Estudio de Herramientas para limpiar Direcciones Postales (página 2)
Generalmente las organizaciones no
cuentan con aplicaciones únicas para cada parte de la
operativa del negocio, sino que pueden tener replicaciones y
distintos sistemas para
atender un mismo conjunto de operaciones, y en
esos casos es probable que las bases de datos de
los sistemas operacionales contengan datos duplicados,
a veces erróneos, superfluos o incompletos. A lo anterior
se le suman los posibles errores a la hora de la entrada de datos
a los sistemas de datos operacionales. Estas cuestiones y otras
mostradas en la figura 1, son algunas de las que contribuyen a la
suciedad de los datos.
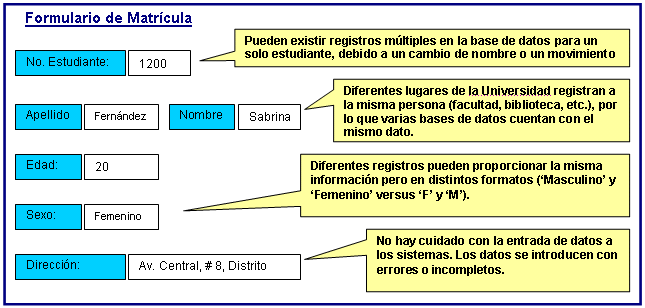
Figura 1: Algunos errores que
provocan suciedad en los datos
La limpieza de datos es mucho más que simplemente
actualizar registros con
datos buenos. Una limpieza de datos seria conlleva
descomposición y reensamblaje de datos. Esta se puede
dividir en seis pasos: separar en elementos, estandarizar,
verificar, machear, agrupar y documentar . Estos seis pasos
mencionados en la mayoría de los casos requieren de
programas
sofisticados y de gran cantidad de conocimientos de expertos
contenidos en ellos.
Hay tres compañías que dominan el mercado de la
limpieza de datos, y las tres se especializan en la limpieza de
grandes listas de direcciones de clientes:
Harte-Hanks Data Technologies, Innovative Systems Inc. (ISI) y
Vality Technology.
A continuación se darán algunos ejemplos
de las experiencias de las empresas que han
realizado limpieza de datos para un ambiente "data
warehousing" con y sin la utilización de herramientas
de software.
Ejemplo 1:
CompuCom Systems implementó un registro de 12
millones, en un depósito de 10 Gb para el soporte de
decisiones internas y de los clientes. Este
desarrolló algunas rutinas de mejoramiento de datos en
lenguajes de cuarta generación (4GL), asociado con su
base de datos
Progress. Los usuarios ayudaron a definir los requerimientos de
limpieza de datos.
La compañía no usa una herramienta de
limpieza comercial, lo que trajo como desventaja principal la
cantidad de tiempo de
desarrollo
(alrededor de una semana) que se necesitó para crear las
rutinas; han buscado paquetes de software comercial, pero no han
encontrado aún, en el mercado, algo que se ajuste mejor a
sus requerimientos.
Ejemplo 2:
Intel (Hillsboro) es un ejemplo de
compañía que ha realizado exitosamente una limpieza
de datos in-house, aunque con ciertos problemas.
Inicialmente pretendió encargar su limpieza de datos a una
agencia de servicios,
para un depósito de aproximadamente 1 millón de
registros tomados desde cinco sistemas
operacionales.
La agencia de servicios prometió identificar
las relaciones entre los diversos grupos dentro de
las compañías clientes, además de proveer
otras informaciones. Desafortunadamente, la agencia de servicios
no hizo un buen trabajo de
identificar las relaciones entre los clientes, lo que dio como
resultado el hecho de que algunas personas estuvieron asociadas
con compañías equivocadas.
Intel tomó la cinta de la agencia de servicio y
luego corrió los datos con el paquete de análisis estadístico SAS, para
identificar y corregir los problemas con las relaciones con los
clientes. La compañía luego usó las
herramientas de base de datos Oracle para
propiciar el análisis y la limpieza.
Ejemplo 3:
La Universidad Emory
(Atlanta) hace la limpieza de todos los datos para su
depósito de 6 Gb con programas en Cobol
generados por Prism Warehouse Manager. Dos miembros del personal utilizan
como 4 horas de un día de trabajo en las tareas de
limpieza de datos.
Emory ha considerado usar herramientas de limpieza de
datos especializados, pero la escuela
está eliminando los datos sucios hasta ahora
suficientemente bien, por lo que no ve el valor
adicional en otros productos
comerciales para justificar la compra.
