Durabilidad. Tras la finalización con
éxito
de una transacción, los cambios realizados en la base de datos
permanecen, incluso si hay fallos en el sistema.
Sistema de
recuperación
Un ordenador como cualquier otra herramienta de trabajo
está sujeto a fallas. Por tanto, el sistema de bases de datos
debe realizar con anticipación acciones que
garanticen que las propiedades de atomicidad y durabilidad de las
transacciones, se conserven a pesar de tales fallos. Una parte
integral de un sistema de bases de datos es un
esquema de recuperación, el cual es responsable de la
restauración de la base de datos al estado previo
al fallo. El esquema de recuperación también debe
proporcionar alta disponibilidad; esto es, debe minimizar el
tiempo durante
el que la base de datos no se puede usar después de un
fallo.
ARQUITECTURA DE LOS SISTEMAS DE BASES
DE DATOS
Hay tres características importantes inherentes a
los sistemas de bases de datos: la separación entre los
programas de
aplicación y los datos, el manejo de múltiples
vistas por parte de los usuarios y el uso de un catálogo
para almacenar el esquema de la base de datos. En 1975, el
comité ANSI-SPARC (American National Standard Institute –
Standards Planning and Requirements Committee) propuso una
arquitectura
de tres niveles para los sistemas de bases de datos, que resulta
muy útil a la hora de conseguir estas tres
características.
La definición de un sistema de
información es la descripción detallada de la arquitectura
del sistema. Las arquitecturas de bases de datos han evolucionado
mucho desde sus comienzos, aunque la considerada estándar
hoy en día es la descrita por el comité
ANSI/X3/SPARC (Standard Planning and Requirements Committee
of the American National Standards Institute on Computers and
Information Processing), que data de finales de los
años setenta. Este comité propuso una arquitectura
general para DBMSs basada en tres niveles o esquemas: el
nivel físico, o de máquina, el nivel externo, o de
usuario, y el nivel conceptual. Así mismo describió
las interacciones entre estos tres niveles y todos los elementos
que conforman cada uno de ellos.
Arquitectura ANSI
La arquitectura de sistemas de bases de datos de tres
esquemas fue aprobado por la ANSI-SPARC (American National
Standard Institute – Standards Planning and Requirements
Committee) en 1975 como ayuda para conseguir la separación
entre los programas de aplicación y los datos, el manejo
de múltiples vistas por parte de los usuarios y el uso de
un catálogo para almacenar el esquema de la base de
datos.
Nivel interno: Tiene un esquema interno que
describe la estructura física de almacenamiento de
base de datos. Emplea un modelo físico de datos y los
únicos datos que existen están realmente en
este nivel.Nivel conceptual: tiene esquema conceptual.
Describe la estructura de toda la base de datos para una
comunidad de usuarios. Oculta los detalles físicos de
almacenamiento y trabaja con elementos lógicos como
entidades, atributos y relaciones.Nivel externo o de vistas: tiene varios
esquemas externos o vistas de usuario. Cada esquema describe
la visión que tiene de la base de datos a un grupo de
usuarios, ocultando el resto.
El objetivo de la
arquitectura de tres niveles es el de separar los programas de
aplicación de la base de datos física.
La mayoría de los SGBD no distinguen del todo los
tres niveles. Algunos incluyen detalles del nivel físico
en el esquema conceptual. En casi todos los SGBD que se manejan
vistas de usuario, los esquemas externos se especifican con el
mismo modelo de
datos que describe la información a nivel conceptual, aunque en
algunos se pueden utilizar diferentes modelos de
datos en los niveles conceptuales y externos.
Hay que destacar que los tres esquemas no son más
que descripciones de los mismos datos pero con distintos niveles
de abstracción. Los únicos datos que existen
realmente están a nivel físico, almacenados en un
dispositivo como puede ser un disco. En un SGBD basado en la
arquitectura de tres niveles, cada grupo de
usuarios hace referencia exclusivamente a su propio esquema
externo. Por lo tanto, el SGBD debe transformar cualquier
petición expresada en términos de un esquema
externo a una petición expresada en términos del
esquema conceptual, y luego, a una petición en el esquema
interno, que se procesará sobre la base de datos
almacenada. Si la petición es de una obtención
(consulta) de datos, será preciso modificar el formato de
la información extraída de la base de datos
almacenada, para que coincida con la vista externa del usuario.
