La utilización de estos conjuntos de ficheros por
parte de los programas de aplicación era excesivamente
compleja, de modo que, especialmente durante la segunda mitad de
los años setenta, fue saliendo al mercado software
más sofisticado: los Data Base Management Systems, que
aquí denominamos sistemas de gestión de BD (SGBD).
En otras palabras, una base de datos es un conjunto estructurado
de datos que representa entidades y sus interrelaciones. La
representación será única e integrada, a
pesar de que debe permitir utilizaciones varias y
simultáneas.
Con todo lo que hemos dicho hasta ahora,
podríamos definir el término BD; una base de datos
de un SI (Sistema de Información) es la
representación integrada de los conjuntos de entidades
instancia correspondientes a las diferentes entidades tipo del SI
y de sus interrelaciones. Esta representación
informática (o conjunto estructurado de datos) debe poder
ser utilizada de forma compartida por muchos usuarios de
distintos tipos.
LOS AÑOS SESENTA Y SETENTA: SISTEMAS
CENTRALIZADOS
Los primeros SGBD –en los años sesenta
todavía no se les denominaba así estaban orientados
a facilitar la utilización de grandes conjuntos de datos
en los que las interrelaciones eran complejas. El arquetipo de
aplicación era el BilL of materials o Parts
explosión, típica en las industrias del
automóvil, en la construcción de naves espaciales y
en campos similares. Estos sistemas trabajaban exclusivamente por
lotes (batch).
Al aparecer los terminales de teclado, conectados al
ordenador central mediante una línea telefónica, se
empiezan a construir grandes aplicaciones on-line transaccionales
(OLTP). Los SGBD estaban íntimamente ligados al software
de comunicaciones y de gestión de
transacciones.

Aunque para escribir los programas de aplicación
se utilizaban lenguajes de alto nivel como Cobol o PL/I, se
disponía también de instrucciones y de subrutinas
especializadas para tratar las BD que requerían que el
programador conociese muchos detalles del diseño
físico, y que hacían que la programación
fuese muy compleja.
Puesto que los programas estaban relacionados con el
nivel físico, se debían modificar continuamente
cuando se hacían cambios en el diseño y la
organización de la BD. La preocupación
básica era maximizar el rendimiento: el tiempo de
respuesta y las transacciones por segundo.
LOS AÑOS OCHENTA: SGBD RELACIONALES
Los ordenadores minis, en primer lugar, y
después los ordenadores micros, extendieron la
informática a prácticamente todas las empresas e
instituciones. Los SGBD de los años sesenta y setenta (IMS
de IBM, IDS de Bull, DMS de Univac, etc.) eran sistemas
totalmente centralizados, como corresponde a los sistemas
operativos de aquellos años, y al hardware para
el que estaban hechos: un gran ordenador para toda la empresa y
una red de terminales sin inteligencia ni memoria.
Esto exigía que el desarrollo de aplicaciones
fuese más sencillo. Los SGBD de los años setenta
eran demasiado complejos e inflexibles, y sólo los
podía utilizar un personal muy cualificado.

Todos estos factores hacen que se extienda el uso de los
SGBD. La estandarización, en el año 1986, del
lenguaje SQL produjo una auténtica explosión de los
SGBD relacionales.

LOS AÑOS NOVENTA: DISTRIBUCIÓN, C/S Y
4GL
Al acabar la década de los ochenta, los SGBD
relacionales ya se utilizaban prácticamente en todas las
empresas. A pesar de todo, hasta la mitad de los noventa, cuando
se ha necesitado un rendimiento elevado se han seguido utilizando
los SGBD pre-relacionales.
A finales de los ochenta y principios de los noventa,
las empresas se han encontrado con el hecho de que sus
departamentos han ido comprando ordenadores departamentales y
personales, y han ido haciendo aplicaciones con BD. El resultado
ha sido que en el seno de la empresa hay numerosas BD y varios
SGBD de diferentes tipos o proveedores.
Este fenómeno de multiplicación de las BD
y de los SGBD se ha visto incrementado por la fiebre de las
fusiones de empresas.

Esta distribución ideal se consigue cuando las
diferentes BD son soportadas por una misma marca de SGBD, es
decir, cuando hay homogeneidad.
Sin embargo, esto no es tan sencillo si los SGBD son
heterogéneos. En la actualidad, gracias principalmente a
la estandarización del lenguaje SQL, los SGBD de marcas
diferentes pueden darse servicio unos a otros y colaborar para
dar servicio a un programa de aplicación. No obstante, en
general, en los casos de heterogeneidad no se llega a poder dar
en el programa que los utiliza la apariencia de que se trata de
una única BD.
Además de esta distribución "impuesta", al
querer tratar de forma integrada distintas BD preexistentes,
también se puede hacer una distribución "deseada",
diseñando una BD distribuida físicamente, y con
ciertas partes replicadas en diferentes sistemas.

Las razones básicas por las que interesa esta
distribución son las siguientes:
1) Disponibilidad.
La disponibilidad de un sistema con una BD distribuida
puede ser más alta, porque si queda fuera de servicio uno
de los sistemas, los demás seguirán funcionando. Si
los datos residentes en el sistema no disponible están
replicados en otro sistema, continuarán estando
disponibles. En caso contrario sólo estarán
disponibles los datos de los demás sistemas.
2) Coste.
Una BD distribuida puede reducir el coste. En el caso de
un sistema centralizado, todos los equipos usuarios, que pueden
estar distribuidos por distintas y lejanas áreas
geográficas, están conectados al sistema central
por medio de líneas de comunicación. El coste total
de las comunicaciones se puede reducir haciendo que un usuario
tenga más cerca los datos que utiliza con mayor
frecuencia; por ejemplo, en un ordenador de su propia oficina o,
incluso, en su ordenador personal.

Por ejemplo, un programa de aplicación que un
usuario ejecuta en su PC (que está conectado a una red)
pide ciertos datos de una BD que reside en un equipo UNIX donde,
a su vez, se ejecuta el SGBD relacional que la gestiona. El
programa de aplicación es el cliente y el SGBD es el
servidor.

Un proceso cliente puede pedir servicios a varios
servidores. Un servidor puede recibir peticiones de muchos
clientes. En general, un proceso A que hace de cliente, pidiendo
un servicio a otro proceso B puede hacer también de
servidor de un servicio que le pida otro proceso C (o incluso el
B, que en esta petición sería el cliente). Incluso
el cliente y el servidor pueden residir en un mismo
sistema.

La facilidad para disponer de distribución de
datos no es la única razón, ni siquiera la
básica, del gran éxito de los entornos C/S en los
años noventa.
Tal vez el motivo fundamental ha sido la flexibilidad
para construir y hacer crecer la configuración
informática global de la empresa, así como de hacer
modificaciones en ella, mediante hardware y software muy
estándar y barato.

El éxito de las BD, incluso en sistemas
personales, ha llevado a la aparición de los Fourth
Generation Languages (4GL), lenguajes muy fáciles y
potentes, especializados en el desarrollo de aplicaciones
fundamentadas en BD.
Proporcionan muchas facilidades en el momento de
definir, generalmente de forma visual, diálogos para
introducir, modificar y consultar datos en entornos
C/S.
Tendencias
actuales

Los tipos de datos que se pueden definir en los SGBD
relacionales de los años ochenta y noventa son muy
limitados. La incorporación de tecnologías
multimedia –imagen y sonido – en los SI hace
necesario que los SGBD relacionales acepten atributos de estos
tipos.