Sin embargo, tienen posibilidades de que las
herramientas de Prism y Carleton no limpien todo lo que se
necesite. Ellos encuentran anomalías comunes que pueden
manejarse mediante simples tablas de búsqueda de información (por ejemplo, reconocer que
Avenida y Av. representan la misma información), pero
podrían no salir exitosos con irregularidades más
importantes e impredecibles, porque estas herramientas no
están diseñadas para hacer tipos de limpieza de
gran intensidad.
Uno de los ejemplos de datos de empresas que pueden
contener suciedad son las direcciones postales.
El manejo de las direcciones de los clientes nos es tarea
fácil. Más del 50% de las
compañías en Internet no
pueden responder a las necesidades de todos sus clientes y no
se pueden relacionar con ellos correctamente a causa de la
falta de calidad en
sus direcciones.Para comunicarse efectivamente con sus clientes por
teléfono, por correo o por cualquier
otra vía, una empresa
debe de mantener una lista de las direcciones postales de sus
clientes extraordinariamente limpia. Las
compañías pierden credibilidad al usar
direcciones mal escritas o haciendo envíos
múltiples a direcciones distintas que pertenecen a una
misma persona. En
los negocios
de ventas
el
conocimiento de los clientes es importante para saber
quiénes compran determinado producto
repetidamente o en general cómo se comportan las
ventas por determinada región. Es también bueno
para las empresas saber si están tratando con
múltiples organizaciones comerciales que forman parte
de una organización mayor.Las grandes organizaciones orientadas al cliente
como los bancos,
compañías de teléfono y universidades,
recopilan millones de registros de direcciones sin
normalizar. Cada dirección es típicamente
suministrada por una persona diferente y esto está
sujeto a variaciones en estilos que ocurren de persona a
persona.Las direcciones postales tienen
características particulares, están conformadas
por una estructura
implícita, comprendiendo elementos como "calle",
"ciudad" y "código postal". Sin embargo, el orden
de los atributos no es fijo y no todos los atributos
están presentes en todas las instancias.
Además, no solo el formato de las direcciones difiere
de país a país, sino que incluso varía
entre regiones de un mismo país.Estas propiedades hacen al problema de
extracción de estructuras de las direcciones diferente del
problema general de extracción de información
de documentos en
lenguaje
natural, así como del problema de generación de
envoltorios (wrappers) para extraer estructuras desde
documentos HTML. En el
primer caso, el objetivo
es extraer entidades semánticas de documentos en
lenguaje natural basados en restricciones
lingüísticas. En el segundo caso de
generación de "wrappers", pistas sintácticas
son usadas como etiquetas HTML (tags) para definir reglas
para la extracción de estructuras . Las etiquetas HTML
en las páginas tienden a ser altamente regulares
porque las páginas frecuentemente son generadas por
computadoras. En contraste, en el caso de las
direcciones postales, la mayoría son generadas por
humanos y, por tanto, son altamente irregulares.Durante la construcción de un DW todas estas
direcciones deben de ser limpiadas y convertidas a un formato
consistente. Este es un proceso de
múltiples pasos. El primero, llamado Separar en
Elementos las Direcciones , es donde las direcciones son
segmentadas en un conjunto fijo de elementos estructurados.
Por ejemplo, una cadena de dirección "Calle Martí entre Unión y Maceo, # 54,
Rpto Camacho, 50200" puede ser segmentada en seis elementos
como sigue:Número de
casa# 54
Nombre de
calleMartí
Entre calle
1Unión
Entre calle
2Maceo
Reparto
Camacho
Código
Postal50200
El segundo paso llamado Estandarización de
Direcciones es donde abreviaturas (como Rpto.) son
convertidas a un formato canónico y los errores
ortográficos son corregidos. Este es seguido por el
paso de Eliminación de Duplicados
("Deduplication" o "Householding") donde todas las
direcciones pertenecientes a un mismo conjunto son
hermanadas. La calidad de estos últimos pasos puede
mejorarse si primero se realiza la separación de
elementos correctamente.Sin tomar en cuenta la importancia comercial de este
problema y los retos que ofrece, las investigaciones en esta área han sido
limitadas porque a la vista de los investigadores es una
labor intensa y grande.Segmentación y estandarización
de direcciones postalesHerramientas
para limpiar direcciones postales
En el caso de bases de datos grandes, imprecisas e
inconsistentes, el uso de herramientas comerciales para la
limpieza de datos puede ser casi obligatorio.
