Página anterior Página anterior | Voltar ao início do trabalho | Página seguinte  |
|
11 - CTI |
-.43342 |
1.19580 |
-.06657 |
|
12 - TCPU |
-.66878 |
-.12037 |
-.00456 |
|
13 - TCPA |
-.02927 |
-.71687 |
.00465 |
|
14 - ELECTR |
-.64543 |
1.40024 |
-.09538 |
|
15 - CO2 |
-.88947 |
1.74889 |
-.26142 |
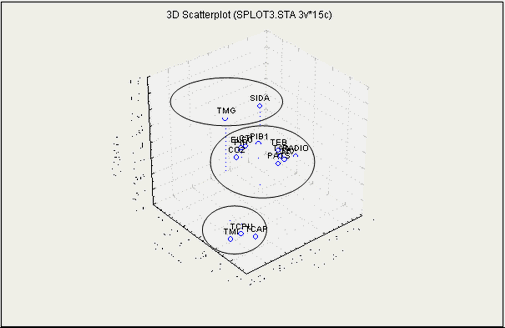
Figura 2 - relação entre as variáveis e os componentes no espaço rodado

Figura 3 - relação entre as variáveis e os componentes no espaço rodado
2.2.7 - Scores proporcionais à importância dos componentes
Relativamente ao agrupamento ou classificação dos países, observando os Quadros XIII e XIV, que apresentam, respectivamente, os scores proporcionais à importância dos componentes e os scores padronizados, e recorrendo-nos da análise da Figura 4, Portugal apresenta scores mais elevados e de forma destacada no Componente_2, que, como foi dito, é o componente do consumo.
Quadro xiii - scores proporcionais a importância dos componentes
|
Componente_1 |
Componente_2 |
Componente_3 |
|
|
Portugal |
2.78 |
12.30 |
-0.09 |
|
Brasil |
7.69 |
-0.21 |
1.10 |
|
Cabo Verde |
2.48 |
-3.51 |
1.13 |
|
São Tomé |
7.72 |
-5.74 |
-1.73 |
|
Angola |
-7.09 |
-0.33 |
-2.05 |
|
Guiné Bissau |
-6.37 |
-0.05 |
-0.54 |
|
Moçambique |
-7.20 |
-2.46 |
2.17 |
Quadro xiv - scores padronizados
|
Componente_1 |
Componente_2 |
Componente_3 |
|
|
Portugal |
0,41042 |
2,11574 |
-0,05566 |
|
Brasil |
1,13497 |
-0,03547 |
0,70249 |
|
Cabo Verde |
0,36560 |
-0,60343 |
0,72179 |
|
São Tomé |
1,13966 |
-0,98753 |
-1,10370 |
|
Angola |
-1,04709 |
-0,05669 |
-1,30999 |
|
Guiné Bissau |
-0,94105 |
-0,00866 |
-0,34411 |
|
Moçambique |
-1,06251 |
-0,42396 |
1,38917 |
Os restantes países podem ser divididos em dois grupos, com características internas ainda bem distintas, um englobando o Brasil, Cabo Verde e São Tomé e Príncipe, e o outro englobando Angola, Guiné-Bissau e Moçambique, tal como se pode concluir a partir da análise da Figura 4.
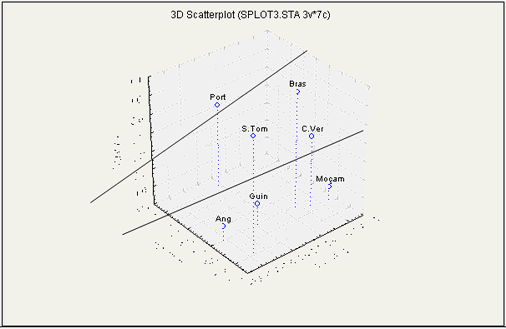
Figura 4 - relação entre os países e os componentes no espaço rodado
Convém referir o facto de Moçambique apresentar elevados scores no Componente_3, que se explica pelos valores elevados de população infectada pelo virús HIV.
Concluindo: três grupos de países:
No capítulo seguinte continuaremos e aprofundaremos este assunto, para tal recorrendo a outra técnica de classificação: as toxonomias numéricas.
2.1 - Aspectos gerais
2.2 - Estratégias de classificação
2.3 - Processo de classificação
Quando se analisa o universo das unidades de análise, o objectivo fundamental é o de procurar a semelhança (ou a distância) entre as unidades de análise de modo a perceber como é que se agrupam, ou por que é que se agrupam, face aos valores que têm nas respectivas variáveis.
Quando o objectivo é conhecer o modo como se agrupam as unidades de análise, utilizam-se as técnicas de classificação ou taxonomias numéricas.
Este processo de procurar as proximidades entre as unidades de análise é o equivalente à análise dos diagramas de dispersão, mas se nestes apenas é possível considerar dois eixos no gráfico, a que correspondem só duas variáveis, as taxonomias numéricas podem considerar mais do que duas variáveis. Para isso é necessário que as variáveis sejam comparáveis.
As taxonomias numéricas têm por objectivo agrupar os indivíduos num número restrito de classes homogéneas. Trata-se, então, de descrever os dados procedendo a uma redução do número de indivíduos.
As classes são obtidas por meio de algoritmos formalizados e não por métodos subjectivos ou visuais fazendo apelo à iniciativa do investigador.