Sin embargo, algunas aplicaciones no tienen suficiente
con la incorporación de tipos especializados en
multimedia. Necesitan tipos complejos que el desarrollador pueda
definir a medida de la aplicación. En definitiva, se
necesitan tipos abstractos de datos: TAD. Los SGBD más
recientes ya incorporaban esta posibilidad, y abren un amplio
mercado de TAD predefinidos o librerías de
clases.
Esto nos lleva a la orientación a objetos (OO).
El éxito de la OO al final de los años ochenta, en
el desarrollo de software básico, en las aplicaciones de
ingeniería industrial y en la construcción de
interfaces gráficas con los usuarios, ha hecho que durante
la década de los noventa se extendiese en
prácticamente todos los campos de la informática.
En los SI se inicia también la adopción,
tímida de momento, de la OO. La utilización de
lenguajes como C++ o Java requiere que los SGBD relacionales se
adapten a ellos con interfaces adecuadas.
La rápida adopción de la web a los SI hace
que los SGBD incorporen recursos para ser servidores de
páginas web, como por ejemplo la inclusión de SQL
en guiones HTML, SQL incorporado en Java, etc. Notad que en el
mundo de la web son habituales los datos multimedia y la
OO.
Durante estos últimos años se ha empezado
a extender un tipo de aplicación de las BD denominado Data
Warehouse, o almacén de datos, que también produce
algunos cambios en los SGBD relacionales del mercado.
A lo largo de los años que han trabajado con BD
de distintas aplicaciones, las empresas han ido acumulando gran
cantidad de datos de todo tipo. Si estos datos se analizan
convenientemente pueden dar información
valiosa.
Por lo tanto, se trata de mantener una gran BD con
información proveniente de toda clase de aplicaciones de
la empresa (e, incluso, de fuera). Los datos de este gran
almacén, el Data Warehouse, se obtienen por una
replicación más o menos elaborada de las que hay en
las BD que se utilizan en el trabajo cotidiano de la empresa.
Estos almacenes de datos se utilizan exclusivamente para hacer
consultas, de forma especial para que lleven a cabo estudios los
analistas financieros, los analistas de mercado, etc.
Actualmente, los SGBD se adaptan a este tipo de
aplicación, incorporando, por ejemplo, herramientas como
las siguientes:
a) La creación y el mantenimiento de
réplicas, con una cierta elaboración de los
datos.
b) La consolidación de datos de orígenes
diferentes.
c) La creación de estructuras físicas que
soporten eficientemente el análisis
multidimensional.
Evolución
de los SGBD
LA EVOLUCIÓN DE LA TECNOLOGIA DE
BASES DE DATOS
La sofisticación de la tecnología moderna
de las bases de datos es el resultado de la evolución que
a lo largo de varias décadas ha tenido lugar en el
procesamiento de los datos y en la gestión de la
información. La tecnología de acceso a los datos y
en la gestión de la información. La
tecnología de acceso a los datos se ha desarrollado desde
los métodos primitivos de los años cincuenta hasta
los potentes e integrados sistemas de hoy en dia, arrastrados de
un lado por las necesidades y las demandas de la
administración y, de otro, restringida por las
limitaciones de la tecnología.
Las expectativas de la administración han crecido
paralelamente a la evolución de la tecnología. Los
primeros sistemas de procesamiento de datos ejecutaron las tareas
administrativas para reducir el papeleo. Más
recientemente, los sistemas se han expandido hacia la
producción y la gestión de la información,
la que se ha convertido en un recurso vital para las
compañías.
EVOLUCIÓN DE LOS MODELOS DE
BD
Una BD es una representación de la realidad (de
la parte de la realidad que nos interesa en nuestro SI). Dicho de
otro modo, una BD se puede considerar un modelo de la realidad.
El componente fundamental utilizado para modelar en un SGBD
relacional son las tablas (denominadas relaciones en el mundo
teórico).
Sin embargo, en otros tipos de SGBD se utilizan otros
componentes.El conjunto de componentes o herramientas
conceptuales que un SGBD proporciona para modelar recibe el
nombre de modelo de BD.
Los cuatro modelos de BD más utilizados en los SI
son el modelo relacional, el modelo jerárquico, el modelo
en red y el modelo relacional con objetos.
De los cuatro modelos de BD que hemos citado, el que
apareció primero, a principios de los años sesenta,
fue el modelo jerárquico. Sus estructuras son registros
interrelacionados en forma de árboles. El SGBD
clásico de este modelo es el IMS/DL1 de IBM. A principios
de los setenta surgieron SGBD basados en un modelo en red. Como
en el modelo jerárquico, hay registros e interrelaciones,
pero un registro ya no está limitado a ser "hijo" de un
solo registro tipo.
El comité CODASYL-DBTG propuso un estándar
basado en este modelo, que fue adoptado por muchos constructores
de SGBD. Sin embargo, encontró la oposición de IBM,
la empresa entonces dominante. La propuesta de CODASYL-DBTG ya
definía tres niveles de esquemas.