El proceso de
transformar peticiones y resultados de un nivel a otro se
denomina correspondencia o transformación. Estas
correspondencias pueden requerir bastante tiempo, por lo que
algunos SGBD no cuentan con vistas externas.
La arquitectura de tres niveles es útil para
explicar el concepto de
independencia
de datos que podemos definir como la capacidad para modificar el
esquema en un nivel del sistema sin tener que modificar el
esquema del nivel inmediato superior.
Se pueden definir dos tipos de independencia de
datos:
La independencia lógica
es la capacidad de modificar el esquema conceptual sin tener que
alterar los esquemas externos ni los programas de
aplicación. Se puede modificar el esquema conceptual para
ampliar la base de datos o para reducirla. Si, por ejemplo, se
reduce la base de datos eliminando una entidad, los esquemas
externos que no se refieran a ella no deberán verse
afectados.
La independencia física es la capacidad de
modificar el esquema interno sin tener que alterar el esquema
conceptual (o los externos). Por ejemplo, puede ser necesario
reorganizar ciertos ficheros físicos con el fin de mejorar
el rendimiento de las operaciones de
consulta o de actualización de datos. Dado que la
independencia física se refiere sólo a la
separación entre las aplicaciones y las estructuras
físicas de almacenamiento,
es más fácil de conseguir que la independencia
lógica.
En los SGBD que tienen la arquitectura de varios niveles
es necesario ampliar el catálogo o diccionario,
de modo que incluya información sobre cómo
establecer la correspondencia entre las peticiones de los
usuarios y los datos, entre los diversos niveles. El SGBD utiliza
una serie de procedimientos
adicionales para realizar estas correspondencias haciendo
referencia a la información de correspondencia que se
encuentra en el catálogo. La independencia de datos se
consigue porque al modificarse el esquema en algún nivel,
el esquema del nivel inmediato superior permanece sin cambios,
sólo se modifica la correspondencia entre los dos niveles.
No es preciso modificar los programas de aplicación que
hacen referencia al esquema del nivel superior.
Por lo tanto, la arquitectura de tres niveles puede
facilitar la obtención de la verdadera independencia de
datos, tanto física como lógica. Sin embargo, los
dos niveles de correspondencia implican un gasto extra durante la
ejecución de una consulta o de un programa, lo cual
reduce la eficiencia del
SGBD. Es por esto que muy pocos SGBD han implementado esta
arquitectura completa.

Arquitectura
funcional ANSI/X3/SPARC
El nivel clave en esta arquitectura, como se puede
adivinar, es el conceptual. Éste contiene la
descripción de las entidades, relaciones y propiedades de
interés
para la empresa (UoD),
y constituye una plataforma estable desde la que proyectar los
distintos esquemas externos, que describen los datos según
los programadores, sobre el esquema interno, que describe los
datos según el sistema físico. Las posibles
proyecciones de datos quedan resumidas en la
gráfica:

Posibles proyecciones de datos.
Como cabría esperar, en la práctica
cotidiana de implementación de bases de datos, esta
arquitectura no es seguida al cien por cien por los DBMSs
comerciales. Existen muy pocos productos que
contengan aplicaciones para facilitar la fase de análisis. Por lo general, el nivel
conceptual se obvia en los productos comerciales, salvo honrosas
excepciones. Lo habitual es que el DBA realice el modelado
conceptual usando sus propios recursos, o tal
vez asistido por alguna aplicación de análisis, ya
sea general o específica. El procesador del
esquema conceptual, es por tanto el propio DBA. Los DBMSs
sí suelen ofrecer facilidades para la creación de
esquemas externos, pero sin pasar por el nivel conceptual. Por
supuesto, un DBMS comercial no está obligado a seguir las
recomendaciones de estandarización de arquitecturas del
comité ANSI/X3/SPARC. Por lo que respecta al modelo
relacional de bases de , que
ya existía antes del informe de este
comité, los fabricantes de RDBMSs se ajustan en mayor o
menor medida al modelo teórico y, en cuanto a la
arquitectura, han intentado seguir las recomendaciones del grupo
RDBTG (Relational Data Base Task Group), parte del comité
ANSI/X3/SPARC.
El resultado de este grupo fue restar importancia a las
arquitecturas y realzar la de los lenguajes e interfaces. Como
consecuencia, el lenguaje
SQL,
está hoy en día totalmente estandarizado, y en
cambio
encontramos distintas arquitecturas de RDBMS. Sin embargo se
pueden distinguir dos tipos generales de arquitecturas para estos
sistemas de bases de datos.