Decidir qué herramienta usar es importante y no
solamente para la integridad de los datos; si no se selecciona la
herramienta adecuada, se podrían malgastar semanas en
recursos de
programación o cientos de miles de
dólares en costos de
herramientas.
Si los datos que requieren limpieza son
predominantemente nombres (incluyendo nombres de
compañías) y direcciones, las
compañías como Harte-Hanks Communications e
Innovative Systems proveen no solamente herramientas de
software, sino que actualizan periódicamente los archivos de datos
para ayudar a combinar las variantes de los nombres de las
compañías, detectar códigos postales que no
corresponden a las direcciones proporcionadas y encontrar
anomalías similares.
Las soluciones
orientadas al nombre y la dirección pueden costar en
cualquier parte desde $30 000 a más de $200 000,
dependiendo del tamaño del DW en cuestión .
Además, se necesita una herramienta de
extraer/transformar/cargar (Extract, Transform, Load –
ETL), tales como el Warehouse Manager o
Passport.
Para trabajos de limpieza intensos, se deben considerar
herramientas que se han desarrollado para esas tareas. Existen
dos grandes competidores: Enterprise/Integrator de Apertus
Technologies y la herramienta Integrity Data Reengineering
de Vality.
Enfoque Top-Down :
La empresa Enterprise/Integrator toma un enfoque
top-down, en el que el usuario propone las reglas para
limpiar los datos. Esta es una estrategia
directa, donde el usuario impone sus conocimientos sobre su
negocio en los datos.
La empresa
Enterprise/Integrator ofrece no solamente limpieza de
datos, sino también extracción,
transformación, carga de datos, repetición,
sincronización y administración de la metadata. Es bastante
caro (de $130 000 a $250 000), pero se puede ahorrar dinero si se
tiene en cuenta que elimina la necesidad de otras herramientas de
gestión
de DW.
La desventaja principal del enfoque top-down de
Enterprise/Integrator es que el usuario tiene que conocer,
o ser capaz de deducir las reglas del negocio y de la limpieza de
datos.
Por su parte, Apertus provee ejemplos para trabajar con
muchas estructuras comerciales y excepciones comunes. Aún
así, crear reglas es consumo de
tiempo y es seguro que se van
a encontrar algunas excepciones no esperadas.
Enfoque Bottom-Up :
La herramienta Integrity Data Reengineering de
Vality tiene un enfoque bottom-up. Analiza los datos
carácter por carácter y
automáticamente emergen los modelos y las
reglas del negocio. Integrity proporciona un diseño
de los datos para ayudar a normalizar, condicionar y consolidar
los datos. Este enfoque tiende a dejar pocas excepciones para
manejarse manualmente y el proceso tiende a consumir menos
tiempo.
Al igual que Enterprise/Integrator,
Integrity puede tomar en cuenta las relaciones comerciales
que no son obvias a partir de los datos, tales como fusiones y
adquisiciones que han tenido lugar desde que fueron creados los
datos.
Integrity incide exclusivamente sobre la limpieza
de los datos, comenzando desde los archivos básicos. No
extrae los datos desde bases de datos operacionales, carga los
datos en la base de datos del depósito, duplica y
sincroniza los datos o administra la metadata.
Por ello, además de costar $250 000,
Integrity podría requerir también una
herramienta como Warehouse Manager o Passport. Sin
embargo, pueden ser suficientes los utilitarios disponibles con
la base de datos para una simple operación de
extracción/carga.
El grupo Schober Information Group (Partner de
UNISERV ) es una empresa alemana especializada y líder
en Europa en el
sector de la Gestión de Direcciones . Sus productos son
compatibles con varios sistemas
operativos, incluyendo Linux y Windows.
Además se integran y cuentan con certificación
SAP®. Algunos de sus productos principales
son:
- Post : Sistema de
procesamiento postal. - Post (Batch): Recomendado para el control de
grandes archivos de direcciones con una capacidad de
procesamiento de cerca de 1 millón de direcciones cada
30 minutos. - Post (Online): Aquí el control se
realiza de uno en uno. Útil en el caso de un
callcenter, para la comprobación inmediata de la
validez de una dirección. - Mail: Para revisar los registros
dobles - MailBatch: Busca duplicados con procesamiento
secuencial. Útil para el control esporádico de la
BD empresarial. - MailREtrieval: Para la extracción
interactiva de registros y de datos de los cliente. Ideal para
las operaciones normales diarias de procesamiento
online.