Distinguem-se dois grandes tipos de métodos de classificação:
Existem, assim, diversos métodos, mas todos eles procuram organizar as unidades de análise em grupos ou classes. As técnicas hierárquicas são as mais aplicadas.
2.2 - Estratégias de classificação
Dentro dos métodos de classificação existem muitas alternativas.
A primeira questão a ser formulada é que o propósito é identificar agrupamentos distintos ou «naturais» de indivíduos e o que poderia ser chamado um bem-estruturado conjunto de dados, ou dividir um grupo de uma forma mais arbitrária, em que é uma colecção homogénea de indivíduos.
Convém distinguir ordenação (ou ordenamento á subdivisão num conjunto homogéneo) de classificação (em que distintos grupos são definidos).
Adicionalmente, estes métodos podem ser quantitativos ou qualitativos. A classificação qualitativa frequentemente procede por definição como, por exemplo, no caso de segmentos de um rio que podem ser colocados em classes de acordo com alguma definição à priori.
A classificação quantitativa, no entanto, mais frequentemente procede pela enumeração dos atributos de um conjunto de indivíduos, usando as numerações para determinar os membros mais semelhantes do conjunto.
Os grupos podem ser formados pela divisão lógica de um conjunto completo, que envolve gradualmente a divisão do conjunto em grupos cada vez mais pequenos até que só os indivíduos isolados são deixados; ou o processo pode ser aglomerativo em que os indivíduos formam o ponto de partida e são sucessivamente agrupados até que todos são incluídos num amplo grupo.
Ambas as estratégias são hierárquicas, com grupos de vários tamanhos que se encontram a diferentes níveis. Nesta conexão existe o problema em determinar a que nível de integração ou de desintegração a selecção dos grupos deve ser feita. Se a selecção é muito próxima de um grupo grande então serão feitos muitos pequenos grupos e uma consequente perda de informação e detalhe. Por outro lado, a terminação muito próxima do indivíduo acaba com as causas hierárquicas e generalidades importantes e identidades grupais podem-se perder devido à super-abundância de pequenos grupos.
2.3 - Processo de classificação
Após a apresentação das estratégias de classificação apresentam-se algumas tácticas através das quais aquelas estratégias são acompanhadas.
Quadro xv - matriz de atributos (países de língua portuguesa)
|
Variáveis |
EMV |
TAA |
TEB |
PIB |
PIB1 |
TMI |
PATS |
TMG |
SIDA |
RADIO |
CTI |
TCPU |
TCAP |
ELECT |
CO2 |
|
Casos |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
14 |
15 |
|
1 - Portugal |
74,8 |
89,6 |
81 |
12674 |
6171 |
7 |
99 |
18 |
7,3 |
245 |
30,2 |
1,3 |
-0,1 |
3482 |
5,3 |
|
2 - Brasil |
66,6 |
83,3 |
72 |
5928 |
5928 |
44 |
88 |
13 |
10,0 |
399 |
13,0 |
1,6 |
1,1 |
1954 |
1,6 |
|
3 - Cabo Verde |
65,7 |
71,6 |
64 |
2612 |
2612 |
54 |
30 |
12 |
8,9 |
179 |
10,0 |
3,7 |
2,1 |
55 |
0,3 |
|
4 - São Tomé |
69,0 |
75,0 |
57 |
1744 |
1744 |
62 |
86 |
4 |
3,0 |
271 |
4,2 |
3,2 |
1,8 |
96 |
0,6 |
|
5 - Angola |
47,4 |
42,0 |
30 |
1839 |
1839 |
170 |
15 |
6 |
1,0 |
34 |
1,7 |
4,9 |
3,1 |
173 |
0,4 |
|
6 - Guiné Bissau |
43,4 |
54,9 |
29 |
811 |
811 |
132 |
27 |
12 |
3,4 |
42 |
2,1 |
4,0 |
2,0 |
40 |
0,2 |
|
7 - Moçambique |
46,3 |
40,1 |
25 |
959 |
959 |
133 |
25 |
13 |
12,6 |
38 |
0,9 |
4,7 |
2,5 |
67 |
0,1 |
Partindo-se duma matriz de atributos (Quadro XV), em que existem uma série de dados correspondentes aos valores das variáveis nos vários países (casos ou unidades de análise), constroi-se uma matriz de distâncias entre os países (Quadro XVI).
Quadro xvi - matriz de distâncias euclideanas (inicial)
|
Portugal |
Brasil |
Cabo Verd |
S. Tomé |
Angola |
Guiné-Biss |
Moçambiq |
|
|
Portugal |
0 |
6923 |
11210 |
12269 |
12133 |
13468 |
13272 |
|
Brasil |
6923 |
0 |
5065 |
6203 |
6064 |
7495 |
7286 |
|
Cabo Ver |
11210 |
5065 |
0 |
1233 |
1116 |
2552 |
2344 |
|
S. Tomé |
12269 |
6203 |
1233 |
0 |
315 |
1344 |
1140 |
|
Angola |
12133 |
6064 |
1116 |
315 |
0 |
1461 |
1250 |
|
Guiné-B |
13468 |
7495 |
2552 |
1344 |
1461 |
0 |
212 |
|
Moçamb |
13272 |
7286 |
2344 |
1140 |
1250 |
212 |
0 |
De seguida, agrupam-se estes, com base em critérios de semelhança, considerando que estão mais próximos, e por isso, devem pertencer ao mesmo grupo ou classe os países que têm valores mais aproximados nas diversas variáveis.
Estas localizações determinam, por seu lado, as distâncias estatísticas (não geográficas) entre os países, e podem ser calculadas por uma aplicação do teorema de Pitágoras. Em termos geométricos, a distância entre os dois Estados é o comprimento da hipotenusa do triângulo rectângulo definido pela localização no gráfico dos dois Estados. Os comprimentos dos outros dois lados do triângulo dependem das diferenças entre os dois valores em cada um dos eixos. A distância D é dada por:
![]()
Em que:
X1i = scores individuais i na variável 1
X1j = scores individuais j na variável 1
X2i = scores individuais i na variável 2
X2j = scores individuais j na variável 2
Dij = distância estatística entre i e j
Este cálculo repete-se para todos os pares de indivíduos e a matriz de distâncias (ou semelhança) pode ser construída.
Desta maneira as distâncias são medidas de semelhança, quanto mais pequena for a distância maior é a semelhança. Através da matriz podemos determinar quais os membros que estão mais próximos para formar um grupo. A partir do Quadro XVI, Guiné-Bissau e Moçambique foram agrupados, os seus lugares foram tomados por uma nova, e única, medida entre eles (o grupo centróide).
A matriz é agora ordenada de forma decrescente e é recalculada para tomar conta no novo ponto. A matriz recalculada vai buscar o valor menor e o processo de junção e recálculo repete-se. Em cada etapa a ordem da matriz decresce por um e o grupo resultante é presumido o acto como o simples ponto localizado no seu centro geométrico. Nesta posição, o grupo centróide, é determinado a partir da média dos pontos individuais ao longo de cada eixo ou dimensão. Por exemplo, o centro do agrupamento de 5 indivíduos deve ser tomado pelas médias dos indicadores (média da EMV, média do PIB, á¦).
O objectivo é rapidamente atingido quando a maioria dos indivíduos são integrados num ou noutro dos grupos emergentes. Mas o processo de «fusão» continua com os próprios grupos até que exista um só grupo.
2.3.1 - Metodologia de agrupamento
Duas questões se colocaram:
Quando se opta por um método de classificação não hierárquica, é necessário indicar o número de grupos a formar. De facto, poucos programas permitem esta alternativa, por isso, escolhemos a classificação hierárquica.
Ao escolher a classificação hierárquica, optámos pela ascendente, pois é a mais utilizada.
2.3.1.1 - Classificação hierárquica
Cada vez que se forma um grupo, este constitui-se por junção (no caso das classificações hierárquicas ascendentes) ou por segmentação (no caso das classificações hierárquicas descendentes) de grupos pré-existentes.
No caso dos métodos ascendentes, o seu princípio consiste em construir uma série de junções em n classes, n-1 classes, n-2 classes, á¦, embutidas umas nas outras, da maneira seguinte: a partição em k classes é obtida agrupando duas das classes da partição de k+1 classes. Existe então, um total de n-2 partições a determinar uma vez que a partição em n classes é aquela onde cada indivíduo é isolado e a partição numa classe não é outra que a reunião de todos os indivíduos.
Fala-se de classificação hierárquica, ou de hierarquia, quando cada classe de uma partição é incluída numa classe da partição seguinte. A seguinte das partições obtidas é usualmente representada sob a forma análoga à de um organigrama duma empresa (dendograma).
Assim, as classificações hierárquicas formam uma sequência de agrupamentos, ou separações de grupos pré-existentes, numa série que vai de n grupos de um elemento a um único grupo final com n elementos. Esta sequência de classes pode ser visualizada por um gráfico esquemático, a que se dá o nome de árvore de ligação, dendograma ou fenograma.
Os dendogramas mostram, com alguma facilidade, o modo como se efectuam as fusões entre indivíduos ou grupos, e a que nível de proximidade ou semelhança elas se efectuam. No gráfico, a relação com a proximidade é dada pela distância vertical entre a base do gráfico, onde estão identificados os países, e a barra horizontal da união dos grupos.
2.3.2 - Estratégias de agrupamento
Depois de escolher uma medida de distância, constroi-se uma matriz de distâncias entre os países. Como estamos perante uma metodologia de agrupamento hierárquico ascendente, o primeiro passo consiste em determinar quais os dois países mais próximos, e constituir com eles um grupo (Guiné e Moçambique).
Depois refaz-se a matriz, e assim sucessivamente. O problema está em como se mede a distância entre um elemento e um grupo, ou entre dois grupos.
Assim, embora os cálculos não sejam difíceis, são repetitivos e fornecem uma longa sequência de resultados que podem ser resumidos sob a forma de um dendograma. Este é um gráfico em que um eixo lista os países e o outro os níveis a que eles, e os seus consequentes sub-grupos, se fundem. Estes níveis são expressos pelas distâncias entre os grupos ao ponto de fusão. O gráfico é completado pela estrutura de ligações.
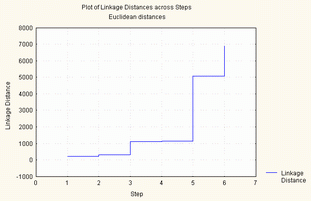
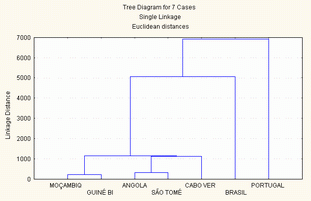
2.3.2.1 - Método do vizinho mais próximo (Single Linkage)
Dadas duas classes a e b, a distância entre elas é dada pelo valor mínimo de todas as distâncias entre todos os elementos de a e todos os elementos de b.
Este método gera grupos bastante heterogéneos, com tendência para formar cadeias. Privilegia o facto de fazer classes ou grupos tão distintos internamente, quanto os atributos o permitem.
|
Passo n.º NovoGrupo AntigosElementos Distancia 1 8 6 7 211.871 2 9 4 5 314.891 3 10 3 9 1116.344 4 11 8 10 1139.862 5 12 2 11 5064.583 6 13 1 12 6923.011 |
|
Amalgamation Schedule
Single Linkage
Euclidean distances
Passo Passo Passo Passo Passo Passo Passo
1 2 3 4 5 6 7
211,8709 Guiné Moçam ,000 ,000 ,000 ,000 ,000
314,8911 S.Tomé Angola ,000 ,000 ,000 ,000 ,000
1116,344 Cabo V S.Tomé Angola ,000 ,000 ,000 ,000
1139,862 Cabo V S.Tomé Angola Guiné Moçam ,000 ,000
5064,583 Brasil Cabo V S.Tomé Angola Guiné Moçam ,000
6923,011 Portug Brasil Cabo V S.Tomé Angola Guiné Moçamb
Figura 5 - método do vizinho mais próximo (single linkage)
Conhecendo o dendograma, é fácil daí deduzir as partições num número mais ou menos elevado de classes, sendo suficiente, para isso, «cortar» o dendograma a um certo nível e ver quais os «ramos» que tombam. Assim, no nosso exemplo, o primeiro grupo a ser formado consistiu na junção de Moçambique e Guiné, posteriormente juntou-se Angola e São Tomé. A este último grupo de dois países juntou-se um terceiro: Cabo Verde. O passo seguinte consistiu no agrupamento de todos os conjuntos feitos até então, agrupando Cabo Verde, S. Tomé, Angola, Guiné e Moçambique. A este agrupamento juntou-se, posteriormente o Brasil, e por último Portugal (Figura 5).
O principal problema dos métodos de classificação hierárquica consiste na definição do critério de agrupamento de duas classes, o que acarreta a definição de uma distância entre as classes. Todos os algoritmos de classificação hierárquica se desenvolvem da mesma maneira: procura-se em cada etapa as duas classes mais próximas, juntam-se, e continua-se até que não haja mais que uma só classe.
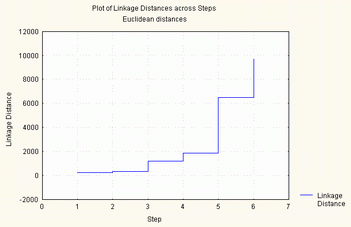
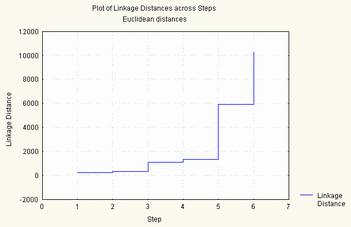
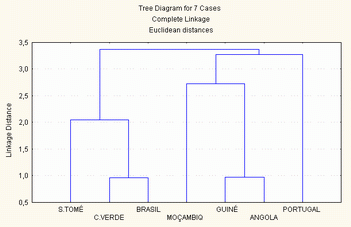
2.3.2.2 - Método do vizinho mais distante (Complete Linkage)
A ligação entre duas classes a e b, é o valor máximo de todas as distâncias entre todos os elementos de a e todos os elementos de b.
Quando se juntam dois grupos, primeiro calculam-se todas as distâncias deste modo, depois, agregam-se os que se encontram à menor distância.
Este método cria grupos muito compactos, que com dificuldade se agregam a outros. Privilegia o facto de fazer grupos tão homogéneos quanto os atributos o permitem.
|
|
|
Amalgamation Schedule
Complete Linkage
Euclidean distances
Passo Passo Passo Passo Passo Passo Passo
1 2 3 4 5 6 7
211,8709 Guiné Bi Moçambiq ,000 ,000 ,000 ,000 ,000
314,8911 São Tomé Angola ,000 ,000 ,000 ,000 ,000
1233,044 Cabo Ver São Tomé Angola ,000 ,000 ,000 ,000
2552,329 Cabo Ver São Tomé Angola Guiné Bi Moçambiq ,000 ,000
6923,011 Portugal Brasil ,000 ,000 ,000 ,000 ,000
13467,57 Portugal Brasil Cabo Ver São Tomé Angola Guiné Bi Moçambiq
Figura 6 - método do vizinho mais distante (complete linkage)
A diferença desta estratégia de agrupamento com a anterior, é que a junção de todos os países se dá a uma distância muito superior, principalmente nos passos mais elevados.
Este método e o anterior dão resultados muito contrastados. Foram, por isso, propostos alguns que procuram a sua conciliação. Em vez de utilizar a menor ou a maior das distâncias de um conjunto usam-se médias dessas distâncias, o que vem a dar uma solução de compromisso entre as duas.
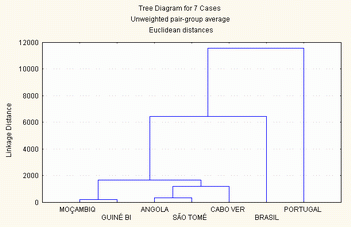
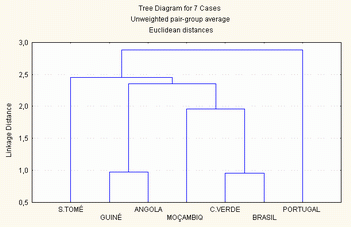
2.3.2.3 - Método da média do grupo (Unweighted pair-group average)
A distância entre duas classes a e b, é a média de todas as distâncias entre todos os elementos de a e todos os elementos de b. Devido à clareza do seu significado, este é o método de agrupamento mais utilizado nas taxonomias numéricas.
|
|
|
Amalgamation Schedule
Unweighted pair-group average
Euclidean distances
Passo Passo Passo Passo Passo Passo Passo
1 2 3 4 5 6 7
211,8709 Guiné Bi Moçambiq ,000 ,000 ,000 ,000 ,000
314,8911 São Tomé Angola ,000 ,000 ,000 ,000 ,000
1174,694 Cabo Ver São Tomé Angola ,000 ,000 ,000 ,000
1681,759 Cabo Ver São Tomé Angola Guiné Bi Moçambiq ,000 ,000
6422,576 Brasil Cabo Ver São Tomé Angola Guiné Bi Moçambiq ,000
11545,70 Portugal Brasil Cabo Ver São Tomé Angola Guiné Bi Moçambiq
Figura 7 - método da média do grupo (unweighted pair-group average)
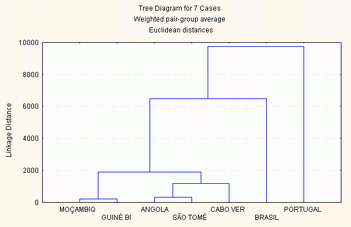
2.3.2.4 - Método da média simples (Weighted pair-group average)
A distância de um elemento i ao conjunto formado por dois grupos a e b, é a média simples das distâncias entre i e o grupo a e o grupo b.
|
|
|
Amalgamation Schedule
Weighted pair-group average
Euclidean distances
Passo Passo Passo Passo Passo Passo Passo
1 2 3 4 5 6 7
211,8709 Guiné Bi Moçambiq ,000 ,000 ,000 ,000 ,000
314,8911 São Tomé Angola ,000 ,000 ,000 ,000 ,000
1174,694 Cabo Ver São Tomé Angola ,000 ,000 ,000 ,000
1873,354 Cabo Ver São Tomé Angola Guiné Bi Moçambiq ,000 ,000
6494,823 Brasil Cabo Ver São Tomé Angola Guiné Bi Moçambiq ,000
9730,299 Portugal Brasil Cabo Ver São Tomé Angola Guiné Bi Moçambiq
Figura 8 - método da média simples (weighted pair-group average)
Embora ajude a preservar a individualidade dos pequenos grupos, a sequência de uniões deste tipo leva muitas vezes a grandes enviezamentos em benefício das últimas agregações efectuadas, desvalorizando grandes concentrações que se efectuaram em estádios iniciais do processo ascendente de agregação.
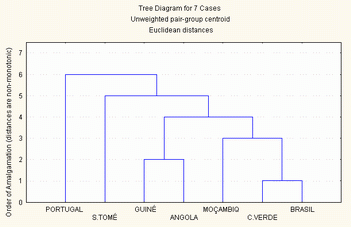
2.3.2.5 - Método do grupo centróide (Unweighted pair-group centroid)
A distância entre duas classes a e b, é a distância entre os centróides de a e de b. Os centróides são o centro de gravidade das classes, determinados pelas médias de cada variável.
A localização do centróide da nova classe resulta da média dos dois centróides ponderada pelo número de unidades de análise existentes em cada classe. É também um método de agrupamento muito utilizado.
Pode-se ver que, à medida que os grupos se tornam maiores, as distâncias entre os seus centroides aumenta e a fusão ocorre a níveis cada vez mais elevados.
|
|
|
Amalgamation Schedule
Unweighted pair-group centroid
Euclidean distances
Passo Passo Passo Passo Passo Passo Passo
1 2 3 4 5 6 7
211,8709 Guiné Bi Moçambiq ,000 ,000 ,000 ,000 ,000
314,8911 São Tomé Angola ,000 ,000 ,000 ,000 ,000
1095,971 Cabo Ver São Tomé Angola ,000 ,000 ,000 ,000
1332,760 Cabo Ver São Tomé Angola Guiné Bi Moçambiq ,000 ,000
5903,907 Brasil Cabo Ver São Tomé Angola Guiné Bi Moçambiq ,000
10293,49 Portugal Brasil Cabo Ver São Tomé Angola Guiné Bi Moçambiq
Figura 9 - método do grupo centroide (unweighted pair-group centroid)
2.3.2.6 - Método da mediana {Weighted pair-group centroid (median)}
A distância entre duas classes a e b, é a distância entre os centróides de a e de b, mas, no cálculo do centróide do novo grupo não se toma em consideração o número de elementos que existe em cada um, sendo as suas coordenadas a média simples das coordenadas dos centros dos dois grupos que se uniram.
Apresenta uma certa tendência para formar cadeias, embora menos forte do que o método do vizinho mais próximo.
|
|
|
Amalgamation Schedule
Weighted pair-group centroid (median)
Euclidean distances
Passo Passo Passo Passo Passo Passo Passo
1 2 3 4 5 6 7
211,8709 Guiné Bi Moçambiq ,000 ,000 ,000 ,000 ,000
314,8911 São Tomé Angola ,000 ,000 ,000 ,000 ,000
1095,971 Cabo Ver São Tomé Angola ,000 ,000 ,000 ,000
1507,032 Cabo Ver São Tomé Angola Guiné Bi Moçambiq ,000 ,000
5934,904 Brasil Cabo Ver São Tomé Angola Guiné Bi Moçambiq ,000
7966,613 Portugal Brasil Cabo Ver São Tomé Angola Guiné Bi Moçambiq
Figura 10 - método da mediana {weighted pair-group centroid (median)}
2.3.2.7 - Método de Ward ou da mínima variância
Baseia-se no pressuposto de que as classes devem ter a máxima homogeneidade interna possível. Ward propôs uma técnica de minimização da soma dos quadrados das distâncias de cada ponto ao respectivo centro de classe. Em cada nível, o novo grupo constitui-se pela combinação dos dois grupos cuja junção provoca o menor aumento da soma dos quadrados destas distâncias.
Desde que os indivíduos sejam pontos num espaço euclidiano, vimos que se definisse a qualidade de uma partição pela sua inércia intra-classe ou a sua inércia inter-classe. Uma boa partição é aquela pela qual a inércia inter-classe é forte (inércia intra-classe fraca). Desde que se passe duma partição em k+1 classes a uma partição em k classes agrupando duas classes numa só, veremos que a inércia inter-classe vai diminuir.
O critério de agrupamento será o seguinte: fundir as duas classes pelas quais a perda de inércia é a mais fraca. Tal leva a reunir as duas classes mais próximas tomando como distância entre duas classes a perda de inércia que as encurta aquando do agrupamento.
|
|
|
Amalgamation Schedule
Ward`s method
Euclidean distances
Passo Passo Passo Passo Passo Passo Passo
1 2 3 4 5 6 7
211,8709 Guiné Bi Moçambiq ,000 ,000 ,000 ,000 ,000
314,8911 São Tomé Angola ,000 ,000 ,000 ,000 ,000
1461,295 Cabo Ver São Tomé Angola ,000 ,000 ,000 ,000
3198,624 Cabo Ver São Tomé Angola Guiné Bi Moçambiq ,000 ,000
6923,011 Portugal Brasil ,000 ,000 ,000 ,000 ,000
20562,82 Portugal Brasil Cabo Ver São Tomé Angola Guiné Bi Moçambiq
Fifura 11 - método de Ward ou da mínima variância
A análise dos quadros e figuras põe em evidência a existência de duas classes relativamente homogéneas: Moçambique e Guiné, por um lado e, a curta distância, Angola e São Tomé, por outro.
Cabo Verde aparece numa situação intermédia entre estes dois grupos e o Brasil.
Portugal aparece sempre destacadamente a um nível muito superior.
Assim, no que respeita ao grau de desenvolvimento, propomos os seguintes agrupamentos:
I - Moçambique + Guiné
II - Angola + São Tomé
III - Cabo Verde
IV - Brasil
V - Portugal
2.3.3 - Classificação após redução das variáveis originais em componentes através da análise de componentes principais
De uma maneira geral, é recomendada confirmação dos resultados duma classificação pelo exame dos planos factoriais duma análise de componentes principais ou de uma análise das correspondências: os dois processos são complementares, a análise factorial permite, ainda, interpretar rapidamente em função das variáveis os agupamentos obtidos por uma classificação, como foi feito no Capítulo I.
Procedemos a vários tipos de classificação sobre o mesmo conjunto utilizando diversas fórmulas, de forma a conferir os resultados finais e tomarmos as decisões da forma mais informada possível.
Quando é utilizado um largo número de variáveis existem problemas maiores. Uma solução é o uso da análise de componentes principais de forma a reduzir o número de variáveis sem as excluir (Quadro XVII).
A substituição das variáveis pelos componentes significa que os indivíduos são enumerados pelos scores dos componentes e não directamente medidos por quantidades.
Quadro xvii - matriz de atributos (após análise de componentes principais)
COMPONENTE_1 COMPONENTE _2 COMPONENTE _3
Portugal 0,410 2,116 -0,056
Brasil 1,135 -0,035 0,702
C.Verde 0,366 -0,603 0,722
S.Tomé 1,140 -0,988 -1,104
Angola -1,047 -0,057 -1,310
Guiné -0,941 -0,009 -0,344
Moçamb -1,063 -0,424 1,389
Quadro xviii - matriz de distâncias euclideanas (inicial) após a redução de variáveis
Portugal Brasil C.Verde S.Tomé Angola Guiné Moçamb
Portugal 0,00 2,39 2,83 3,36 2,90 2,53 3,27
Brasil 2,39 0,00 0,96 2,04 2,97 2,33 2,33
C.Verde 2,83 0,96 0,00 2,02 2,53 1,79 1,59
S.Tomé 3,36 2,04 2,02 0,00 2,39 2,42 3,37
Angola 2,90 2,97 2,53 2,39 0,00 0,97 2,72
Guiné 2,53 2,33 1,79 2,42 0,97 0,00 1,79
Moçamb 3,27 2,33 1,59 3,37 2,72 1,79 0,00
Utilizando esta técnica, os resultados são ligeiramente diferentes, no entanto, Portugal aparece sempre nitidamente diferenciado dos outros países.
O Brasil surge sempre associado a Cabo Verde, e a Guiné tem semelhanças nítidas com Angola.
Ao contrário da técnica anterior, recorrendo à redução das variáveis originais em componentes principais, a distância a que se dá a junção dos países ou dos grupos de países é muito menor.
|
|
|
Amalgamation Schedule á Single Linkage
Euclidean distances
Passo 1 Passo 2 Passo 3 Passo 4 Passo 5 Passo 6 Passo 7
0,956494 Brasil C.Verde ,000 ,000 ,000 ,000 ,000
0,972869 Angola Guiné ,000 ,000 ,000 ,000 ,000
1,586538 Brasil C.Verde Moçambiq ,000 ,000 ,000 ,000
1,786473 Brasil C.Verde Moçambiq Angola Guiné ,000 ,000
2,019682 Brasil C.Verde Moçambiq Angola Guiné S.Tomé ,000
2,393213 Portugal Brasil C.Verde Moçambiq Angola Guiné S.Tomé
|
|
|
|
|
|
|
|
|
Figura 12 - classificação após redução das variáveis originais em componentes através da ACP
Beguin, H. - "Analyse quantitative", in Bailly, Antoine (Coord.) (1991) - Les Concepts de la Geographie Humaine, Paris, Masson, pp. 195-203.
Blalock, H. (1979) - Social Statistics, McGraw Hill, Tóquio.
Box, G. e Jenkins, G. (1976) - Time Series Analysis: forecasting and control, Holden-Day, San Francisco.
Bryman, A. e Cramer, D. (1993) - Análise de dados em Ciências Sociais: introdução às técnicas utilizando o SPSS. Celta, Oeiras.
Canto, C. et al (1988) - Trabajos Prácticos de Geografía Humana. Editorial Sintesis, Madrid. Pp. 22-29, 52-57, 140-147.
Chatfield, C. (1984) - The Analysis of Time Series. 3rd Ed., Chapman & Hall, London, UK.
Ciceri, M. F. et al (1977) - Introduction à l’analyse de l’espace. Masson, Paris.
Clark, W. e Hosking, P. (1986) - Statistical methods for geographers. John Wiley, New York.
Commissariat a l’énergie atomique (1978) - Statistique Appliqué a l’Exploitation des Mesures. Tome 1. Masson, Paris. ISBN 2-225-49225-5
Commissariat a l’énergie atomique (1978) - Statistique Appliqué a l’Exploitation des Mesures. Tome 2. Masson, Paris. ISBN 2-225-49236-0
D’hainaut, L. (1992) - Conceitos e métodos da estatística, vol. II á duas ou três variáveis segundo duas ou três dimensões. Fundação Calouste Gulbenkian, Lisboa.
Ebdon, D. (1996) - Statistics in Geography. Blackwell, Oxford (UK).
Elzey, F.F. (1974) - A First Reader in Statistics. Brooks/Cole Publishing Company, Pacific Grove, California, USA.
Estebanez, J. e Bradshaw, R. (1979) - Técnicas de Quantificacion en Geografía. Editorial Tebar Flores, Madrid.
Freund, J.E. & Simon, G.A. (1995) - Statistics. Prentice Hall, Englewood Cliffs, New Jersey.
Gerardi, Lucia; Silva, Barbara-Chistine (1981) - Quantificação em Geografia, Difel, São-Paulo, pp. 11-29.
Groupe Chadule (1987) - Initiation aux Pratiques Statistiques en Géographie. Masson, Paris.
Guillemot, H. (1995) - "O que escondem as sondagens?", Notícias Magazine, 26-02-1995. Pp. 17-23.
Hair, J.F. et al (1995) - Multivariate Data Analysis. 4th Ed., Prentice Hall, New Jersey, USA.
Healey, J.F. (1996) - Statistics: a Tool for Social Research. 4th Ed., Wadsworth Publishing Company, Belmont, California, USA. ISBN 0-534-25152-8
Kendall, M. (1976) - Time-Series. Charles Griffin & Company Ltd., London.
Lindsay, J. (1997) - Techniques in Human Geography, Routledge, London.
Moroney, M.J. (1969) - Dos Números aos Factos. Edições Despertar, Porto.
Morrison, d.f. (1990) - Multivariate Statistical Methods. 3rd Ed., McGraw-Hill International Editions, Singapore. ISBN 0-07-100815-2
Murteira, B.J.F. (1979) - Probabilidades e Estatística. vol I, Ed. McGraw-Hill de Portugal, Lda., Lisboa.
Murteira, B.J.F. (1990) - Probabilidades e Estatística. vol II, Ed. McGraw-Hill de Portugal, Lda., Lisboa.
Parikh, A. e Bailey, D. (1990) - Techniques of Economic Analysis with Applications. Harvester Wheathsheaft, New York, p. 1-166.
Pestana, M.E. e Gageiro, J.N. (1998) - Análise de dados para Ciências Sociais. A complementaridade do SPSS. Edições Sílabo, Lisboa.
PNUD (1998) - Relatório do Desenvolvimento Humano 1998, Trinova Editora, Lisboa.
Reis, E. (1997) - Estatística Aplicada. vol. I, Edições Sílabo, Lisboa.
Reis, E. (1997) - Estatística Aplicada. vol. II, Edições Sílabo, Lisboa.
reis, e. (1997) - Estatística Multivariada Aplicada. Edições Sílabo, Lisboa.
Santos Preciado, J.M. e Muguruza Cañas, C. (1984) - "Microordenadores y Análisis Estadística en Geografía", in Bosque Sendra, J. et al (eds.) - Aplicaciones de la Informática a la Geografía y Ciências Sociales. Editorial Sintesis, Madrid.
Schleifer, A. & Bell, D.E. (1994) - Data Analysis, Regression and Forecasting. Course Technology, Cambridge, USA.
Spiegel, M.R. (1994) - Estatística. 3.ª Ed., Makron Books e McGraw-Will, São Paulo.
Tacq, j. (1997) - Multivariate Analysis Techniques in Social Science Research. Sage Publications, London. ISBN 0-7619-5272-1
The Economist (1993) - Guia dos números. Caminho, Lisboa, pp. 95-111.
Vialar, J. (1977) - Calcul des Probabilités et Statistique á tome I: éléments de calcul des probabilités. Secrétariat d’État auprès du Ministre de l’Équipement, France.
Vialar, J. (1977) - Calcul des Probabilités et Statistique á tome II: Statistique: étude des échantillons. Secrétariat d’État auprès du Ministre de l’Équipement, France.
Vialar, J. (1977) - Calcul des Probabilités et Statistique á tome III: Statistique: contingence et corrélation. Secrétariat d’État auprès du Ministre de l’Équipement, France.
Vialar, J. (1978) - Calcul des Probabilités et Statistique á tome IV: Statistique: étude des séries cronologiques. Secrétariat d’État auprès du Ministre de l’Équipement, France.
Volle, M. (1978) - Analyse des Données. Economica, Paris.
Yeomans, K.A. (1977) - Statistics for the Social Scientist: 1 - Introducing Statistics. Penguin Books, Harmondsworth.
Yeomans, K.A. (1977) - Statistics for the Social Scientist: 2 - Applied Statistics. Penguin Books, Harmondsworth.
(vários) (1984) - Spatial Statistics and Models. D. Reidel Publishing Company, USA.
Internet:
<http://www.un.org.mx/pnud>
<http://www.undp.org/>
<http://www.undp.org/hdro/report.html>
<http://www.undp.org/eo/fe96c1.html>
<http://www.undp.org.br/HDR/HDR99.html>
<http://www.undp.org/hdro/index2.html>
<http://www.undp.org/hdro/kit.html>
<http://www.undp.org/hdro/authors.html>
<http://www.undp.org/hdro/contents.html>
<http://www.undp.org/hdro/front.pdf>
<http://www.undp.org/hdro/overview.pdf>
<http://www.undp.org/hdro/10year.html>
<http://www.undp.org/hdro/front.pdf>)
<http://www.undp.org/hdro/Chapter1.pdf>
<http://www.undp.org/hdro/Chapter2.pdf>
<http://www.undp.org/hdro/Chapter3.pdf>
<http://www.undp.org/hdro/Chapter4.pdf>
<http://www.undp.org/hdro/Chapter5.pdf>
<http://www.undp.org/hdro/Backmatter1.pdf>
<http://www.undp.org/hdro/HDI.html>
<http://www.undp.org/hdro/Backmatter2.pdf>
<http://www.undp.org/hdro/hdrolife.html>
<http://www.undp.org/hdro/reviews.html>
<http://www.undp.org/hdro/ordering.html>
<http://stone.undp.org/undpweb/hdr/>
<http://www.undp.org/hdr2000/french/HDR2000.html>
Programas informáticos de Tratamento de Dados:
Dados do Autor:
José Alberto Afonso Alexandre
jaaalexandre[arroba]hotmail.com
Mestre em Inovação e Políticas de Desenvolvimento (Universidade de Aveiro)
Licenciado em Geografia (Universidade de Coimbra)
Publicação em «monografias.com» de:
«O planeamento estratégico como instrumento de desenvolvimento de cidades de média dimensão», (https://www.monografias.com/pt/trabalhos/planeamento-cidades/planeamento-cidades.shtml);
«Rumo à sustentabilidade: o planeamento urbano participativo», (https://www.monografias.com/pt/trabalhos2/sustentabilidade-urbana/sustentabilidade-urbana.shtml);
O turismo em Portugal: evolução e distribuição, (https://www.monografias.com/pt/trabalhos2/turismo-portugal/turismo-portugal.shtml).
>| Página anterior | Voltar ao início do trabalho | Página seguinte |
|
|
|





 ESTRUTURA
DE LIGAÇÃO
ESTRUTURA
DE LIGAÇÃO