Arquitectura separada de RDBMS

Arquitectura integrada de RDBMS:
El tipo de arquitectura integrada es en general
preferible a la arquitectura separada y el más
común entre los RDBMSs comerciales. De todos modos, la
consecuencia de una integración de los lenguajes de
definición de datos (DDL) y los de manipulación de
datos (DML) en un sólo lenguaje
(DMDL: Data Manipulation and Description Language), son a nuestro
parecer positivas y negativas. Por un lado, esta
integración resulta muy cómoda para el DBA,
puesto que le basta con aprender un solo lenguaje formal para
realizar todas las tareas de creación y mantenimiento
de la base de datos. Pero por otro lado, estos sistemas (tanto
los separados como los uniformes) fuerzan una proyección
directa desde el nivel externo al interno, haciendo que el nivel
conceptual, el fundamental según la arquitectura
ANSI/X3/SPARC, desaparezca o se implemente en el nivel externo
como una vista global externa. Por esta razón algunos DBAs
inexpertos tienden a obviar la fase de análisis, cuando de
hecho es la vital para la correcta implementación de la
base de datos. Insistimos en que un buen modelado conceptual es
una condición indispensable para el correcto desarrollo de
una base de datos. Pensamos que lo ideal es usar un DBMS que nos
permita desarrollar todas las tareas (de descripción y de
manipulación) lo más fácilmente posible,
pero no sin antes disponer de todas las herramientas
necesarias para un correcto modelado conceptual, estén
éstas o no incluidas en el DBMS.
1 El enfoque jerárquico
Un DBMS jerárquico utiliza jerarquías o
árboles
para la representación lógica de los datos. Los
archivos son
organizados en jerarquías, y normalmente cada uno de ellos
se corresponde con una de las entidades de la base de datos. Los
árboles jerárquicos se representan de forma
invertida, con la raíz hacia arriba y las hojas hacia
abajo.

Estructura de un árbol
jerárquico
Un DBMS jerárquico recorre los distintos nodos de
un árbol en un preorden que requiere tres
pasos:
1. Visitar la raíz.
2. Visitar el hijo más a la izquierda,
si lo hubiera, que no haya sido visitado.3. Si todos los descendientes del segmento
considerado se han visitado, volver a su padre e ir al punto
1.
Cada nodo del árbol representa un tipo de
registro
conceptual, es decir, una entidad. A su vez, cada registro o
segmento está constituido por un número de campos
que los describen – las propiedades o atributos de las
entidades. Las relaciones entre entidades están
representadas por las ramas. Cada departamento es una entidad que
mantiene una relación de uno a muchos con los profesores,
que a su vez mantienen una relación de uno a muchos con
los cursos que imparten.
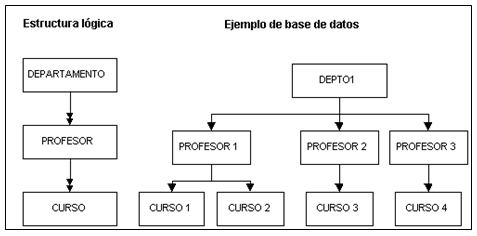
Base de datos jerárquica. Estructura
lógica y ejemplo
A modo de resumen, enumeramos las siguientes
características de las bases de datos
jerárquicas:
1. Los segmentos de un archivo
jerárquico están dispuestos en forma de
árbol.2. Los segmentos están enlazados
mediante relaciones uno a muchos.3. Cada nodo consta de uno o más
campos.4. Cada ocurrencia de un registro padre puede
tener distinto número de ocurrencias de registros
hijos.5. Cuando se elimina un registro padre se deben
eliminar todos los registros hijos (integridad de los
datos).6. Todo registro hijo debe tener un
único registro padre excepto la
raíz.
Las reglas de integridad en el modelo jerárquico
prácticamente se reducen a la ya mencionada de
eliminación en cadena de arriba a abajo. Las relaciones
muchos a muchos no pueden ser implementadas de forma directa.
Este modelo no es más que una extensión del modelo
de ficheros.
REDUNDANCIA
Esta se presenta cuando se repiten innecesariamente
datos en los archivos que conforman la base de datos. Esta
redundancia aumenta los costes de almacenamiento y acceso y
además puede llevar a inconsistencia de los
datos.