Por su parte, Acxiom utiliza el Entorno de
Infraestructura de Integración de datos de clientes (CII) para
tratar las bases de datos de nombres y direcciones.
Basándose en los callejeros más extensos de
España,
el CII utiliza un sistema de inteligencia
difusa para identificar una dirección en su base de datos,
ponerla en la versión oficial, controlar el código
postal, la población y devolverla de forma correcta a
su base de datos. El efecto es un nivel de devoluciones
mínimo en los envíos y una imagen más
profesional de la
empresa.
Otras herramientas son:
- Trillium Software System, Trillium
Software - NADIS, MasterSoft International
- Ultra Address Management, The Computing
Group - PureName PureAddress, Carleton
Para eliminar duplicados
- ETI Solution 5, Evolutionary Technologies
International - Centrus Merge/Purge library, Qualitative
Marketing
Software - SSA-NAME3, Search Software America
- dfPower, DataFlux Corporation
La mayoría de las herramientas antes mencionadas
abordan la segmentación de direcciones postales
utilizando entre otras técnicas
la de sistemas basados en reglas, basados en reglas escritas
manualmente unidas a grandes bases de datos de ciudades, estados
y códigos postales. Estos sistemas funcionan muy bien en
la región para la que fueron desarrollados pero resultan
muy difíciles de extender a otros dominios.
Un ejemplo específico de estos es el Rapier .
Este es un sistema de aprendizaje
inductivo bottom-up para encontrar reglas de
extracción de información. Usa técnicas de
programación lógica
inductiva y encuentra patrones que inducen restricciones en las
palabras, etiquetas de partes del habla y clases
semánticas presentes en el texto y
alrededor de la etiqueta.
Para el problema de la segmentación de
direcciones se requiere algo más que lo que propone el
método
antes mencionado, lo que se debe a que las instancias de este
problema son muy irregulares, el orden de los campos no es fijo,
no todos los campos están presentes en todos los ejemplos
y no siempre existen elementos separadores entre los
campos.
Hidden Markov
Model (HMM)
Los HMMs (Modelos Ocultos de Markov, en español)
son relativamente nuevos en la tarea de extracción de
estructuras. Estos han sido usados con mucho éxito
en tareas de reconocimiento del habla y de escritura,
así como para tareas de procesamiento del lenguaje
natural, como el etiquetado de partes del habla. Este modelo es una
poderosa técnica de máquina de aprendizaje estadística que maneja datos nuevos de
forma robusta, es computacionalmente eficiente y fácil de
aprender e interpretar. La última propiedad hace
a esta técnica particularmente adecuada para el problema
de etiquetar direcciones.
El modelo básico de un HMM consiste de
:
- Un conjunto de n estados (conjunto
E) - Un diccionario
de m símbolos de salida - Una matriz
An x n de transiciones, donde el elemento
aij es la probabilidad de
hacer una transición del estado
i al estado j - Una matriz Bn x m , donde la entrada
bjk denota la probabilidad de emitir el
kmo símbolo de salida en el estado
j.
Además hay dos estados especiales, denotados como
el nodo Inicial y el nodo Final. El total de elementos en el que
debe dividirse el texto es |E|. Cada estado del HMM es marcado
con exactamente uno de los elementos de E. Los datos de entrenamiento
consisten en una secuencia de pares elemento-símbolo. Esto
impone la restricción de que para cada par (e,s),
el símbolo s solo puede ser emitido por el estado
marcado con el elemento e.
A partir de este modelo, dada una secuencia de salida
O = o1; o2;…; ok
de tamaño k (dirección postal con k
elementos) y un HMM de n estados, se quiere encontrar la
secuencia de estados (secuencia oculta) desde el estado inicial
al estado final que genera la secuencia O.
En la figura 2 se muestra un
ejemplo de HMM típico para la segmentación de
direcciones.

Fig. 2 Estructura de un sencillo
HMM
El número de estados n es 10 y las
etiquetas de los arcos muestran las probabilidades de
transición de un estado a otro (matriz A). Por ejemplo, la
probabilidad de que una dirección comience con el
Número de la casa es 0.92 y de que la Ciudad vaya
después de la calle es 0.22. Las probabilidades de
emisión de los elementos fueron omitidas por razones de
espacio.