Durante los años ochenta apareció una gran
cantidad de SGBD basados en el modelo relacional propuesto en
1969 por E.F. Codd, de IBM, y prácticamente todos
utilizaban como lenguaje nativo el SQL. El modelo relacional se
basa en el concepto matemático de relación, que
aquí podemos considerar de momento equivalente al
término tabla (formada por filas y columnas). La mayor
parte de los SI que actualmente están en funcionamiento
utilizan SGBD relacionales, pero algunos siguen utilizando los
jerárquicos o en red (especialmente en SI antiguos muy
grandes).
Así como en los modelos pre-relacionales
(jerárquico y en red), las estructuras de datos constan de
dos elementos básicos (los registros y las
interrelaciones), en el modelo relacional constan de un solo
elemento: la tabla, formada por filas y columnas. Las
interrelaciones se deben modelizar utilizando las
tablas.
Otra diferencia importante entre los modelos
pre-relacionales y el modelo relacional es que el modelo
relacional se limita al nivel lógico (no hace
absolutamente ninguna consideración sobre las
representaciones físicas). Es decir, nos da una
independencia física de datos total. Esto es así si
hablamos del modelo teórico, pero los SGBD del mercado nos
proporcionan una independencia limitada.
Estos últimos años se está
extendiendo el modelo de BD relacional con objetos. Se trata de
ampliar el modelo relacional, añadiéndole la
posibilidad de que los tipos de datos sean tipos abstractos de
datos, TAD. Esto acerca los sistemas relacionales al paradigma de
la OO. Los primeros SGBD relacionales que dieron esta posibilidad
fueron Oracle (versión 8), Informix (versión 9) y
eI BM/DB2/UDB (versión 5).
Hablamos de modelos de BD, pero de hecho se acostumbran
a denominar modelos de datos, ya que permiten modelarlos. Sin
embargo, hay modelos de datos que no son utilizados por los SGBD
del mercado: sólo se usan durante el proceso de
análisis y diseño, pero no en las
realizaciones.
Los más conocidos de estos tipos de modelos son
los modelos semánticos y los funcionales. Éstos nos
proporcionan herramientas muy potentes para describir las
estructuras de la información del mundo real, la
semántica y las interrelaciones, pero normalmente no
disponen de operaciones para tratarlas. Se limitan a ser
herramientas de descripción lógica. Son muy
utilizados en la etapa del diseño de BD. El más
extendido de estos modelos es el conocido como modelo ER
(entity-relationship).
Definición
de Sistemas de Base de Datos
Una base de datos es un conjunto de datos almacenados
entre los que existen relaciones lógicas y ha sido
diseñada para satisfacer los requerimientos de
información de una empresa u organización. En una
base de datos, además de los datos, también se
almacena su descripción.
La base de datos es un gran almacén de datos que
se define una sola vez y que se utiliza al mismo tiempo por
muchos departamentos y usuarios. En lugar de trabajar con
ficheros desconectados e información redundante, todos los
datos se integran con una mínima cantidad de duplicidad.
La base de datos no pertenece a un departamento, se comparte por
toda la organización. Además, la base de datos no
sólo contiene los datos de la organización,
también almacena una descripción de dichos datos.
Esta descripción es lo que se denomina metadatos, se
almacena en el diccionario de datos o catálogo y es lo que
permite que exista independencia de datos
lógica-física.
El modelo seguido con los sistemas de bases de datos, en
donde se separa la definición de los datos de los
programas de aplicación, es muy similar al modelo que se
sigue en la actualidad para el desarrollo de programas, en donde
se da una definición interna de un objeto y una
definición externa separada. Los usuarios del objeto
sólo ven la definición externa y no se deben
preocupar de cómo se define internamente el objeto y
cómo funciona. Una ventaja de este modelo, conocido como
abstracción de datos, es que se puede cambiar la
definición interna de un objeto sin afectar a sus usuarios
ya que la definición externa no se ve alterada. Del mismo
modo, los sistemas de bases de datos separan la definición
de la estructura de los datos, de los programas de
aplicación y almacenan esta definición en la base
de datos. Si se añaden nuevas estructuras de datos o se
modifican las ya existentes, los programas de aplicación
no se ven afectados ya que no dependen directamente de aquello
que se ha modificado.
El sistema de gestión de la base de datos (SGBD)
es una aplicación que permite a los usuarios definir,
crear y mantener la base de datos, y proporciona acceso
controlado a la misma.
El SGBD es la aplicación que interacciona con los
usuarios de los programas de aplicación y la base de
datos. En general, un SGBD proporciona los siguientes
servicios:
Permite la definición de la base de datos
mediante el lenguaje de definición de datos. Este
lenguaje permite especificar la estructura y el tipo de los
datos, así como las restricciones sobre los datos.
Todo esto se almacenará en la base de
datos.Permite la inserción, actualización,
eliminación y consulta de datos mediante el lenguaje
de manejo de datos. El hecho de disponer de un lenguaje para
realizar consultas reduce el problema de los sistemas de
ficheros, en los que el usuario tiene que trabajar con un
conjunto fijo de consultas, o bien, dispone de un gran
número de programas de aplicación costosos de
gestionar.
Hay dos tipos de lenguajes de manejo de datos: los
procedurales y los no procedurales. Estos dos tipos se distinguen
por el modo en que acceden a los datos. Los lenguajes
procedurales manipulan la base de datos registro a registro,
mientras que los no procedurales operan sobre conjuntos de
registros. En los lenguajes procedurales se especifica qué
operaciones se deben realizar para obtener los datos resultados,
mientras que en los lenguajes no procedurales se especifica
qué datos deben obtenerse sin decir cómo hacerlo.
El lenguaje no procedural más utilizado es el SQL
(Structured Query Language) que, de hecho, es un estándar
y es el lenguaje de los SGBD relacionales. Proporciona un acceso
controlado a la base de datos mediante:
un sistema de seguridad, de modo que los usuarios no
autorizados no puedan acceder a la base de datos;un sistema de integridad que mantiene la integridad
y la consistencia de los datos;un sistema de control de concurrencia que permite el
acceso compartido a la base de datos;un sistema de control de recuperación que
restablece la base de datos después de que se produzca
un fallo del hardware o del software;un diccionario de datos o catálogo accesible
por el usuario que contiene la descripción de los
datos de la base de datos.
A diferencia de los sistemas de ficheros, el SGBD
gestiona la estructura física de los datos y su
almacenamiento. Con esta funcionalidad, el SGBD se convierte en
una herramienta de gran utilidad. Sin embargo, desde el punto de
vista del usuario, se podría discutir que los SGBD han
hecho las cosas más complicadas, ya que ahora los usuarios
ven más datos de los que realmente quieren o necesitan,
puesto que ven la base de datos completa. Conscientes de este
problema, los SGBD proporcionan un mecanismo de vistas que
permite que cada usuario tenga su propia vista o visión de
la base de datos. El lenguaje de definición de datos
permite definir vistas como subconjuntos de la base de
datos.
Las vistas, además de reducir la complejidad
permitiendo que cada usuario vea sólo la parte de la base
de datos que necesita, tienen otras ventajas:
Las vistas proporcionan un nivel de seguridad, ya
que permiten excluir datos para que ciertos usuarios no los
vean.Las vistas proporcionan un mecanismo para que los
usuarios vean los datos en el formato que deseen.Una vista representa una imagen consistente y
permanente de la base de datos, incluso si la base de datos
cambia su estructura.
Todos los SGBD no presentan la misma funcionalidad,
depende de cada producto. En general, los grandes SGBD
multiusuario ofrecen todas las funciones que se acaban de citar y
muchas más. Los sistemas modernos son conjuntos de
programas extremadamente complejos y sofisticados, con millones
de líneas de código y con una documentación
consistente en varios volúmenes. Lo que se pretende es
proporcionar un sistema que permita gestionar cualquier tipo de
requisitos y que tenga un 100% de fiabilidad ante cualquier fallo
hardware o software. Los SGBD están en continua
evolución, tratando de satisfacer los requerimientos de
todo tipo de usuarios. Por ejemplo, muchas aplicaciones de hoy en
día necesitan almacenar imágenes, vídeo,
sonido, etc. Para satisfacer a este mercado, los SGBD deben
cambiar. Conforme vaya pasando el tiempo irán surgiendo
nuevos requisitos, por lo que los SGBD nunca permanecerán
estáticos.
Papeles en el
entorno de Bases de Datos
Hay cuatro grupos de personas que intervienen en el
entorno de una base de datos: el administrador de la base de
datos, los diseñadores de la base de datos, los
programadores de aplicaciones y los usuarios.
El administrador de la base de datos se encarga
del diseño físico de la base de datos y de su
implementación, realiza el control de la seguridad y de la
concurrencia, mantiene el sistema para que siempre se encuentre
operativo y se encarga de que los usuarios y las aplicaciones
obtengan buenas prestaciones. El administrador debe conocer muy
bien el SGBD que se esté utilizando, así como el
equipo informático sobre el que esté
funcionando.
Los diseñadores de la base de datos
realizan el diseño lógico de la base de datos,
debiendo identificar los datos, las relaciones entre datos y las
restricciones sobre los datos y sus relaciones. El
diseñador de la base de datos debe tener un profundo
conocimiento de los datos de la empresa y también debe
conocer sus reglas de negocio. Las reglas de negocio
describen las características principales de los datos tal
y como las ve la empresa.
Para obtener un buen resultado, el diseñador de
la base de datos debe implicar en el desarrollo del modelo de
datos a todos los usuarios de la base de datos, tan pronto como
sea posible. El diseño lógico de la base de datos
es independiente del SGBD concreto que se vaya a utilizar, es
independiente de los programas de aplicación, de los
lenguajes de programación y de cualquier otra
consideración física.
Una vez se ha diseñado e implementado la base de
datos, los programadores de aplicaciones se encargan de
implementar los programas de aplicación que
servirán a los usuarios finales. Estos programas de
aplicación son los que permiten consultar datos,
insertarlos, actualizarlos y eliminarlos. Estos programas se
escriben mediante lenguajes de tercera generación o de
cuarta generación.
Los usuarios finales son los “clientes" de la
base de datos: la base de datos ha sido diseñada e
implementada, y está siendo mantenida, para satisfacer sus
requisitos en la gestión de su
información.
Funciones de los
sistemas de gestión de bases de datos
Codd, el creador del modelo relacional, ha establecido
una lista con los ocho servicios que debe ofrecer todo
SGBD.
Un SGBD debe proporcionar a los usuarios la capacidad de
almacenar datos en la base de datos, acceder a ellos y
actualizarlos. Esta es la función fundamental de un SGBD y
por supuesto, el SGBD debe ocultar al usuario la estructura
física interna (la organización de los ficheros y
las estructuras de almacenamiento).
Un SGBD debe proporcionar un catálogo en el que
se almacenen las descripciones de los datos y que sea accesible
por los usuarios. Este catálogo es lo que se denomina
diccionario de datos y contiene información que describe
los datos de la base de datos (metadatos). Normalmente, un
diccionario de datos almacena:
Nombre, tipo y tamaño de los
datos.Nombre de las relaciones entre los datos.
Restricciones de integridad sobre los
datos.Nombre de los usuarios autorizados a acceder a la
base de datos.Esquemas externos, conceptuales e internos, y
correspondencia entre los esquemas.Estadísticas de utilización, tales
como la frecuencia de las transacciones y el número de
accesos realizados a los objetos de la base de
datos.
Algunos de los beneficios que reporta el diccionario de
datos son los siguientes:
La información sobre los datos se puede
almacenar de un modo centralizado. Esto ayuda a mantener el
control sobre los datos, como un recurso que son.El significado de los datos se puede definir, lo que
ayudará a los usuarios a entender el propósito
de los mismos.La comunicación se simplifica ya que se
almacena el significado exacto. El diccionario de datos
también puede identificar al usuario o usuarios que
poseen los datos o que los acceden.Las redundancias y las inconsistencias se pueden
identificar más fácilmente ya que los datos
están centralizados.Se puede tener un historial de los cambios
realizados sobre la base de datos.El impacto que puede producir un cambio se puede
determinar antes de que sea implementado, ya que el
diccionario de datos mantiene información sobre cada
tipo de dato, todas sus relaciones y todos sus
usuarios.Se puede hacer respetar la seguridad.
Se puede garantizar la integridad.
Se puede proporcionar información para
auditorías.
Un SGBD debe proporcionar un mecanismo que garantice que
todas las actualizaciones correspondientes a una determinada
transacción se realicen, o que no se realice ninguna. Una
transacción es un conjunto de acciones que
cambian el contenido de la base de datos. Una transacción
en el sistema informático de la empresa inmobiliaria
sería dar de alta a un empleado o eliminar un inmueble.
Una transacción un poco más complicada sería
eliminar un empleado y reasignar sus inmuebles a otro empleado.
En este caso hay que realizar varios cambios sobre la base de
datos. Si la transacción falla durante su
realización, por ejemplo porque falla el hardware, la base
de datos quedará en un estado inconsistente. Algunos de
los cambios se habrán hecho y otros no, por lo tanto, los
cambios realizados deberán ser deshechos para devolver la
base de datos a un estado consistente.
Un SGBD debe proporcionar un mecanismo que asegure que
la base de datos se actualice correctamente cuando varios
usuarios la están actualizando concurrentemente. Uno de
los principales objetivos de los SGBD es el permitir que varios
usuarios tengan acceso concurrente a los datos que comparten. El
acceso concurrente es relativamente fácil de gestionar si
todos los usuarios se dedican a leer datos, ya que no pueden
interferir unos con otros. Sin embargo, cuando dos o más
usuarios están accediendo a la base de datos y al menos
uno de ellos está actualizando datos, pueden interferir de
modo que se produzcan inconsistencias en la base de datos. El
SGBD se debe encargar de que estas interferencias no se produzcan
en el acceso simultáneo.
Un SGBD debe proporcionar un mecanismo capaz de
recuperar la base de datos en caso de que ocurra algún
suceso que la dañe. Como se ha comentado antes, cuando el
sistema falla en medio de una transacción, la base de
datos se debe devolver a un estado consistente. Este fallo puede
ser a causa de un fallo en algún dispositivo hardware o un
error del software, que hagan que el SGBD aborte, o puede ser a
causa de que el usuario detecte un error durante la
transacción y la aborte antes de que finalice. En todos
estos casos, el SGBD debe proporcionar un mecanismo capaz de
recuperar la base de datos llevándola a un estado
consistente.
Un SGBD debe proporcionar un mecanismo que garantice que
sólo los usuarios autorizados pueden acceder a la base de
datos. La protección debe ser contra accesos no
autorizados, tanto intencionados como accidentales.
Un SGBD debe ser capaz de integrarse con algún
software de comunicación. Muchos usuarios acceden a la
base de datos desde terminales. En ocasiones estos terminales se
encuentran conectados directamente a la máquina sobre la
que funciona el SGBD. En otras ocasiones los terminales
están en lugares remotos, por lo que la
comunicación con la máquina que alberga al SGBD se
debe hacer a través de una red. En cualquiera de los dos
casos, el SGBD recibe peticiones en forma de mensajes y responde
de modo similar. Todas estas transmisiones de mensajes las maneja
el gestor de comunicaciones de datos. Aunque este gestor no forma
parte del SGBD, es necesario que el SGBD se pueda integrar con
él para que el sistema sea comercialmente
viable.
Un SGBD debe proporcionar los medios necesarios para
garantizar que tanto los datos de la base de datos, como los
cambios que se realizan sobre estos datos, sigan ciertas reglas.
La integridad de la base de datos requiere la validez y
consistencia de los datos almacenados. Se puede considerar como
otro modo de proteger la base de datos, pero además de
tener que ver con la seguridad, tiene otras implicaciones. La
integridad se ocupa de la calidad de los datos. Normalmente se
expresa mediante restricciones, que son una serie de reglas que
la base de datos no puede violar. Por ejemplo, se puede
establecer la restricción de que cada empleado no puede
tener asignados más de diez inmuebles. En este caso
sería deseable que el SGBD controlara que no se sobrepase
este límite cada vez que se asigne un inmueble a un
empleado.
Además, de estos ocho servicios, es razonable
esperar que los SGBD proporcionen un par de servicios
más:
Un SGBD debe permitir que se mantenga la independencia
entre los programas y la estructura de la base de datos. La
independencia de datos se alcanza mediante las vistas o
subesquemas. La independencia de datos física es
más fácil de alcanzar, de hecho hay varios tipos de
cambios que se pueden realizar sobre la estructura física
de la base de datos sin afectar a las vistas. Sin embargo, lograr
una completa independencia de datos lógica es más
difícil. Añadir una nueva entidad, un atributo o
una relación puede ser sencillo, pero no es tan sencillo
eliminarlos.
Un SGBD debe proporcionar una serie de herramientas que
permitan administrar la base de datos de modo efectivo. Algunas
herramientas trabajan a nivel externo, por lo que habrán
sido producidas por el administrador de la base de datos. Las
herramientas que trabajan a nivel interno deben ser
proporcionadas por el distribuidor del SGBD. Algunas de ellas
son:
Herramientas para importar y exportar
datos.Herramientas para monitorizar el uso y el
funcionamiento de la base de datos.Programas de análisis estadístico para
examinar las prestaciones o las estadísticas de
utilización.Herramientas para reorganización de
índices.Herramientas para aprovechar el espacio dejado en el
almacenamiento físico por los registros borrados y que
consoliden el espacio liberado para reutilizarlo cuando sea
necesario.
COMPONENTES DE UN SISTEMA DE GESTIÓN
DE BASES DE DATOS
Los SGBD son paquetes de software muy complejo y
sofisticado que deben proporcionar los servicios comentados en la
sección anterior. No se puede generalizar sobre los
elementos que componen un SGBD ya que varían mucho unos de
otros. Sin embargo, es muy útil conocer sus componentes y
cómo se relacionan cuando se trata de comprender lo que es
un sistema de bases de datos.
Un SGBD tiene varios módulos, cada uno de los
cuales realiza una función específica. El sistema
operativo proporciona servicios básicos al SGBD, que es
construido sobre él.
El procesador de consultas es el componente
principal de un SGBD. Transforma las consultas en un conjunto
de instrucciones de bajo nivel que se dirigen al gestor de la
base de datos.El gestor de la base de datos es el
interface con los programas de aplicación y las
consultas de los usuarios. El gestor de la base de datos
acepta consultas y examina los esquemas externo y conceptual
para determinar qué registros se requieren para
satisfacer la petición. Entonces el gestor de la base
de datos realiza una llamada al gestor de ficheros para
ejecutar la petición.El gestor de ficheros maneja los ficheros
en disco en donde se almacena la base de datos. Este gestor
establece y mantiene la lista de estructuras e índices
definidos en el esquema interno. Si se utilizan ficheros
dispersos, llama a la función de dispersión
para generar la dirección de los registros. Pero el
gestor de ficheros no realiza directamente la entrada y
salida de datos. Lo que hace es pasar la petición a
los métodos de acceso del sistema operativo que se
encargan de leer o escribir los datos en el buffer del
sistema.El preprocesador del LMD convierte las
sentencias del LMD embebidas en los programas de
aplicación, en llamadas a funciones estándar
escritas en el lenguaje anfitrión. El preprocesador
del LMD debe trabajar con el procesador de consultas para
generar el código apropiado.El compilador del LDD convierte las
sentencias del LDD en un conjunto de tablas que contienen
metadatos. Estas tablas se almacenan en el diccionario de
datos.El gestor del diccionario controla los
accesos al diccionario de datos y se encarga de mantenerlo.
La mayoría de los componentes del SGBD acceden al
diccionario de datos.Los principales componentes del gestor de la base de
datos son los siguientes:Control de autorización. Este
módulo comprueba que el usuario tiene los permisos
necesarios para llevar a cabo la operación que
solicita.Procesador de comandos. Una vez que el
sistema ha comprobado los permisos del usuario, se pasa el
control al procesador de comandos.Control de la integridad. Cuando una
operación cambia los datos de la base de datos, este
módulo debe comprobar que la operación a
realizar satisface todas las restricciones de integridad
necesarias.Optimizador de consultas. Este
módulo determina la estrategia óptima para la
ejecución de las consultas.Gestor de transacciones. Este módulo
realiza el procesamiento de las transacciones.Planificador (scheduler). Este
módulo es el responsable de asegurar que las
operaciones que se realizan concurrentemente sobre la base de
datos tienen lugar sin conflictos.Gestor de recuperación. Este
módulo garantiza que la base de datos permanece en un
estado consistente en caso de que se produzca algún
fallo.Gestor de buffers. Este módulo es el
responsable de transferir los datos entre memoria principal y
los dispositivos de almacenamiento secundario. A este
módulo también se le denomina gestor de
datos.
Ventajas e
inconvenientes de los sistemas de bases de
datos
Los sistemas de bases de datos presentan numerosas
ventajas que se pueden dividir en dos grupos: las que se deben a
la integración de datos y las que se deben a la interface
común que proporciona el SGBD.
VENTAJAS POR LA INTEGRACIÓN DE
DATOS
Control sobre la redundancia de datos. Los
sistemas de ficheros almacenan varias copias de los mismos
datos en ficheros distintos. Esto hace que se desperdicie
espacio de almacenamiento, además de provocar la falta
de consistencia de datos. En los sistemas de bases de datos
todos estos ficheros están integrados, por lo que no
se almacenan varias copias de los mismos datos. Sin embargo,
en una base de datos no se puede eliminar la redundancia
completamente, ya que en ocasiones es necesaria para modelar
las relaciones entre los datos, o bien es necesaria para
mejorar las prestaciones.Consistencia de datos. Eliminando o
controlando las redundancias de datos se reduce en gran
medida el riesgo de que haya inconsistencias. Si un dato
está almacenado una sola vez, cualquier
actualización se debe realizar sólo una vez, y
está disponible para todos los usuarios
inmediatamente. Si un dato está duplicado y el sistema
conoce esta redundancia, el propio sistema puede encargarse
de garantizar que todas las copias se mantienen consistentes.
Desgraciadamente, no todos los SGBD de hoy en día se
encargan de mantener automáticamente la
consistencia.Más información sobre la misma
cantidad de datos. Al estar todos los datos integrados,
se puede extraer información adicional sobre los
mismos.Compartición de datos. En los
sistemas de ficheros, los ficheros pertenecen a las personas
o a los departamentos que los utilizan. Pero en los sistemas
de bases de datos, la base de datos pertenece a la empresa y
puede ser compartida por todos los usuarios que estén
autorizados. Además, las nuevas aplicaciones que se
vayan creando pueden utilizar los datos de la base de datos
existente.Mantenimiento de estándares. Gracias
a la integración es más fácil respetar
los estándares necesarios, tanto los establecidos a
nivel de la empresa como los nacionales e internacionales.
Estos estándares pueden establecerse sobre el formato
de los datos para facilitar su intercambio, pueden ser
estándares de documentación, procedimientos de
actualización y también reglas de
acceso.
VENTAJAS POR LA EXISTENCIA DEL
SGBD
Mejora en la integridad de datos. La
integridad de la base de datos se refiere a la validez y la
consistencia de los datos almacenados. Normalmente, la
integridad se expresa mediante restricciones o reglas que no
se pueden violar. Estas restricciones se pueden aplicar tanto
a los datos, como a sus relaciones, y es el SGBD quien se
debe encargar de mantenerlas.Mejora en la seguridad. La seguridad de la
base de datos es la protección de la base de datos
frente a usuarios no autorizados. Sin unas buenas medidas de
seguridad, la integración de datos en los sistemas de
bases de datos hace que éstos sean más
vulnerables que en los sistemas de ficheros. Sin embargo, los
SGBD permiten mantener la seguridad mediante el
establecimiento de claves para identificar al personal
autorizado a utilizar la base de datos. Las autorizaciones se
pueden realizar a nivel de operaciones, de modo que un
usuario puede estar autorizado a consultar ciertos datos pero
no a actualizarlos, por ejemplo.Mejora en la accesibilidad a los datos.
Muchos SGBD proporcionan lenguajes de consultas o generadores
de informes que permiten al usuario hacer cualquier tipo de
consulta sobre los datos, sin que sea necesario que un
programador escriba una aplicación que realice tal
tarea.Mejora en la productividad. El SGBD
proporciona muchas de las funciones estándar que el
programador necesita escribir en un sistema de ficheros. A
nivel básico, el SGBD proporciona todas las rutinas de
manejo de ficheros típicas de los programas de
aplicación. El hecho de disponer de estas funciones
permite al programador centrarse mejor en la función
específica requerida por los usuarios, sin tener que
preocuparse de los detalles de implementación de bajo
nivel. Muchos SGBD también proporcionan un entorno de
cuarta generación consistente en un conjunto de
herramientas que simplifican, en gran medida, el desarrollo
de las aplicaciones que acceden a la base de datos. Gracias a
estas herramientas, el programador puede ofrecer una mayor
productividad en un tiempo menor.Mejora en el mantenimiento gracias a la
independencia de datos. En los sistemas de ficheros, las
descripciones de los datos se encuentran inmersas en los
programas de aplicación que los manejan. Esto hace que
los programas sean dependientes de los datos, de modo que un
cambio en su estructura, o un cambio en el modo en que se
almacena en disco, requiere cambios importantes en los
programas cuyos datos se ven afectados. Sin embargo, los SGBD
separan las descripciones de los datos de las aplicaciones.
Esto es lo que se conoce como independencia de datos, gracias
a la cual se simplifica el mantenimiento de las aplicaciones
que acceden a la base de datos.Aumento de la concurrencia. En algunos
sistemas de ficheros, si hay varios usuarios que pueden
acceder simultáneamente a un mismo fichero, es posible
que el acceso interfiera entre ellos de modo que se pierda
información o, incluso, que se pierda la integridad.
La mayoría de los SGBD gestionan el acceso concurrente
a la base de datos y garantizan que no ocurran problemas de
este tipo.Mejora en los servicios de copias de seguridad y
de recuperación ante fallos. Muchos sistemas de
ficheros dejan que sea el usuario quien proporcione las
medidas necesarias para proteger los datos ante fallos en el
sistema o en las aplicaciones. Los usuarios tienen que hacer
copias de seguridad cada día, y si se produce
algún fallo, utilizar estas copias para restaurarlos.
En este caso, todo el trabajo realizado sobre los datos desde
que se hizo la última copia de seguridad se pierde y
se tiene que volver a realizar. Sin embargo, los SGBD
actuales funcionan de modo que se minimiza la cantidad de
trabajo perdido cuando se produce un fallo.
INCONVENIENTES DE LOS SISTEMAS DE BASES DE
DATOS
Complejidad. Los SGBD son conjuntos de
programas muy complejos con una gran funcionalidad. Es
preciso comprender muy bien esta funcionalidad para poder
sacar un buen partido de ellos.Tamaño. Los SGBD son programas
complejos y muy extensos que requieren una gran cantidad de
espacio en disco y de memoria para trabajar de forma
eficiente.Coste económico del SGBD. El coste
de un SGBD varía dependiendo del entorno y de la
funcionalidad que ofrece. Por ejemplo, un SGBD para un
ordenador personal puede costar 500 euros, mientras que un
SGBD para un sistema multiusuario que dé servicio a
cientos de usuarios puede costar entre 10.000 y 100.000
euros. Además, hay que pagar una cuota anual de
mantenimiento que suele ser un porcentaje del precio del
SGBD.Coste del equipamiento adicional. Tanto el
SGBD, como la propia base de datos, pueden hacer que sea
necesario adquirir más espacio de almacenamiento.
Además, para alcanzar las prestaciones deseadas, es
posible que sea necesario adquirir una máquina
más grande o una máquina que se dedique
solamente al SGBD. Todo esto hará que la
implantación de un sistema de bases de datos sea
más cara.Coste de la conversión. En algunas
ocasiones, el coste del SGBD y el coste del equipo
informático que sea necesario adquirir para su buen
funcionamiento, es insignificante comparado al coste de
convertir la aplicación actual en un sistema de bases
de datos. Este coste incluye el coste de enseñar a la
plantilla a utilizar estos sistemas y, probablemente, el
coste del personal especializado para ayudar a realizar la
conversión y poner en marcha el sistema. Este coste es
una de las razones principales por las que algunas empresas y
organizaciones se resisten a cambiar su sistema actual de
ficheros por un sistema de bases de datos.Prestaciones. Un sistema de ficheros
está escrito para una aplicación
específica, por lo que sus prestaciones suelen ser muy
buenas. Sin embargo, los SGBD están escritos para ser
más generales y ser útiles en muchas
aplicaciones, lo que puede hacer que algunas de ellas no sean
tan rápidas como antes.Vulnerable a los fallos. El hecho de que
todo esté centralizado en el SGBD hace que el sistema
sea más vulnerable ante los fallos que puedan
producirse.
Lenguajes de los
sistemas de gestión de bases de datos
Los SGBD deben ofrecer lenguajes e interfaces apropiadas
para cada tipo de usuario: administradores de la base de datos,
diseñadores, programadores de aplicaciones y usuarios
finales.
LENGUAJE DE DEFINICIÓN DE DATOS
Una vez finalizado el diseño de una base de datos
y escogido un SGBD para su implementación, el primer paso
consiste en especificar el esquema conceptual y el esquema
interno de la base de datos, y la correspondencia entre ambos. En
muchos SGBD no se mantiene una separación estricta de
niveles, por lo que el administrador de la base de datos y los
diseñadores utilizan el mismo lenguaje para definir ambos
esquemas, es el lenguaje de definición de datos (LDD). El
SGBD posee un compilador de LDD cuya función consiste en
procesar las sentencias del lenguaje para identificar las
descripciones de los distintos elementos de los esquemas y
almacenar la descripción del esquema en el catálogo
o diccionario de datos. Se dice que el diccionario contiene
metadatos: describe los objetos de la base de datos.
Cuando en un SGBD hay una clara separación entre
los niveles conceptual e interno, el LDD sólo sirve para
especificar el esquema conceptual. Para especificar el esquema
interno se utiliza un lenguaje de definición de
almacenamiento (LDA). Las correspondencias entre ambos esquemas
se pueden especificar en cualquiera de los dos lenguajes. Para
tener una verdadera arquitectura de tres niveles sería
necesario disponer de un tercer lenguaje, el lenguaje de
definición de vistas (LDV), que se utilizaría para
especificar las vistas de los usuarios y su correspondencia con
el esquema conceptual.
LENGUAJES DE CUARTA GENERACIÓN
No existe consenso sobre lo que es un lenguaje de cuarta
generación (4GL). Lo que en un lenguaje de tercera
generación (3GL) como COBOL requiere cientos de
líneas de código, tan solo necesita diez o veinte
líneas en un 4GL. Comparado con un 3GL, que es procedural,
un 4GL es un lenguaje no procedural: el usuario define qué
se debe hacer, no cómo debe hacerse. Los 4GL se apoyan en
unas herramientas de mucho más alto nivel denominadas
herramientas de cuarta generación. El usuario no debe
definir los pasos a seguir en un programa para realizar una
determinada tarea, tan sólo debe definir una serie de
parámetros que estas herramientas utilizarán para
generar un programa de aplicación. Se dice que los 4GL
pueden mejorar la productividad de los programadores en un factor
de 10, aunque se limita el tipo de problemas que pueden resolver.
Los 4GL abarcan:
Lenguajes de presentación, como lenguajes de
consultas y generadores de informes.Lenguajes especializados, como hojas de
cálculo y lenguajes de bases de datos.Generadores de aplicaciones que definen, insertan,
actualizan y obtienen datos de la base de datos.Lenguajes de muy alto nivel que se utilizan para
generar el código de la aplicación.Los lenguajes SQL y QBE son ejemplos de 4GL. Hay
otros tipos de 4GL:Un generador de formularios es una herramienta
interactiva que permite crear rápidamente formularios
de pantalla para introducir o visualizar datos. Los
generadores de formularios permiten que el usuario defina el
aspecto de la pantalla, qué información se debe
visualizar y en qué lugar de la pantalla debe
visualizarse. Algunos generadores de formularios permiten la
creación de atributos derivados utilizando operadores
aritméticos y también permiten especificar
controles para la validación de los datos de
entrada.Un generador de informes es una herramienta para
crear informes a partir de los datos almacenados en la base
de datos. Se parece a un lenguaje de consultas en que permite
al usuario hacer preguntas sobre la base de datos y obtener
información de ella para un informe. Sin embargo, en
el generador de informes se tiene un mayor control sobre el
aspecto de la salida. Se puede dejar que el generador
determine automáticamente el aspecto de la salida o se
puede diseñar ésta para que tenga el aspecto
que desee el usuario final.Un generador de gráficos es una herramienta
para obtener datos de la base de datos y visualizarlos en un
gráfico mostrando tendencias y relaciones entre datos.
Normalmente se pueden diseñar distintos tipos de
gráficos: barras, líneas, etc.Un generador de aplicaciones es una herramienta para
crear programas que hagan de interface entre el usuario y la
base de datos. El uso de un generador de aplicaciones puede
reducir el tiempo que se necesita para diseñar un
programa de aplicación. Los generadores de
aplicaciones constan de procedimientos que realizan las
funciones fundamentales que se utilizan en la mayoría
de los programas. Estos procedimientos están escritos
en un lenguaje de programación de alto nivel y forman
una librería de funciones entre las que escoger. El
usuario especifica qué debe hacer el programa y el
generador de aplicaciones es quien determina cómo
realizar la tarea.
Modelos de
datos
Una de las características fundamentales de los
sistemas de bases de datos es que proporcionan cierto nivel de
abstracción de datos, al ocultar las
características sobre el almacenamiento físico que
la mayoría de usuarios no necesita conocer. Los modelos de
datos son el instrumento principal para ofrecer dicha
abstracción. Un modelo de datos es un conjunto de
conceptos que sirven para describir la estructura de una base de
datos: los datos, las relaciones entre los datos y las
restricciones que deben cumplirse sobre los datos. Los modelos de
datos contienen también un conjunto de operaciones
básicas para la realización de consultas (lecturas)
y actualizaciones de datos. Además, los modelos de datos
más modernos incluyen conceptos para especificar
comportamiento, permitiendo especificar un conjunto de
operaciones definidas por el usuario.
Los modelos de datos se pueden clasificar dependiendo de
los tipos de conceptos que ofrecen para describir la estructura
de la base de datos. Los modelos de datos de alto nivel, o
modelos conceptuales, disponen de conceptos muy cercanos al modo
en que la mayoría de los usuarios percibe los datos,
mientras que los modelos de datos de bajo nivel, o modelos
físicos, proporcionan conceptos que describen los detalles
de cómo se almacenan los datos en el ordenador. Los
conceptos de los modelos físicos están dirigidos al
personal informático, no a los usuarios finales. Entre
estos dos extremos se encuentran los modelos lógicos,
cuyos conceptos pueden ser entendidos por los usuarios finales,
aunque no están demasiado alejados de la forma en que los
datos se organizan físicamente. Los modelos lógicos
ocultan algunos detalles de cómo se almacenan los datos,
pero pueden implementarse de manera directa en un
ordenador.
Los modelos conceptuales utilizan conceptos como
entidades, atributos y relaciones. Una entidad representa un
objeto o concepto del mundo real como, por ejemplo, un empleado
de la empresa inmobiliaria o una oficina. Un atributo representa
alguna propiedad de interés de una entidad como, por
ejemplo, el nombre o el salario del empleado. Una relación
describe una interacción entre dos o más entidades,
por ejemplo, la relación de trabajo entre un empleado y su
oficina.
Cada SGBD soporta un modelo lógico, siendo los
más comunes el relacional, el de red y el
jerárquico. Estos modelos representan los datos
valiéndose de estructuras de registros, por lo que
también se denominan modelos orientados a registros. Hay
una nueva familia de modelos lógicos, son los modelos
orientados a objetos, que están más próximos
a los modelos conceptuales.
Los modelos físicos describen cómo se
almacenan los datos en el ordenador: el formato de los registros,
la estructura de los ficheros (desordenados, ordenados, etc.) y
los métodos de acceso utilizados (índices,
etc.).
A la descripción de una base de datos mediante un
modelo de datos se le denomina esquema de la base de datos. Este
esquema se especifica durante el diseño, y no es de
esperar que se modifique a menudo. Sin embargo, los datos que se
almacenan en la base de datos pueden cambiar con mucha
frecuencia: se insertan datos, se actualizan, etc. Los datos que
la base de datos contiene en un determinado momento se denominan
estado de la base de datos u ocurrencia de la base de
datos.
La distinción entre el esquema y el estado de la
base de datos es muy importante. Cuando definimos una nueva base
de datos, sólo especificamos su esquema al SGBD. En ese
momento, el estado de la base de datos es el “estado
vacío", sin datos. Cuando se cargan datos por primera vez,
la base datos pasa al “estado inicial". De ahí en
adelante, siempre que se realice una operación de
actualización de la base de datos, se tendrá un
nuevo estado. El SGBD se encarga, en parte, de garantizar que
todos los estados de la base de datos sean estados válidos
que satisfagan la estructura y las restricciones especificadas en
el esquema. Por lo tanto, es muy importante que el esquema que se
especifique al SGBD sea correcto y se debe tener muchísimo
cuidado al diseñarlo. El SGBD almacena el esquema en su
catálogo o diccionario de datos, de modo que se pueda
consultar siempre que sea necesario.

Clasificación de los sistemas de
gestión de bases de datos
PRIMER CRITERIO
El criterio principal que se utiliza para clasificar los
SGBD es el modelo lógico en que se basan. Los modelos
lógicos empleados con mayor frecuencia en los SGBD
comerciales actuales son el relacional, el de red y el
jerárquico. Algunos SGBD más modernos se basan en
modelos orientados a objetos.
MODELOS LOGICOS BASADOS EN OBJETOS
Los modelos lógicos basados en objetos se usan
para describir datos en los niveles conceptual y de
visión. Se caracteriza por el hecho de que proporciona
capacidad de estructuración bastante flexible y permiten
especificar restricciones de datos explícitamente. Hay
muchos modelos diferentes. Algunos de los más extensamente
conocidos son:
El modelo entidad relación
El modelo orientado a objetos
El modelo binario
El modelo semántico de datos
El modelo infológico
El modelo funcional de datos
El modelo entidad-relación y el modelo orientado
a objetos son representativos de la clase de los modelos
lógicos basados en objetos por lo tanto solo se
definirán estos dos modelo
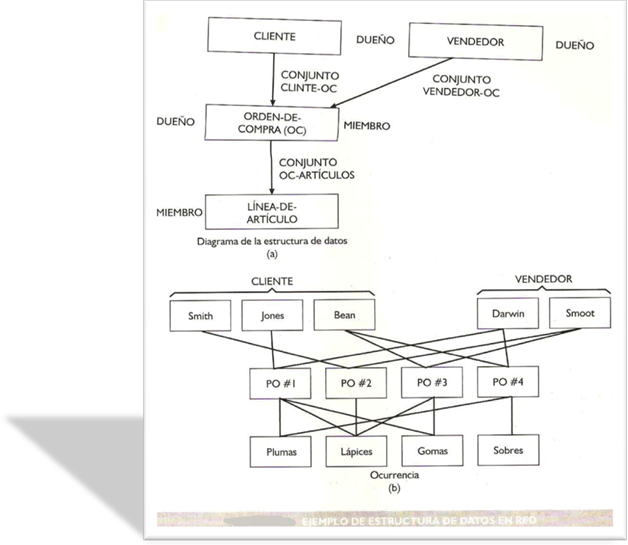
MODELOS ENTIDAD RELACION (E-R)
Se basa en una percepción de un mundo real que
consiste en una colección de objetos básicos
llamados entidades, y relación entre estos objetos. Una
entidad es un objeto que es distinguible de otros objetos pro
medio de un conjunto específico de atributos
Ejemplo:
Los atributos numero y saldo describen una cuenta
particular de un banco. Una relación es una
asociación entre varias entidades. Una relación
CLICTA asocia a un cliente con cada una de las cuentas que tiene.
El conjunto de todas las entidades del mismo tipo y relaciones
del mismo tipo se denomina conjunto de entidades y conjunto de
relaciones, respectivamente.
Además de entidades y relaciones el modelo
representa ciertas restricciones a las que deben ajustarse los
contenidos de una base de datos. Una restricción
importante es la de cardinalidad de asignación, que
expresa e numero de entidades a las que puede asociarse otra
entidad mediante un conjunto de relación.
La estructura lógica global de una base de datos
puede expresarse gráficamente por medio de un diagrama
E-R, que consta de los siguientes componentes:
Rectángulos, que representan conjuntos de
entidadesElipses, que representan atributos
Rombos, que representan relaciones entre conjuntos
de entidades.Líneas, que conectan atributos a conjuntos de
entidades y conjuntos de entidades a
relación

MODELO ORIENTADO A OBJETOS
Al igual que el modelo E-R, el modelo orientado a
objetos se basa en una colección de objetos. Un objeto
contiene valores almacenados en variables instancia dentro del
objeto. A diferencia de los modelos orientados a registros, estos
valores son objetos por si mismos. Así los objetos
contienen objetos a un nivel de anidamiento de profundidad
arbitraria. Un objeto también contiene partes de
código que operan sobre el objeto. Estas partes se llaman
métodos.
Los objetos que contienen lo mismos tipos de valores y
los mismos métodos se agrupan en clases. Una clase puede
ser vista como una definición de tipo para objetos esta
combinación de datos y código en una
definición de tipo es parecida al concepto de tipos de
datos abstractos en leguajes de programación.
La única forma en la que un objeto puede acceder
a los datos de otro objeto es invocando a un método de ese
otro objeto. Esto se llama envió de un mensaje al objeto.
Así, la interfaz de llamada de los métodos de un
objeto define su parte visible externamente. La parte interna del
objeto-las variables de instancia y el código de
método- no son visibles externamente. El resultado es dos
niveles de abstracción de datos.
Ejemplo:
Considérese un objeto que representa una cuenta
bancaria. Dicho objeto contiene las variables instancia numero y
saldo, que representan el numero de cuenta y el saldo de cuenta.
Contiene un método interés de pago que añade
interés al saldo supóngase que el banco
había estado pagando el 6 % de interés en todas las
cuentas pero ahora esta cambiando su política a pagar el
5% si el saldo es menor de 1000 dólares o el 6% si el
saldo es 1000 dólares. Bajo la mayoría de los
modelos de datos, esto implicaría cambiar de código
en uno a mas programas de aplicación. Bajo el modelo
orientado a objetos solo se hace un cambio dentro del
método interés de pago. El interfaz externo del
objeto permanece sin cambios.
A diferencia de las entidades en el modelo E-R, cada
objeto tiene su propia identidad única independiente de
los valores que contiene. La distinción entre objetos
individuales se mantiene en el nivel físico por medio de
identificadores de objeto.

MODELOS LÓGICOS BASADOS EN
REGISTROS
Los modelos lógicos basados en registros se
utilizan para describir datos en los modelos conceptual y
físico. A diferencia de los modelos de datos basados en
objetos, se usan para especificar la estructura lógica
global de la base de datos y para proporcionar una
descripción a nivel más alto de la
implementación.
Se llaman así por que la base de datos esta
estructurada en registros de formato fijo de varios tipos. Cada
tipo de registro define un número fijo de campos, o
atributos, y cada campo normalmente es de longitud fija. Esto
contrasta con muchos delos modelos orientados a objetos en los
que los objetos pueden contener otros objetos a un nivel de
anidamiento de profundidad arbitraria.
Los tres modelos de datos más ampliamente
aceptados son los:
Modelo relacional
Modelo de red
Modelo jerárquico
MODELO RELACIONAL
El modelo relacional se basa en el concepto
matemático denominado “relación", que
gráficamente se puede representar como una tabla. En el
modelo relacional, los datos y las relaciones existentes entre
los datos se representan mediante estas relaciones
matemáticas, cada una con un nombre que es único y
con un conjunto de columnas.
En el modelo relacional la base de datos es percibida
por el usuario como un conjunto de tablas. Esta percepción
es sólo a nivel lógico (en los niveles externo y
conceptual de la arquitectura de tres niveles), ya que a nivel
físico puede estar implementada mediante distintas
estructuras de almacenamiento.

MODELO DE RED
En el modelo de red los datos se representan como
colecciones de registros y las relaciones entre los datos se
representan mediante conjuntos, que son punteros en la
implementación física. Los registros se organizan
como un grafo: los registros son los nodos y los arcos son los
conjuntos. El SGBD de red más popular es el sistema
IDMS.
MODELO JERARQUICO
El modelo jerárquico es un tipo de modelo de red
con algunas restricciones. De nuevo los datos se representan como
colecciones de registros y las relaciones entre los datos se
representan mediante conjuntos. Sin embargo, en el modelo
jerárquico cada nodo puede tener un solo padre. Una base
de datos jerárquica puede representarse mediante un
árbol: los registros son los nodos, también
denominados segmentos, y los arcos son los conjuntos. El SGBD
jerárquico más importante es el sistema
IMS.
La mayoría de los SGBD comerciales actuales
están basados en el modelo relacional, mientras que los
sistemas más antiguos estaban basados en el modelo de red
o el modelo jerárquico. Estos dos últimos modelos
requieren que el usuario tenga conocimiento de la estructura
física de la base de datos a la que se accede, mientras
que el modelo relacional proporciona una mayor independencia de
datos. Se dice que el modelo relacional es declarativo (se
especifica qué datos se han de obtener) y los modelos de
red y jerárquico son navegacionales (se especifica
cómo se deben obtener los datos).

SEGUNDO CRITERIO
Un segundo criterio para clasificar los SGBD es el
número de usuarios a los que da servicio el
sistema.
MONOUSUARIO: Los sistemas mono usuario
sólo atienden a un usuario a la vez, y su principal uso se
da en los ordenadores personales.
MULTIUSUARIO: Los sistemas multiusuario, entre
los que se encuentran la mayor parte de los SGBD, atienden a
varios usuarios al mismo tiempo.
TERCER CRITERIO
Un tercer criterio es el número de sitios en los
que está distribuida la base de datos. Casi todos los SGBD
son:
CENTRALIZADOS: sus datos se almacenan en un solo
computador. Los SGBD centralizados pueden atender a varios
usuarios, pero el SGBD y la base de datos en sí residen
por completo en una sola máquina.
DISTRIBUIDOS: En los SGBD distribuidos
la base de datos real y el propio software del SGBD pueden estar
distribuidos en varios sitios conectados por una red. Los SGBD
distribuidos homogéneos utilizan el mismo SGBD en
múltiples sitios. Una tendencia reciente consiste en crear
software para tener acceso a varias bases de datos
autónomas preexistentes almacenadas en SGBD
distribuidos heterogéneos. Esto da lugar a los
SGBD federados o sistemas multibase de datos en
los que los SGBD participantes tienen cierto grado de
autonomía local. Muchos SGBD distribuidos emplean una
arquitectura cliente-servidor.
CUARTO CRITERIO
Un cuarto criterio es el coste del SGBD. La mayor parte
de los paquetes de SGBD cuestan entre 10.000 y 100.000 euros. Los
sistemas mono usuario más económicos para
microcomputadores cuestan entre 100 y 3.000 euros. En el otro
extremo, los paquetes más completos cuestan más de
100.000 euros.
Por último, los SGBD pueden ser de
propósito general o de propósito
específico. Cuando el rendimiento es fundamental, se
puede diseñar y construir un SGBD de propósito
especial para una aplicación específica, y este
sistema no sirve para otras aplicaciones. Muchos sistemas de
reservas de líneas aéreas son SGBD de
propósito especial y pertenecen a la categoría de
sistemas de procesamiento de transacciones en
línea (OLTP), que deben atender un gran número
de transacciones concurrentes sin imponer excesivos
retrasos.
Software
existente en el mercado y modelo que usa
ADAPTIVE SERVER ENTERPRISE (ASE)
Es el motor de bases de datos (RDBMS) insignia de la
compañía Sybase. ASE es un sistema de
gestión de datos, altamente escalable, de alto
rendimiento, con soporte a grandes volúmenes de datos,
transacciones y usuarios, y de bajo costo, que permite:
Almacenar datos de manera segura
Tener acceso y procesar datos de manera inteligente
Movilizar datos
HISTORIA
ASE es directo descendiente de Sybase SQL Server (lanzada al
mercado en 1988 como la primera base de datos con arquitectura
cliente/servidor) y su cambio de nombre se produjo a partir de la
versión 11.5, en 1996, para evitar confusiones con
Microsoft SQL Server, con el que comparte un origen común
(Sybase licenció el código a Microsoft para el
sistema operativo Windows). En 1998, se lanzó ASE 11.9.2,
con soporte al bloqueo a nivel de registro y rendimiento mejorado
en ambientes SMP. ASE 12.0 fue liberado en 1999, brindando
soporte para Java en la base de datos, alta disponibilidad y
gestión de transacciones distribuidas. En 2001, ASE 12.5
fue lanzada, con características tales como
asignación dinámica de memoria, soporte para XML en
la base de datos y conexiones seguras con SSL, entre otros. En
septiembre de 2005, Sybase lanzó al mercado ASE 15.
PRINCIPALES CARACTERÍSTICAS
La versión 15 de ASE incluye características
nuevas como:
Un optimizador de consultas completamente renovado y
más inteligenteTécnicas de particionamiento semántico de
tablas que aumentan la velocidad de acceso a los datosColumnas cifradas para mayor seguridad de los datos
Columnas computadas "virtuales" y materializadas, e
índices funcionales, que brindan mayor rendimientoMejoras al lenguaje Transact-SQL, para mayor
productividadMejoras a los servicios de Java y XML en la base de
datosMejoras a los servicios para consumo y publicación
de Servicios WebHerramientas mejoradas para la administración y el
monitoreoMás rendimiento y menor costo total de
propiedad
Otras características generales:
Arquitectura VSA de Sybase
Administrador lógico de recursos y tareas
Múltiples esquemas de bloqueo de datos
Copias de respaldo en línea y de alto
rendimientoIntegración transparente con orígenes de
datos remotosProgramador de tareas
Conexiones seguras con SSL
Soporte a LDAP para autenticación de usuarios y
conectividad cliente/servidorSoporte a múltiples herramientas de desarrollo y
lenguajes de programación, como PowerBuilder, Visual
Basic, Java, C, PHP, etc.Soporte a múltiples protocolos de conectividad,
como Open Client (propio de Sybase), ODBC, OLE DB, ADO.NET y
JDBC.
GNU/LINUX
Es uno de los términos empleados para referirse a la
combinación del núcleo o kernel libre similar a
Unix denominado Linux, que es usado con herramientas de sistema
GNU. Su desarrollo es uno de los ejemplos más prominentes
de software libre; todo su código fuente puede ser
utilizado, modificado y redistribuido libremente por cualquiera
bajo los términos de la GPL (Licencia Pública
General de GNU) y otra serie de licencias libres.
A pesar de que Linux (núcleo) es, en sentido estricto,
el sistema operativo, parte fundamental de la interacción
entre el núcleo y el usuario (o los programas de
aplicación) se maneja usualmente con las herramientas del
proyecto GNU o de otros proyectos como GNOME. Sin embargo, una
parte significativa de la comunidad, así como muchos
medios generales y especializados, prefieren utilizar el
término Linux para referirse a la unión de ambos
proyectos. Para más información consulte la
sección "Denominación GNU/Linux" o el
artículo "Controversia por la denominación
GNU/Linux".
A las variantes de esta unión de programas y
tecnologías, a las que se les adicionan diversos programas
de aplicación de propósitos específicos o
generales se las denomina distribuciones. Su objetivo consiste en
ofrecer ediciones que cumplan con las necesidades de un
determinado grupo de usuarios. Algunas de ellas son especialmente
conocidas por su uso en servidores y supercomputadoras. Donde
tiene la cuota mas importante del mercado. Según un
informe de IDC, GNU/Linux es utilizado por el 78% de los
principales 500 servidores del mundo, otro informe le da una
cuota de mercado de % 89 en los 500 mayores supercomputadores.
Con menor cuota de mercado el sistema GNU/Linux también es
usado en el segmento de las computadoras de escritorio,
portátiles, computadoras de bolsillo, teléfonos
móviles, sistemas embebidos, videoconsolas y otros
dispositivos.
ETIMOLOGÍA
El nombre GNU, GNU's Not Unix (GNU no es Unix), viene de las
herramientas básicas de sistema operativo creadas por el
proyecto GNU, iniciado por Richard Stallman en 1983 y mantenido
por la FSF. El nombre Linux viene del núcleo Linux,
inicialmente escrito por Linus Torvalds en 1991.
La contribución de GNU es la razón por la que
existe controversia a la hora de utilizar Linux o GNU/Linux para
referirse al sistema operativo formado por las herramientas de
GNU y el núcleo Linux en su conjunto.
HISTORIA
Richard Matthew Stallman, iniciador del proyecto GNU. Linus
Torvalds, creador del núcleo Linux. Artículos
principales: Historia de Linux y Historia del proyecto GNU
El proyecto GNU, fue iniciado en 1983 por Richard
Stallman,[tiene como objetivo el desarrollo de un sistema
operativo Unix completo compuesto enteramente de software libre.
La historia del núcleo Linux está fuertemente
vinculada a la del proyecto GNU. En 1991 Linus Torvalds
empezó a trabajar en un reemplazo no comercial para MINIX
que más adelante acabaría siendo Linux.
Cuando Torvalds liberó la primera versión de
Linux, el proyecto GNU ya había producido varias de las
herramientas fundamentales para el manejo del sistema operativo,
incluyendo un intérprete de comandos, una biblioteca C y
un compilador, pero como el proyecto contaba con una
infraestructura para crear su propio sistema operativo, el
llamado Hurd, y este aún no era lo suficiente maduro para
usarse, comenzaron a usar a Linux a modo de continuar
desarrollando el proyecto GNU, siguiendo la tradicional
filosofía de mantener cooperatividad entre
desarrolladores. El día en que se estime que Hurd es
suficiente maduro y estable, será llamado a reemplazar a
Linux.
Entonces, el núcleo creado por Linus Torvalds, quien se
encontraba por entonces estudiando en la Universidad de Helsinki,
llenó el "espacio" final que había en el sistema
operativo de GNU.
VENTAJAS
La creciente popularidad de GNU/Linux se debe, entre otras
razones, a su estabilidad, al acceso al código fuente (lo
que permite personalizar el funcionamiento y auditar la seguridad
y privacidad de los datos tratados), a la independencia de
proveedor, a la seguridad, a la rapidez con que incorpora los
nuevos adelantos tecnológicos (IPv6, microprocesadores de
64 bits), a la escalabilidad (se pueden crear clusters de cientos
de computadoras), a la activa comunidad de desarrollo que hay a
su alrededor, a su interoperatibilidad y a la abundancia de
documentación relativa a los procedimientos.
IBM Roadrunner, la supercomputadora más potente de
2008, funciona bajo una distribución Gnu/LinuxHay varias
empresas que comercializan soluciones basadas en GNU/Linux: IBM,
Novell (SuSE), Red Hat (RHEL), Mandriva (Mandriva Linux), Rxart,
Canonical Ltd. (Ubuntu), así como miles de PYMES que
ofrecen productos o servicios basados en esta
tecnología.
SUPERCOMPUTADORAS
Dentro del segmento de supercomputadoras, a noviembre de 2009,
el uso de este sistema ascendió al 89,2% de las
computadoras más potentes del mundo por su confiabilidad,
seguridad y libertad para modificar el código. De acuerdo
con TOP500.org, que lleva estadísticas sobre las 500
principales supercomputadoras del mundo, a noviembre de 2009: 446
usaban una distribución basada en GNU/Linux, 25 Unix, 23
mezclas, 1 BSD y solo el 1% Windows.
Las primeras 19 supercomputadoras, incluidas la número
1 la Jaguar, Cray XT5-HE con 224,162 procesadores utilizan
distribuciones basadas en Gnu/Linux.
GNU/Linux, además de liderar el mercado de servidores
de Internet debido, entre otras cosas, a la gran cantidad de
soluciones que tiene para este segmento, tiene un crecimiento
progresivo en computadoras de escritorio y portátiles.
Además, es el sistema base que se ha elegido para el
proyecto OLPC: One Laptop Per Child.
Para saber más sobre las arquitecturas soportadas, lea
el artículo "Portabilidad del núcleo Linux y
arquitecturas soportadas".
ADMINISTRACIÓN PÚBLICA
Véase también: Software libre en la
administración pública
Hay una serie de administraciones públicas que han
mostrado su apoyo al software libre, sea migrando total o
parcialmente sus servidores y sistemas de escritorio, sea
subvencionándolo. Como ejemplos se tiene a Alemania,
Argentina, Australia, Brasil, España, Chile, China, Cuba,
México, Perú, República Dominicana, Ecuador,
El Salvador, Uruguay o Venezuela.
APACHE DERBY

Sistema de gerencia de base de datos emparentada eso se puede
encajar en los programas de Java y utilizar para tratamiento
transaccional en línea. Tiene 2 MB huella del
disco-espacio. Apache Derby se desarrolla como abra la fuente
proyecto debajo de la Licencia de Apache 2.0. Derby fue
distribuido previamente como IBM Cloudscape y Sol DB de Java.
TECNOLOGÍAS DE DERBY
La base de la tecnología, motor de la base de datos de
Derby es un motor encajado emparentado por completo funcionado de
la base de datos. JDBC y SQL es el APIs de
programación.
SERVIDOR DE LA RED DE DERBY
El servidor de la red de Derby aumenta el alcance del motor de
la base de datos de Derby proporcionando funcionalidad
tradicional del servidor de cliente. El servidor de la red
permite que los clientes conecten el TCP/IP excesivo usando el
estándar DRDA protocolo. El servidor de la red permite que
el motor de Derby apoye networked JDBC, ODBC/CLI, Perl y
PHP..
UTILIDADES DE BASE DE DATOS
ij – una herramienta que permite que
las escrituras del SQL sean ejecutadas contra cualquier base
de datos de JDBC.dblook – herramienta de la
extracción del esquema para una base de datos de
Derby.sysinfo – utilidad para exhibir la
trayectoria de los números y de la clase de
versión.
HISTORIA
Apache Derby originó en Cloudscape inc., Oakland,
California start-up fundado adentro 1996 para desarrollar Java
base de datos tecnología. El primer lanzamiento del motor
de la base de datos, entonces llamado JBMS, estaba adentro 1997.
Posteriormente el producto fue retitulado Cloudscape y los
lanzamientos fueron hechos alrededor cada seis meses.
En 1999 Informix Software, Inc., Cloudscape adquirido, Inc. En
2001 IBM adquirió los activos de la base de datos del
software de Informix, incluyendo Cloudscape. El motor de la base
de datos re-fue calificado a IBM Cloudscape y lanzamientos
continuados, principalmente centrándose en uso encajado
con los productos y el middleware de Java de IBM.
 Página anterior Página anterior | Volver al principio del trabajo | Página siguiente  |