Si un cliente
ha realizado más de un pedido todos los datos de este
cliente
estarán repetidos tantas veces como pedidos haya, lo mismo
sucede para los artículos esto es opuesto al principal
objetivo de una base de datos que consiste en evitar la
repetición de los mismos.
Redundancia e inconsistencia de datos: Puesto que
los archivos que mantienen almacenada la información son
creados por diferentes tipos de programas de aplicación
existe la posibilidad de que si no se controla detalladamente el
almacenamiento, se pueda originar un duplicado de
información, es decir que la misma información sea
más de una vez en un dispositivo de almacenamiento. Esto
aumenta los costos
de almacenamiento y acceso a los taos, además de que puede
originar la inconsistencia de los datos-es decir diversas copias
de un mismo dato no concuerdan entre sí-, por ejemplo: que
se actualiza la dirección de un cliente en un archivo
y que en otros archivos permanezca la anterior.
INTEGRIDAD
El
objetivo en cuanto a la integridad es proteger la base de
datos contra operaciones que introduzcan inconsistencias en los
datos, por eso hablamos de integridad en el sentido de
corrección, validez o precisión de los datos de la
base. El subsistema de integridad de un SGBD debe, por tanto,
detectar y corregir, en la medida de lo posible, las operaciones
incorrectas. Existen dos tipos de operaciones que pueden atentar
contra la integridad de los datos que son las operaciones
semánticamente inconsistentes y las interferencias debidas
a accesos concurrentes.
Seguridad e
integridad de los datos
Se trata de garantizar la coherencia de los datos,
comprobando que sólo los usuarios autorizados puedan
efectuar las operaciones correctas sobre la base de datos. Esto
se consigue mediante:
Un control sobre los usuarios que acceden a la base
de datos y los tipos de operaciones que están
autorizados a realizar. Este control se llama gestión
de autorizaciones, y permite crear o borra usuarios y
conceder o retirar derechos a efectuar determinados tipos de
operaciones (por ejemplo: crear objetos, borrar objetos,
modificar datos, etc.La validación de las operaciones realizadas
con los datos. Este control se hace mediante un conjunto de
reglas llamadas restricciones de integridad. Existen varios
tipos de restricciones de integridad, como por ejemplo, las
restricciones de integridad referencial, que imponen que las
modificaciones realizadas sobre algunos datos, obliguen a
realizar modificaciones de otros datos con los que
están enlazados (por ejemplo, si se modifica el
código de un artículo, se debería
modificar ese código en todos los pedidos que
soliciten el artículo.Una protección de los datos contra los
accesos malintencionados y los fallos. Los accesos
malintencionado se suelen evitar con la asignación de
palabras de paso (password) a los usuarios, la
definición de vistas, protección física
de los datos (encriptado de los datos). Con respecto a los
fallos causados por manipulaciones incorrectas, o accidentes
lógicos o físicos, los S.G.B.D. suelen disponer
de utilidades de recuperación de los datos
después de un fallo.La correcta utilización de todas estas
operaciones de seguridad e integridad constituye una tarea
esencial del Administrador de la base de datos
(gestión de usuarios y sus derechos, gestión de
vistas y recuperación después de un
fallo).Terminología en la arquitectura de la bases
de datosIncoherencia de los datos: Si una operación
de puesta al día múltiple no se ha realizado
completamente
el estado de la base de datos queda incoherente y puede
producir errores importantesVersatilidad para representar la información:
Ofrecer diferentes visiones de la información que se
almacena en la BD.Desempeño: Debe dar respuesta en un tiempo
adecuado, permitiendo el acceso simultáneo al mismo o
diferente datos.Mínima redundancia.