Los cuatro parámetros que forman un HMM son
construidos en el proceso de entrenamiento del modelo, el cual
consta de dos fases. En la primera se selecciona la estructura
del HMM (cantidad de nodos y de arcos entre ellos), además
de definir el diccionario de símbolos de salida. En la
segunda fase, ya asumiendo una estructura fija del HMM, se
entrenan las probabilidades de transición y de
emisión de los símbolos para cada
estado.
Las probabilidades de transición pueden ser
calculadas usando el método de Máxima Probabilidad
(Maximum LikeLihood) en todas las secuencias de
entrenamiento. Como consecuencia, la probabilidad de hacer una
transición del estado i al j es el cociente
del número de transiciones hechas desde el estado i
hasta el j en los datos de entrenamiento entre el total de
transiciones hechas desde i.
![]()
Donde,
Gij es el número de transiciones
desde el estado i hasta el estado j.
Hi es el total de transiciones que salen
del estado i
Las probabilidades de emisión son calculadas de
forma similar. La probabilidad de emitir el símbolo k en
el estado j es el cociente del número de veces que el
símbolo k es emitido en el estado j entre el
total de símbolos emitidos en el estado.
![]()
Donde,
Ljk es el número de veces que el
símbolo k es emitido en el estado
j.
Tj es el total de símbolos
emitidos en el estado j.
"..no matter how much data one has, smoothing can
almost always help performace, andfor a relatively small effort." (Chen
& Goodman 1998)Frecuentemente, durante la fase de prueba del modelo
se encuentran palabras que no fueron vistas en el
entrenamiento, por tanto la fórmula (2) anterior
asignará una probabilidad de cero por cada
símbolo desconocido causando que la probabilidad final
sea cero sin tomar en cuenta los
valores de probabilidad del camino. Por lo que asignar la
probabilidad correcta a las palabras desconocidas es
importante.Para el suavizamiento es posible usar un
método llamado descuento absoluto (absolute
discounting) . En este método se sustrae un valor
pequeño, digamos x, de la probabilidad de todas
las palabras mj vistas en el estado
j (probabilidad ≠ 0). Entonces se distribuye la
probabilidad acumulada equitativamente entre los valores no
conocidos. Así la probabilidad de un símbolo no
conocido es (m es el total de símbolos) y para un
(m es el total de símbolos) y para un
símbolo conocido k es , donde bjk es
, donde bjk es
calculada como en (2). No hay ninguna teoría sobre cómo seleccionar el
mejor valor para x. Se puede seleccionar x como
 donde
donde
Tj es el denominador de la ecuación
(2) y se entiende por el total de símbolos vistos en
j.Suavizamiento
(Smoothing)Algoritmo
de Viterbi
Para calcular el camino de mayor probabilidad que genera
la secuencia de salida (la dirección) se utiliza el
algoritmo de
Viterbi.
Dada O = o1; o2;…;
ok (secuencia de salida) de tamaño k
y un HMM de n estados, se quiere encontrar el camino
más probable desde el estado inicial al final que genere
la secuencia O.
- Dado 0 y n+1, que denotan los estados especiales
inicial y final. - Dado vs(i), la probabilidad del
camino mas probable para el prefijo o1;
o2;…; oi de O que
termina con el estado s.
Primeramente se tiene para el estado inicial etiquetado
con 0 : v0(0) = 1; vk(0) = 0; k ≠
0
Luego los valores siguientes son hallados usando la
siguiente fórmula recursiva :
![]()
Donde bs(oi) es la
probabilidad de emitir el imo símbolo
oi en el estado s y
ars es la probabilidad de transición
desde el estado r al estado s. El máximo es
tomado sobre todos los estados del HMM.
La probabilidad del caminos mas probable que genera la
secuencia de salida O es dado por
![]()
El camino actual puede ser obtenido guardando el
argmax en cada paso. Esta fórmula puede ser
fácilmente implementada como un algoritmo de
programación dinámica.
El HMM descrito en el epígrafe 1.6 ignora
cualquier relación secuencial entre palabras de un mismo
elemento debido a que solo hay un estado por elemento. Por
ejemplo, la mayoría de los nombres de calle comienzan con
palabras como "Calle", "Camino" o "Avenida" y después les
sigue el nombre que a veces puede estar formado por más de
una palabra. Tratando un elemento como un único estado no
se captura esta estructura.
Este inconveniente puede ser eliminado si se utiliza un
modelo anidado para el aprendizaje
del HMM, o sea cada nodo del HMM externo tiene asociado un HMM
interno, donde el HMM externo captura la relación
secuencial entre elementos y el HMM interno aprende la estructura
interna de cada elemento.
Otras mejoras también pueden ser introducidas a
este modelo para lograr un superior desempeño, estas son:
- La utilización de una taxonomía de símbolos (palabras,
números, delimitadores) que aparecen en la secuencia de
entrenamiento, que permita generalizar el diccionario para cada
estado del HMM. - Aplicación de la distancia de Levenshtein para
la selección de símbolos en los
diccionarios.
El modelo final después de incorporar todas estas
mejoras, provee una herramienta poderosa de segmentación
que ofrece las siguientes bondades:
- Reconocimiento del orden parcial entre elementos:
casi siempre hay un orden parcial entre los elementos: por
ejemplo, "número de casa" aparece antes que el
"código postal" en los registros de direcciones. Las
probabilidades de transición y la estructura del HMM
externo ayuda a obtener esta información. - Identificación de elementos
simultáneamente: este modelo intenta identificar
simultáneamente todos los elementos del registro,
mientras que los HMM internos corroboran entre ellos hasta
encontrar la segmentación que es globalmente
óptima. - Selección de símbolos a pesar de tener
algunos errores ortográficos: con la utilización
de una medida de distancia entre cadenas es posible la
aprobación de símbolos de la secuencia que se
está analizando que contienen algunos errores
ortográficos al compararlos con los que aparecen en los
diccionarios y encontrar alguno semejante.
En se propone que los símbolos que forman el
diccionario sean organizados en una jerarquía. Un ejemplo
de taxonomía se muestra en la figura 3 donde el nivel
superior no hace distinción entre símbolos, en el
siguiente nivel este se divide en "Números", "Palabras" y
"Delimitadores"; los números son divididos y así
sucesivamente. Los datos de entrenamiento son usados
automáticamente para seleccionar la frontera
óptima de la taxonomía.

Fig .3: Ejemplo de taxonomía
de símbolos
Esto ayuda a generalizar símbolos en los datos de
entrenamiento a un mayor nivel en algunos casos pero no siempre;
es preciso hallar el nivel adecuado.
Para seleccionar este nivel se puede utilizar el
siguiente método:
- Los datos segmentados disponibles son divididos en
dos partes: entrenamiento y validación. Por ejemplo, se
puede tomar un tercio del total de los datos para la
validación. Primero se entrena el diccionario con todos
los símbolos con su nivel original de detalle y luego se
utiliza el conjunto de validación para seleccionar el
nivel correcto de la taxonomía. El procedimiento
es similar al cross-validation usado en la poda de los
árboles de decisiones para evitar
sobreajuste. Comenzando desde el fondo se poda el árbol
a varios niveles chequeando la efectividad con los datos de
validación. El subárbol de mayor efectividad es
seleccionado.
Uno de los problemas que se presentan en las direcciones
postales es la aparición de faltas
ortográficas en su escritura. Así, elementos como
el nombre de una calle puede verse afectado porque le falta o le
sobra un carácter, o simplemente no está acentuado
como debiera estarlo. Este detalle podría llevar a no
realizar un buen análisis de dicho símbolo al
buscarlo en el diccionario asociado al elemento que pertenece,
por ejemplo al diccionario de calle, y no encontrarlo a
pesar de sí hallarse en él.
Una forma sencilla de solucionar este problema es
utilizando una medida de distancia o de similitud entre
cadenas.
Existen diversas métricas para medir la distancia
o similitud entre dos cadenas. De ellas son muy conocidas la
"Distancia de Hamming" y la "Distancia Levenshtein"
. Esta última tiene múltiples aplicaciones sobre
todo en los últimos años, debido al auge que han
tomado los problemas de procesamiento de textos y del lenguaje
natural.
La "Distancia Levenshtein" o "Distancia de
Edición", como también se le
conoce, es el número de eliminaciones, inserciones o
sustituciones requeridas para transformar una cadena fuente "x"
en una cadena objetivo "z".
Por ejemplo:
- Si x = "villuendas" y z = "villuendas", entonces DL
(x,z) = 0, porque no es necesario hacer ninguna
transformación. Las cadenas fuente y objetivo son
idénticas. - Si x = "migeel" y z = "miguel", entonces DL (x,z) =
1, porque es necesaria una transformación para que la
cadena fuente y objetivo sean iguales (cambiar la primera "e"
por una "u" en la palabra fuente). - Si x = "escambr" y z = "escambray", entonces DL (x,z)
= 2, porque son necesarias dos transformaciones para que la
cadena fuente y objetivo sean iguales (insertar la "a" y la "r"
al final de la palabra fuente).
- Contar con direcciones postales de sus clientes o
usuarios claras, con un mínimo de deficiencias, resulta
imprescindible para cualquier empresa u organización en
la actualidad. Para lograr tal fin, en el proceso de
transformación de las direcciones postales que se
encuentran en las fuentes de
datos para finalmente llevarlas a un DW, resulta necesario
limpiar estas direcciones, y parte de ese proceso es la
segmentación y estandarización. - Existen numerosas herramientas y métodos
que pueden ser utilizados para llevar a cabo esta tarea, y cada
organización escoge el que más se adecue a sus
características. Recientemente se reporta en la literatura
internacional la aplicación con relativo éxito de
los Modelos Ocultos de Markov en el reconocimiento de textos
libres, y dentro de ellos la extracción de la estructura
de direcciones postales.
BIBLIOGRAFÍA
[1] Ó. A. Llombart, "BI: Inteligencia aplicada al
negocio," vol. 2005. [http://www.icc.uji.es/asignatura/obtener.php?letra=I&codigo=G52&fichero=1116236864IG52]
[2] F. S. Almonacid, "Data Warehouse,"
vol. 2006. [http://www.monografias.com/trabajos6/dawa/dawa.shtml#impa]
[3] C. M. R.-F. J. Martín Aresti, M. L.
García Aragonés, T. MÓVILES, A. J. V. C. L.
I. Tello Calvo, and T. I. Y. DESARROLLO, "Sistemas de soporte a
la gestión del negocio," vol. 2005.
[http://www.tid.es/presencia/publicaciones/comsid/esp/articulos/vol812/soporte/soporte.html]
[4] R. Kimball, "Dealing with Dirty Data," vol. 2005,
1996. [http://www.dbmsmag.com/9609d14.html]
[5] P. W. pwidlund[arroba]schober.es and A. G. d. S.
asoto[arroba]schober.es, " Bases de Datos y Calidad de la
Información," vol. 2005, 2005.
[http://www.icemd.com/area-blogs/mes_actual.asp?id_seccion=46]
[6] RealITech, "Data Warehousing (Data Warehousing,
SQL
Server.htm)," vol. 2006, 2001.
[http://www.sqlmax.com/dataw1.asp]
[7] J. B. a. S. Hussain, "Data quality – A problem and
an approach," vol. 2005.
[http://www.wipro.com/webpages/insights/dataquality.htm]
[8] K. D. Vinayak Borkar, Sunita Sarawagiz, "Automatic
segmentation of text into structured," vol. 2006, 2001.
[http://www.it.iitb.ac.in/~creena/seminar/sigmod01.pdf]
[9] W. Publications, "Prism Warehouse Manager 2.0
builds, manages data warehouse," vol. 2006, 1993.
[http://www.findarticles.com/p/articles/mi_m0SMG/is_n14_v13/ai_14425978]
[10] r. j. orli, "Data Extraction, Transformation, and
Migration Tools," vol. 2006, 1996.
[http://www.kismeta.com/ex2.html]
[11] H. Galhardas, "Data Cleaning and Integration," vol.
2006, 2000. [http://web.tagus.ist.utl.pt/~helena.galhardas/cleaning.html]
[12] UNISERV, "SOLUCIONES DE SW AL SERVICIO DE LA
CALIDAD DE LOS DATOS," vol. 2005.
[http://www.uniserv.de/en/download/pdf-download/Generelle-Fact-Sheets/calidad_de_los_datos.pdf]
[13] Acxiom, "Tratamiento de nombres y direcciones.
¿Porqué normalizar sus datos?," vol. 2006.
[http://www.acxiom.es/Gestion_de_la_Informacion/Normalizacion_y_agrupacion/Normalizacion/index.html]
[14] H.-H. Enterprise, "The Trillium Software System,"
vol. 2006, 2006.
[http://www.trilliumsoftware.com/site/content/products/tss/index.asp]
[15] E. Corporation, "Calidad de Datos: Fundamento de la
Empresa Exitosa," vol. 2006, 2006.
[http://www.eniac-corp.com/noticias2.htm]
[16] S. Allen, "Name and Address Data Quality," vol.
2006.
[http://www.iqconference.org/Documents/IQ%20Conference%201996/Keynote%20and%20Lunch%20Speeches/Name%20and%20Address%20Data%20Quality.pdf#search=%22%22MasterSoft%20International%20%22%20%2B%20%22NADIS%22%22]
[17] N. Corporation, "Teradata and Evolutionary
Technologies
International (ETI)," vol. 2006, 2003.
[http://www.teradatalibrary.com/pdf/eb2054.pdf#search=%22%22ETI%20Solution%20%22%22]
[18] U. N. d. Colombia, "
Aprendizaje del modelo," vol. 2006, 2005.
[http://www.virtual.unal.edu.co/cursos/ingenieria/2001832/lecciones/hmm6.html]
[19] K. D. Vinayak R. Borkar, Sunita Sarawagi,
"Automatically Extracting Structure from Free Text Addresses,"
vol. 2006, 2000.
[http://www.acm.org/sigs/sigmod/disc/disc01/out/websites/deb_december/borkar.pdf]
[20] J. C. Kazem Taghva, Ray Pereda, Thomas Nartker,
"Address Extraction Using Hidden Markov Models," vol. 2006.
[http://www.isri.unlv.edu/publications/isripub/Taghva2005a.pdf]
[21] U. N. d. Colombia, "DEFINICION DE LOS ELEMENTOS DE
UN HMM," vol. 2006, 2005.
[http://www.virtual.unal.edu.co/cursos/ingenieria/2001832/lecciones/hmm4.html]
[22] T. Kanungo, "Hidden Markov Models."
[http://www.cfar.umd.edu/~kanungo/software/hmmtut.pdf]
[23] P. Wiggers, "HIDDEN MARKOV MODELS FOR AUTOMATIC
SPEECH RECOGNITION AND THEIR MULTIMODAL APPLICATIONS," vol. 2066,
2001.
[http://www.kbs.twi.tudelft.nl/docs/MSc/2001/Wiggers_Pascal/thesis.pdf]
[24] L. M. B. Pascual, "Introducción a los Modelos Ocultos de
Markov," vol. 2005. [http://www.depeca.uah.es/docencia/doctorado/cursos04_05/82854/docus/HMM.pdf]
[25] B. MacCartney, "NLP Lunch Tutorial: Smoothing,"
vol. 2006, 2005.
[http://www-nlp.stanford.edu/~wcmac/papers/20050421-smoothing-tutorial.pdf#search=%22%22smoothing%20methods%22%20%2B%20%22add-one%22%22]
[26] J. C. Kazem Taghva, Ray Pereda, Thomas Nartker,
"Address Extraction Using Hidden Markov Models," vol. 2006.
[http://www.isri.unlv.edu/publications/isripub/Taghva2005a.pdf]
[27] A. M. P. Herreros, "FUNDAMENTOS DE RECONOCIMIENTO
DE VOZ," vol. 2006.
[28] J. B. M. Acebal, "Introducción al
reconocimiento de voz," vol. 2006. [http://gps-tsc.upc.es/veu/personal/canton/IntrRecVoz.pdf]
[29] B. Resch, "Hidden Markov Models," vol. 2006.
[http://www.igi.tugraz.at/lehre/CI/tutorials/HMM/HMM.pdf]
[30] A. Bogomolny, "Distance Between Strings," vol.
2006.
[http://www.cut-the-knot.org/do_you_know/Strings.shtml]
[31] L. Allison, "Dynamic Programming Algorithm (DPA)
for Edit-Distance," vol. 2006.
[http://www.csse.monash.edu.au/~lloyd/tildeAlgDS/Dynamic/Edit/]
[32] M. P. S. Michael Gilleland, "Levenshtein Distance,
in Three Flavors," vol. 2005, 2005.
[http://www.merriampark.com/ld.htm#WHATIS]
[33] S. Chapman, "Similarity Metrics," vol. 2006, 2006.
[http://www.dcs.shef.ac.uk/~sam/stringmetrics.html]
DATOS DE LA AUTORA
Liudmila Padrón Torres
Profesión: Especialista Informática. Graduada en Lic. en Ciencias de la
Computación.
Entidad donde trabaja: Empresa de Telecomunicaciones de Cuba S.A
(ETECSA V.C.)
Fecha de realización del trabajo:
29/09/2006
Categorías del Trabajo:
ComputaciónGeneral, Empresa

 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |