 para el segundo). El resultado sería exactamente idéntico al de la regresión, como puede verse debajo.

La ventaja de hacerlo por regresión es que basta con introducir también otras variables en el modelo (p. ej. sexo, edad, peso inicial, etc.) para obtener estas mismas estimaciones ya ajustadas por esos posibles factores de confusión.
12.2.4. Supuestos o condiciones de aplicación del modelo de regresión múltiple
El procedimiento utilizado para calcular una regresión lineal simple es el ajuste por mínimos cuadrados El objetivo es encontrar la ecuación que mejor se ajuste a los puntos observados. En una regresión múltiple el procedimiento de estimación es semejante al utilizado en la regresión lineal simple, se estima la superficie que mejor se ajusta a la nube de puntos observados. El método se denomina ajuste por mínimos cuadrados. Es un método que minimiza las distancias desde cada punto observado hasta el plano (residuales)
Cuando se ajusta un modelo de regresión múltiple, el ordenador devuelve coeficientes bi para cada una de las variables independientes xi que pueden considerarse predictores de la variable cuantitativa considerada como respuesta (variable dependiente).
Por lo tanto, al igual que en la regresión lineal simple, el modelo se basa unos supuestos similares,que son los siguientes.
( Las variables están relacionadas linealmente.
( La distribución de la variable dependiente condicionada a cada posible combinación de valores de las independientes es una distribución normal multivariable.
( Las variables son independientes unas de otras.
( Homogeneidad de las varianzas (homocedasticidad): las varianzas de la variable "y" condicionadas a los valores de "x" son homogéneas.
Para comprobar estos supuestos se deben guardar los residuales y valorar si se adaptan a la normalidad, igual que se hace en regresión simple. Si el tamaño muestral es grande, habitualmente resultarán significativos los tests de normalidad de los residuales, pero esto tiene poca relevancia práctica. En esta situación un test de normalidad significativo es sólo una consecuencia del tamaño muestral (Lumley, 2002). Resulta entonces más importante valorar la magnitud del apartamiento de la normalidad usando métodos gráficos. Habitualmente, con tamaños muestrales grandes (n>500) la regresión suele ser suficientemente robusta.
Cuando haya un apartamiento notorio de la normalidad en los residuales se puede probar un término cuadrático para alguna de las variables independientes cuantitativas más importantes. Esto conduciría a modelos polinómicos y permitiría incluir relaciones curvilíneas. Existen amplias posibilidades de modelización no lineal en regresión (Greenland, 1995).
12.2.5. Ejemplo práctico del modelo de regresión múltiple
Por ejemplo, con SPSS se obtuvo el listado que aparece en la tabla 12.6 al predecir el índice de masa corporal (IMC) en función de diversas características (edad, hábito tabáquico, nivel de estudios y actividad física en el tiempo libre) en los varones de una muestra representativa de la población adulta (>15 años) de la Unión Europea (Martínez González, 1999a).
La codificación de las variables fue:
Edad: variable cuantitativa (años) | Estudios: 0 = Estudios medios o superiores 1 = Estudios primarios Actividad física en el tiempo libre: variable cuantitativa medida en METs-horas/semana |
Tabaco: 0 = No fumador 1 = Fumador actual 2 = Ex-fumador (lo dejó hace < 1 año) 3 = Ex-fumador (lo dejó hace >= 1 año) |
Tabla 12.6. Aspecto parcial de los resultados de SPSS en regresión múltiple.
Coeficientes
Coeficientes no estandarizados | Coeficientes estandarizados | t | Sig. | ||||||||||
B | Error típ. | Beta | |||||||||||
(Constante) | 18,767 | ,287 | 65,448 | ,000 | |||||||||
EDAD | ,266 | ,014 | 1,229 | 19,672 | ,000 | ||||||||
EDAD AL CUADRADO | -2,364E-03 | ,000 | -,993 | -15,872 | ,000 | ||||||||
FUMADOR | -,468 | ,087 | -,064 | -5,390 | ,000 | ||||||||
EXFUMADOR < 1 AÑO | ,478 | ,245 | ,022 | 1,956 | ,051 | ||||||||
EXFUMADOR 1 AÑO+ | ,530 | ,127 | ,050 | 4,177 | ,000 | ||||||||
ESTUDIOS PRIMARIOS | ,534 | ,091 | ,067 | 5,867 | ,000 | ||||||||
ACTIV. FISICA (METs-h./sem) | -8,501E-03 | ,002 | -,049 | -4,404 | ,000 | ||||||||
Variable dependiente: BMI
Interpretación:
La edad guardaba en esta base de datos una relación curvilínea con el IMC (BMI), el IMC correspondiente a cada edad será: IMC = 18,767 + (0,266edad) – (0,002364edad2). Para entender mejor esta relación, es preferible representar la ecuación gráficamente como se hace en la figura 12.4.

Figura 12.4. Relación entre edad e índice
de masa corporal (BMI). Muestra representativa varones europeos mayores de 15
años (n=7.375) (Martínez González, 1999a).
Además, es preciso considerar que este efecto de la edad es independiente de los otros factores (tabaco, estudios y actividad física) incluidos en el modelo.
La variable categórica "tabaco" tenía 4 categorías, por lo tanto se han introducido 3 términos en el modelo (todas las categorías menos una). La categoría que no se introduce (aquí son los nunca fumadores) es la que queda como estrato de referencia frente al cual se realizan todas las comparaciones. Así, los fumadores tenían (independientemente de cuál fuese su edad, estudios y actividad física) por término medio 0,468 kg/m2 menos de IMC que los nunca fumadores. En cambio los ex-fumadores tenían por término medio mayor IMC que los nunca fumadores. Para los que habían dejado de fumar hacía menos de un año esta diferencia media fue de +0,478 kg/m2, y para los que dejaron de fumar hacía más de un año fue de +0,530 kg/m2, en comparación con los nunca fumadores (siempre independientemente de cuál fuese su edad, estudios y actividad física).
Los hombres cuyo nivel de estudios era primario o menor (Estudios=primarios) presentaron mayor IMC medio que quienes tenían estudios más elevados. La diferencia media en el IMC fue de +0,534 kg/m2 (independientemente de cuál fuese su edad, hábito tabáquico y actividad física).
Cada MET-hora más a la semana de actividad física en el tiempo libre se asoció a una reducción del IMC de 0,0085 kg/m2 (independientemente de cuál fuese la edad, hábito tabáquico y nivel de estudios de los participantes). Los METs son una medición de la cantidad de esfuerzo que se hace en una actividad física o deporte. Se suman a lo largo de la semana multiplicados por las horas que se dedican por término medio a esa actividad o deporte (METS-horas/semana).
Las 4 variables resultaron ser predictores independientes y estadísticamente significativos de la variabilidad en el IMC.
La representación gráfica de la figura 12.4 asume que
los sujetos tenían el valor 0 en las otras 3 variables (nivel de estudios,
hábito tabáquico y actividad física). Tener un valor de
0 en estas 3 variables supone no ser fumador, tener estudios superiores o medios
y no realizar ninguna actividad física en el tiempo libre.
12.3. Regresión logística
Cuando se desea conocer cómo una serie de factores influyen en una variable cualitativa o categórica dicotómica, es decir con dos posibilidades, como por ejemplo estar sano o enfermo, aprobar el MIR o no aprobarlo, etc. se va a utilizar la regresión logística (Hosmer y Lemeshow, 1989; De Irala, 1996; De Irala, 1997; De Irala, 1999).
Utilizaremos la regresión logística cuando tengamos una variable dependiente dicotómica. Esta situación es muy frecuente, ya que muchas veces en la investigación biomédica o epidemiológica se desean identificar los predictores de la ocurrencia de un determinado fenómeno (que ocurra un suceso o no ocurra). Todas las variables que son candidatas a predecir la ocurrencia de ese fenómeno se utilizarían como variables independientes en un modelo de regresión logística, como muestra la figura 12.5.

Figura 12.5. Aplicación de la regresión logística.
Se trata de un contexto muy parecido al de la regresión múltiple, la diferencia es que ahora hemos sustituido la variable dependiente ("y") por otra expresión. Ahora la variable dependiente no tiene un sentido numérico en sí misma, sino que es el logaritmo neperiano (ln) de la probabilidad (p) de que ocurra un suceso, dividido por la probabilidad de que no ocurra (1-p). Al cociente p/1-p en inglés se le llama"odds", que se ha querido traducir por "ventaja".

Es más fácil calcular una odds que definirla. Se calcula una odds dividiendo el número de quienes tienen una característica por el número de quienes no la tienen. Si en un estudio hay 50 pacientes reclutados en un centro de salud y 25 que no proceden de salud (son de un hospital), la odds de proceder del centro de salud es 2. Esto significa que hay el doble de pacientes que vienen del centro de salud que del hospital.

Por tanto, para calcular una odds basta con dividir el número de individuos con la característica de interés por el número de individuos que carecen de ella
12.3.1 Conceptos de odds y odds ratio
Página siguiente  |