Capacidad de acceso: Debe responder en tiempo
adecuado a consultas previstas e imprevistas.Simplicidad: Cambios en los requerimientos no deben
suponer grandes cambios en el modelo de datos.Seguridad: Capacidad para proteger los datos contra
perdidas totales y/o parciales, Contra destrucción
causada por el entorno (fuego, inundación,…), Contra
destrucción causada por fallos del sistema, Contra
accesos no autorizados a la BD, Contra accesos indebidos a
los datosPrivacidad: Debe reservar la información de
accesos de personas no autorizadas.Afinación: Organización de datos
afines para obtener buenos tiempos de respuesta.Integridad: Que los datos sean correctos y se
correspondan a los requerimientos del dominio.Integridad frente a fallos Hw o Sw o de acceso
concurrenteIntegridad asegurando que los datos se ajustan a los
requerimientos del problemaAbstracción de la información. Los
usuarios de los SGBD ahorran a los usuarios detalles acerca
del almacenamiento físico de los datos. Da lo mismo si
una base de datos ocupa uno o cientos de archivos, este hecho
se hace transparente al usuario. Así, se definen
varios niveles de abstracción.Independencia. La independencia de los datos
consiste en la capacidad de modificar el esquema
(físico o lógico) de una base de datos sin
tener que realizar cambios en las aplicaciones que se sirven
de ella.Redundancia mínima. Un buen diseño de
una base de datos logrará evitar la aparición
de información repetida o redundante. De entrada, lo
ideal es lograr una redundancia nula; no obstante, en algunos
casos la complejidad de los cálculos hace necesaria la
aparición de redundancias.Consistencia. En aquellos casos en los que no se ha
logrado esta redundancia nula, será necesario vigilar
que aquella información que aparece repetida se
actualice de forma coherente, es decir, que todos los datos
repetidos se actualicen de forma
simultánea.Seguridad. La información almacenada en una
base de datos puede llegar a tener un gran valor. Los SGBD
deben garantizar que esta información se encuentra
asegurada frente a usuarios malintencionados, que intenten
leer información privilegiada; frente a ataques que
deseen manipular o destruir la información; o
simplemente ante las torpezas de algún usuario
autorizado pero despistado. Normalmente, los SGBD disponen de
un complejo sistema de permisos a usuarios y grupos de
usuarios, que permiten otorgar diversas categorías de
permisos.Integridad. Se trata de adoptar las medidas
necesarias para garantizar la validez de los datos
almacenados. Es decir, se trata de proteger los datos ante
fallos de hardware, datos introducidos por usuarios
descuidados, o cualquier otra circunstancia capaz de
corromper la información almacenada.Respaldo y recuperación. Los SGBD deben
proporcionar una forma eficiente de realizar copias de
seguridad de la información almacenada en ellos, y de
restaurar a partir de estas copias los datos que se hayan
podido perder.Control de la concurrencia. En la mayoría de
entornos (excepto quizás el doméstico), lo
más habitual es que sean muchas las personas que
acceden a una base de datos, bien para recuperar
información, bien para almacenarla. Y es
también frecuente que dichos accesos se realicen de
forma simultánea. Así pues, un SGBD debe
controlar este acceso concurrente a la información,
que podría derivar en inconsistencias.Tiempo de respuesta. Lógicamente, es deseable
minimizar el tiempo que el SGBD tarda en darnos la
información solicitada y en almacenar los cambios
realizados.Inconsistencia Ocurre cuando existe
información contradictoria o incongruente en la base
de datos.Dificultad en el acceso de los datos debido a que
los sistemas de procesamiento de archivos generalmente se
conforman en distintos tiempos o épocas y
ocasionalmente por distintos programadores, el formato de la
información no es uniforme y se requiere de establecer
métodos de enlace y conversión para combinar
datos contenidos en distintos archivos.Aislamiento de los datos, Se refiere a la dificultad
de extender las aplicaciones que permitan controlar a la base
de datos, como pueden ser, nuevos reportes, utilerías
y demás debido a la diferencia de formatos en los
archivos almacenados.Anomalías en el acceso concurrente Ocurre
cuando el sistema es multiusuario y no se establecen los
controles adecuados para sincronizar los procesos que afectan
a la base de datos. Comúnmente se refiere a la poca o
nula efectividad de los procedimientos de bloqueo.Problemas de seguridad Se presentan cuando no es
posible establecer claves de acceso y resguardo en forma
uniforme para todo el sistema, facilitando así el
acceso a intrusos.Problemas de integridad Ocurre cuan no existe a
través de todo el sistema procedimientos uniformes de
validación para los datosArchivos de datos Almacenan a la base de
datos.Diccionario de datos Almacenan información
referente a la estructura de la base de datos.Índices Permiten un acceso eficiente
(rápido y confiable) a la información
almacenada en la base de datosManejador de Archivo Asigna espacio en el medio de
almacenamiento para las estructuras que habrán de
almacenar la información.Manejador de Bases de datos Es la interfase entre
los datos de bajo nivel y los programas de
aplicaciones.Procesador de consulta Se encarga de traducir las
proposiciones de un lenguaje de consultas a instrucciones de
bajo nivel.Precompiladotes de DML.- Se encarga de traducir las
proposiciones en DML al lenguaje de diseño del
manejador (Pascal, C, Ensamblador etc.Compilador de DDL.- Se encarga de convertir las
proposiciones en DDL a tablas que contienen
metadatos.
Bases de datos
distribuidas

Una base de datos distribuida (BDD) es un
conjunto de múltiples bases de datos lógicamente
relacionadas las cuales se encuentran distribuidas entre
diferentes sitios interconectados por una red de comunicaciones, los cuales tienen la capacidad de
procesamiento autónomo lo cual indica que puede realizar
operaciones locales o distribuidas. Un sistema de Bases de Datos
Distribuida (SBDD) es un sistema en el cual múltiples
sitios de bases de datos están ligados por un sistema de
comunicaciones de tal forma que, un usuario en cualquier sitio
puede acceder los datos en cualquier parte de la red exactamente como si los
datos estuvieran siendo accedidos de forma local.
En un sistema distribuido de bases de datos se almacenan
en varias computadoras.
Los principales factores que distinguen un SBDD de un sistema
centralizado son los siguientes:
Hay múltiples computadores, llamados sitios o
nodos.Estos sitios deben de estar comunicados por medio de
algún tipo de red de comunicaciones para transmitir
datos y órdenes entre los sitios.

La necesidad de almacenar datos de forma masiva dio paso a la
creación de los sistemas de bases de datos. En 1970 Edgar
Frank Codd escribió un artículo con nombre: "A
Relational Model of Data for Large Shared Data Banks" ("Un modelo
relacional para grandes bancos de datos
compartidos"). Con este artículo y otras publicaciones,
definió el modelo de bases de datos relacionales y reglas
para poder evaluar
un administrador de
bases de datos relacionales.
Inicio de las bases de datos distribuidas
Originalmente se almacenaba la información de
manera centralizada, pero con el paso del tiempo las necesidades
aumentaron y esto produjo ciertos inconvenientes que no era
posible solucionarlos o volverlos eficientes de la forma
centralizada. Estos problemas
impulsaron la creación de almacenamiento distribuido, los
cuales hoy en día proveen características
indispensables en el manejo de información; es decir, la
combinación de las redes de comunicación y las bases de
datos.
Hardware involucrado
El hardware utilizado no
difiere mucho del hardware utilizado en un servidor normal.
Al principio se creía que si los componentes de una base
de datos eran especializados serían más eficientes
y rápidos, pero se comprobó que el decentralizar
todo y adoptar un enfoque "nada compartido"
(shared-nothing) resultaba más barato y eficaz.
Por lo que el hardware que compone una base de datos distribuida
se reduce a servidores y la
red.
Software
Sistema de Administración de Base de Datos Distribuida
(DDBMS)
Este sistema esta formado por las transacciones y los
administradores de la base de datos distribuidos. Un DDBMS
implica un conjunto de programas que operan en diversas
computadoras, estos programas pueden ser subsistemas de un
único DDBMS de un fabricante o podría consistir de
una colección de programas de diferentes fuentes.
Los SGBD más
usados
ORACLE
Cuando se fundó Oracle en 1977
como Software
Development Laboratories por Larry Ellison, Bob Miner y Ed Oates
no había productos de bases de datos relacionales
comerciales. La compañía, cuyo nombre cambió
posteriormente a Oracle, se estableció para
construir un sistema de gestión
de bases de datos como producto
comercial y fue la primera en lanzarlo al mercado. Desde
entonces Oracle ha mantenido una posición líder
en el mercado de las bases de datos relacionales, pero con el
paso de los años su producto y servicios
ofrecidos han crecido más allá del servicio de
este campo. Aparte de las herramientas directamente relacionadas
con el desarrollo y gestión de bases de datos Oracle vende
herramientas de inteligencia
de negocio, incluyendo sistemas de gestión de bases de
datos multidimensionales y un servidor de aplicaciones con una
integración cercana al servidor de la base de
datos.
D2 DE IBM
La familia de
productos DB2 Universal Database de IBM consiste en servidores de
bases de datos y un conjunto de productos relacionados. DB2
Universal Database Server está disponible en muchas
plataformas hardware y sistemas
operativos, abarcando desde mainframes (grandes ordenadores
centrales) y grandes servidores a estaciones de trabajo e incluso
a pequeños dispositivos de bolsillo. Se ejecuta en una
serie de sistemas
operativos IBM y de otras marcas.
Everyplace Edition soporta sistemas operativos tales como PalmOS,
Windows CE y
otros. Las aplicaciones pueden migrar fácilmente desde las
plataformas de gama baja a servidores de gama alta. Además
del motor del
núcleo de la base de datos, la familia DB2
consta también de varios otros productos que proporcionan
herramientas, administración, réplicas, acceso a
datos distribuido, acceso a datos generalizados, OLAP y otras
muchas características.
SQL SERVER
De Microsoft, es
un sistema gestor de bases de datos relacionales que se usa desde
en portátiles y ordenadores de sobremesa hasta en
servidores corporativos, con una versión compatible,
basada en el sistema operativo
PocketPC, disponible para dispositivos de bolsillo, tales como
PocketPCs y lectores de código
de barras. SQL Server se
desarrolló originalmente en los años 80 en SyBase
para sistemas UNIX y
posteriormente pasado a sistemas Windows NT
para Microsoft. Desde 1994 Microsoft ha lanzado versiones de SQL
Server desarrolladas independientemente de Sybase, que
dejó de utilizar el nombre SQL Server a finales de los
años 90. La última versión disponible es SQL
Server 2000, disponible en ediciones personales, para
desarrolladores, estándar y corporativa, y traducida a
muchos lenguajes en todo el mundo. En este capítulo el
término SQL Server se refiere a todas estas ediciones de
SQL Server 2000.
MySQL
MySQL es un sistema gestor de bases de datos (SGBD, DBMS
por sus siglas en inglés)
muy conocido y ampliamente usado por su simplicidad y notable
rendimiento. Aunque carece de algunas características
avanzadas disponibles en otros SGBD del mercado, es una
opción atractiva tanto para aplicaciones comerciales, como
de entretenimiento precisamente por su facilidad de uso y tiempo
reducido de puesta en marcha. Esto y su libre distribución en Internet bajo licencia GPL
le otorgan como beneficios adicionales (no menos importantes)
contar con un alto grado de estabilidad y un rápido
desarrollo.
POSTGRESQL
PostgreSQL es un gestor de bases de datos orientadas a
objetos (SGBDOO o ORDBMS en sus siglas en inglés) muy
conocido y usado en entornos de software libre
porque cumple los estándares SQL92 y SQL99, y
también por el conjunto de funcionalidades avanzadas que
soporta, lo que lo sitúa al mismo o a un mejor nivel que
muchos SGBD comerciales. El origen de PostgreSQL se sitúa
en el gestor de bases de datos POSTGRES desarrollado en la
Universidad de
Berkeley y que se abandonó en favor de PostgreSQL a partir
de 1994. Ya entonces, contaba con prestaciones
que lo hacían único en el mercado y que otros
gestores de bases de datos comerciales han ido añadiendo
durante este tiempo.
Bibliografía
http://www.fudim.org/comunicacion/notas/nota.php?id=22&a=Adimhttp://es.wikipedia.org/wiki/12_reglas_de_Codd
http://www.desarrolloweb.com/articulos/modelos-base-datos.htmlhttp://es.wikipedia.org/wiki/Clave_for%C3%A1nea
http://es.wikipedia.org/wiki/Diagrama_entidad-relaci%C3%B3n
http://es.wikipedia.org/wiki/Anexo:Comparaci%C3%B3n_de_sistemas_administradores_de_bases_de_datos_relacionales
http://es.wikipedia.org/wiki/DBMS
http://www.mvp-access.es/softjaen/manuales/sql/sjtsqlj002.htmFUNDAMENTOS DE BASES DE DATOS Cuarta
edición/ Abraham Silberschatz, Henry F. Korth, S.
Sudarshan/ McGRAW-HILL.BASE DE DATOS/ SOFTWARE LIBRE
/FORMACION DE POSTGRADO.DISEÑO DE BASE DE DATOS
RELACIONALES/ Adoracion de Miguel Castaño, Mario
Piattini, Esperanza Marcos Martinez/ Alfaomega
A nuestra universidad, por su
reposicionamiento y por el desarrollo del software
libre.
Autor:
Iván Luis Leiva
García
Juan Carlos Carrillo Jara
Jhonatan Lorenzo Solis
Cardenas
Curso: Lenguaje de
Programación III.
Docente: Ing. Ana Doris M. Barrera
Loza.
 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |